Масштабирование базы данных через шардирование и партиционирование
Денис Иванов (2ГИС)

Всем привет! Меня зовут Денис Иванов, и я расскажу о масштабировании баз данных через шардирование и партиционирование. После этого доклада у всех должно появиться желание что-то попартицировать, пошардировать, вы поймете, что это очень просто, оно никак жрать не просит, работает, и все замечательно.
Немного расскажу о себе – я работаю в компании WebAPI в 2GIS-е, мы предоставляем API для организаций, у нас очень много разных данных, 8 стран, в которых мы работаем, 250 крупных городов, 50 тыс. населенных пунктов. У нас достаточно большая нагрузка – 25 млн. активных пользователей в месяц, и в среднем нагрузка около 2000 RPS идет на API. Все это располагается в трех датацентрах.
Перейдем к проблемам, которые мы с вами сегодня будем решать. Одна из проблем – это большое количество данных. Когда вы разрабатываете тот или иной проект, у вас в любой момент времени может случиться так, что данных становится очень много. Если бизнес работает, он приносит деньги. Соответственно, данных больше, денег больше, и с этими данными что-то нужно делать, потому что эти запросы очень долго начинают выполняться, и у нас сервер начинает не вывозить. Одно из решений, что с этими данными делать – это масштабирование базы данных.
Я в большей степени расскажу про шардинг. Он бывает вертикальным и горизонтальным. Также бывает такой способ масштабирования как репликация. Доклад "Как устроена MySQL репликация" Андрея Аксенова из Sphinx про это и был. Я эту тему практически не буду освещать.
Перейдем подробнее к теме партицирования (вертикальный шардинг). Как это все выглядит?
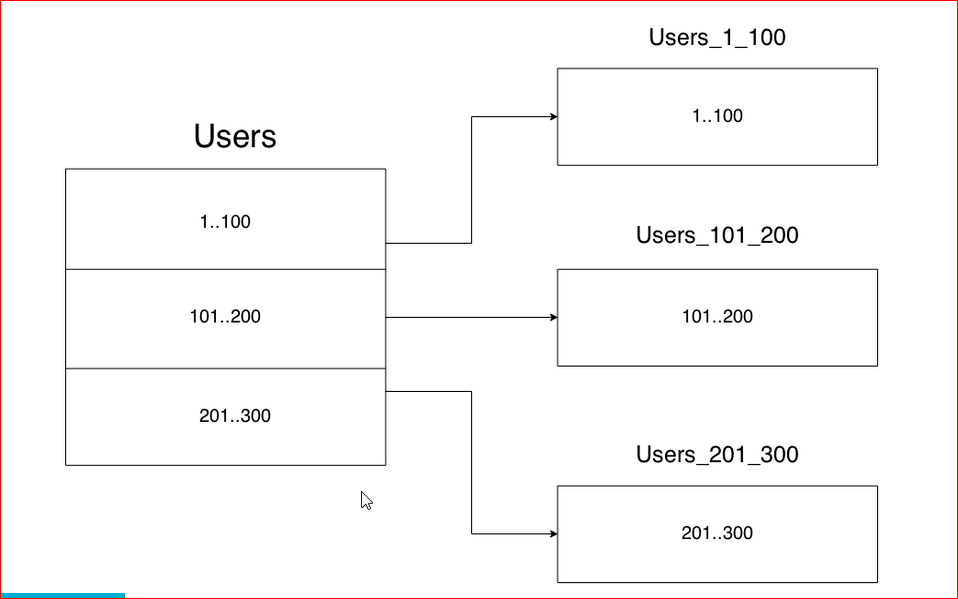
У нас есть большая таблица, например, с пользователями – у нас очень много пользователей. Партицирование – это когда мы одну большую таблицу разделяем на много маленьких по какому-либо принципу.
С горизонтальным шардингом все примерно так же, но при этом у нас таблички лежат в разных базах на других инстансах.
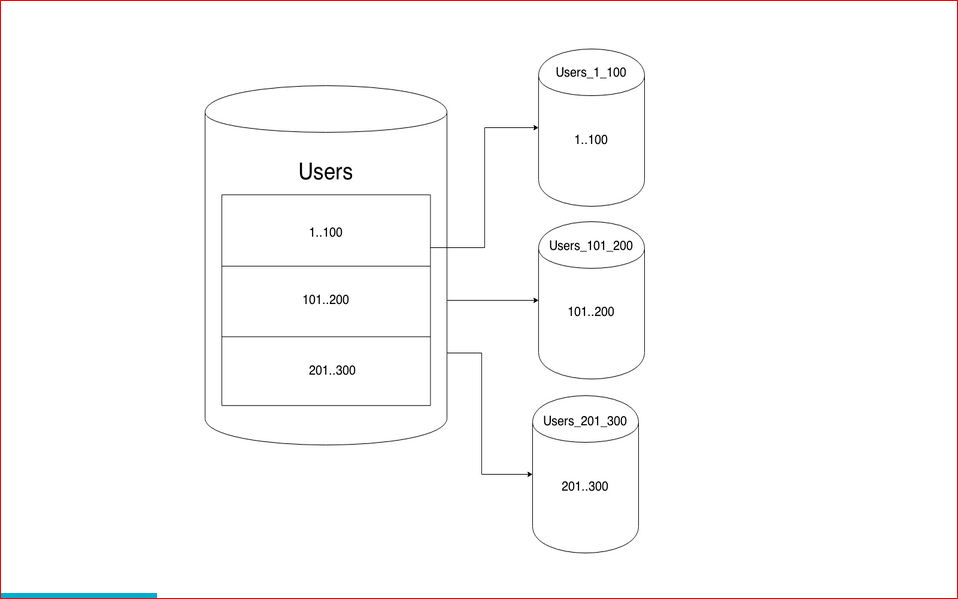
Единственное отличие горизонтального масштабирования от вертикального в том, что горизонтальное масштабирование будет разносить данные по разным инстансам.
Про репликацию я не буду останавливаться, тут все очень просто.
Перейдем глубже к этой теме, и я расскажу практически все о партицировании на примере Postgres’а.
Давайте рассмотрим простую табличку, наверняка, практически в 99% проектов такая табличка есть – это новости.
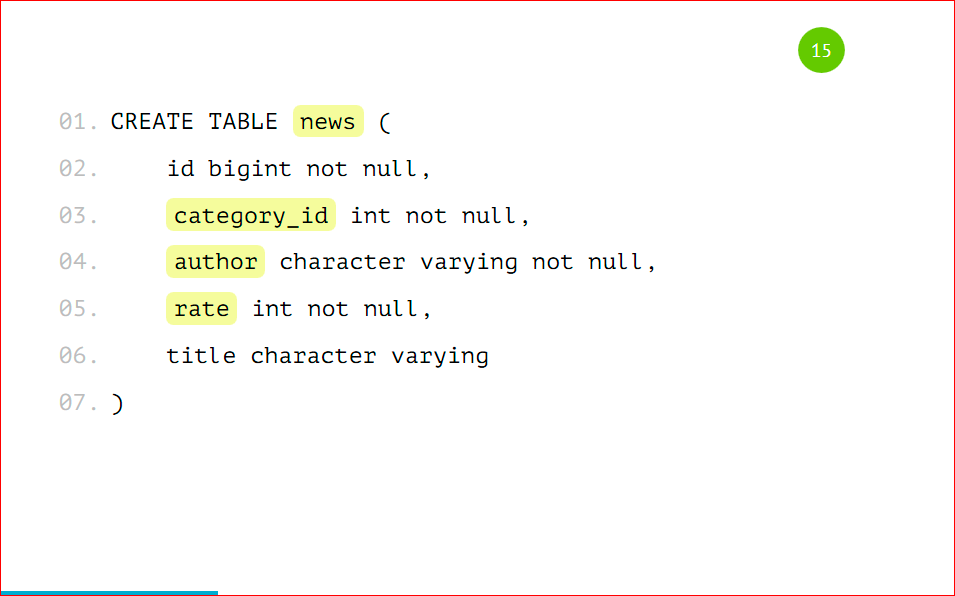
У новости есть идентификатор, есть категория, в которой эта новость расположена, есть автор новости, ее рейтинг и какой-то заголовок – совершенно стандартная таблица, ничего сложного нет.
Как же эту таблицу разделить на несколько? С чего начать?
Всего нужно будет сделать 2 действия над табличкой – это поставить у нашего шарда, например, news_1, то, что она будет наследоваться таблицей news. News будет базовой таблицей, будет содержать всю структуру, и мы, создавая партицию, будем указывать, что она наследуется нашей базовой таблицей. Наследованная таблица будет иметь все колонки родителя – той базовой таблицы, которую мы указали, а также она может иметь свои колонки, которые мы дополнительно туда добавим. Она будет полноценной таблицей, но унаследованной от родителя, и там не будет ограничений, индексов и триггеров от родителя – это очень важно. Если вы на базовой таблице насоздаете индексы и унаследуете ее, то в унаследованной таблице индексов, ограничений и триггеров не будет.
2-ое действие, которое нужно сделать – это поставить ограничения. Это будет проверка, что в эту таблицу будут попадать данные только вот с таким признаком.

В данном случае признак – это category_id=1, т.е. только записи с category_id=1 будут попадать в эту таблицу.
Какие типы проверок бывают для партицированных таблиц?

Бывает строгое значение, т.е. у нас какое-то поле четко равно какому-то полю. Бывает список значений – это вхождение в список, например, у нас может быть 3 автора новости именно в этой партиции, и бывает диапазон значений – это от какого и до какого значения данные будут храниться.
Тут нужно подробнее остановиться, потому что проверка поддерживает оператор BETWEEN, наверняка вы все его знаете.
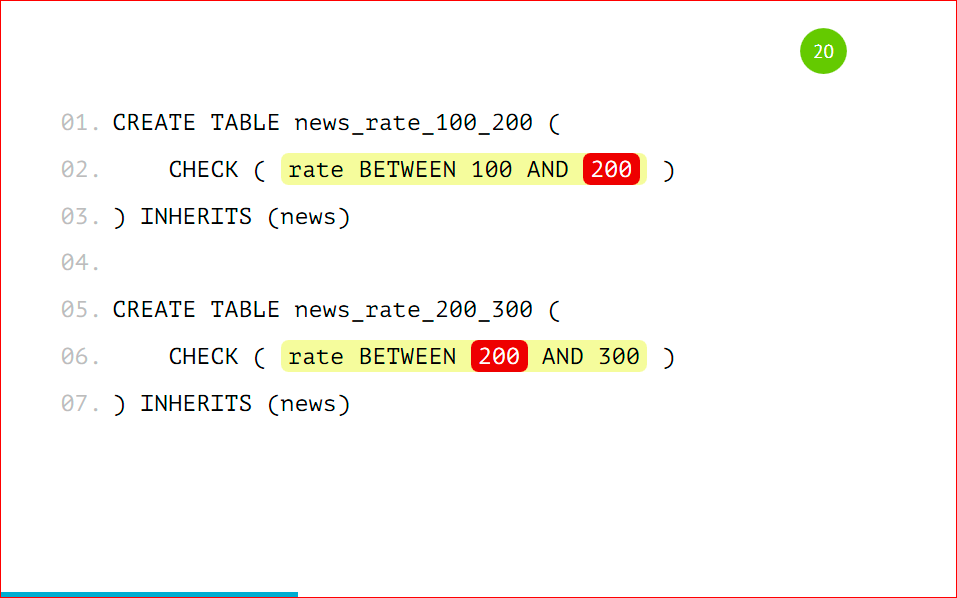
И так просто его сделать можно. Но нельзя.
Можно сделать, потому что нам разрешат такое сделать, PostgreSQL поддерживает такое.
Как вы видите, у нас в 1-ую партицию попадают данные между 100 и 200, а во 2-ую – между 200 и 300.
В какую из этих партиций попадет запись с рейтингом 200? Не известно, как повезет.
Поэтому так делать нельзя, нужно указывать строгое значение, т.е. строго в 1-ую партицию будут попадать значения больше 100 и меньше либо равно 200, и во вторую больше 200, но не 200, и меньше либо равно 300.
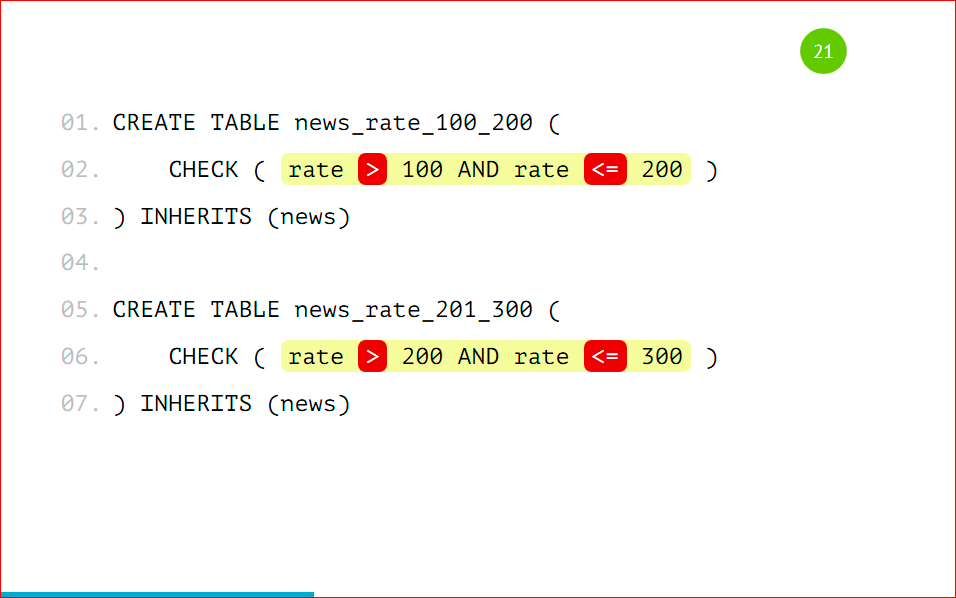
Это обязательно нужно запомнить и так не делать, потому что вы не узнаете, в какую из партиций данные попадут. Нужно четко прописывать все условия проверки.
Также не стоит создавать партиции по разным полям, т.е. что в 1-ую партицию у нас будут попадать записи с category_id=1, а во 2-ую – с рейтингом 100.
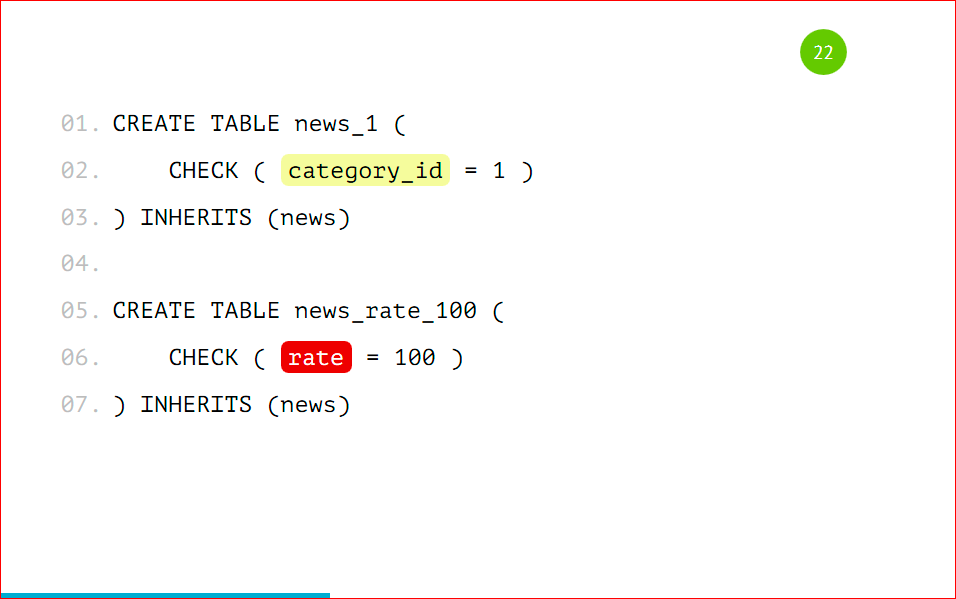
Опять же, если нам придет такая запись, в которой category_id = 1 и рейтинг =100, то неизвестно в какую из партиций попадет эта запись. Партицировать стоит по одному признаку, по какому-то одному полю – это очень важно.
Давайте рассмотрим нашу партицию целиком:
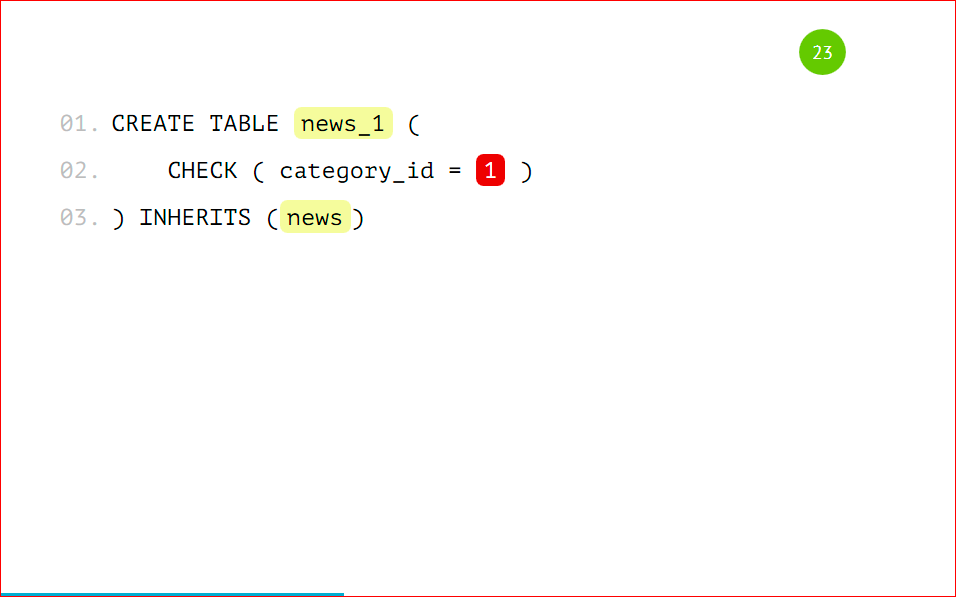
Ваша партицированная таблица будет выглядеть вот так, т.е. это таблица news_1 с признаком, что туда будут попадать записи только с category_id = 1, и эта таблица будет унаследована от базовой таблицы news – все очень просто.
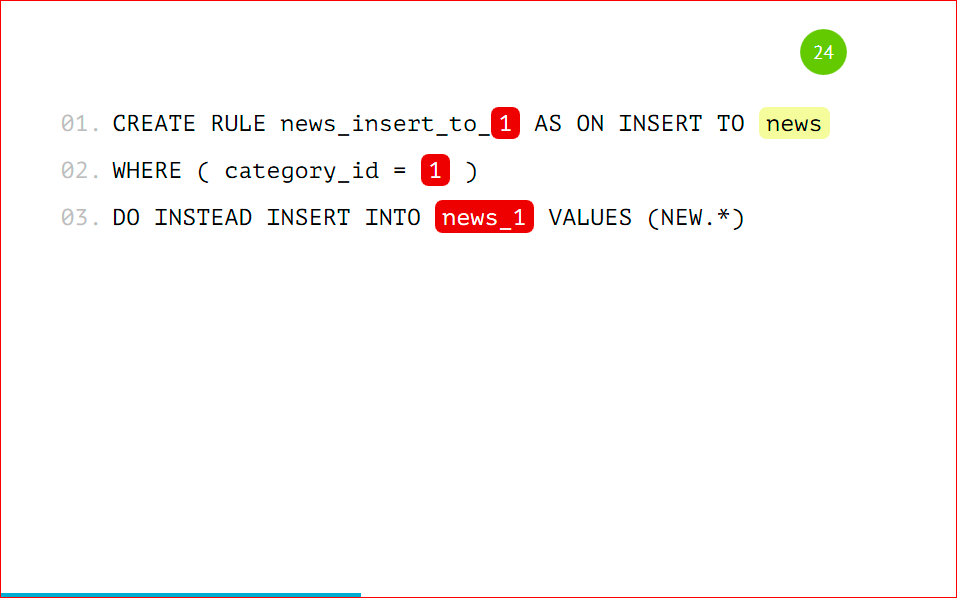
Мы на базовую таблицу должны добавить некоторое правило, чтобы, когда мы будем работать с нашей основной таблицей news, вставка на запись с category_id = 1 попала именно в ту партицию, а не в основную. Мы указываем простое правило, называем его как хотим, говорим, что когда данные будут вставляться в news с category_id = 1, вместо этого будем вставлять данные в news_1. Тут тоже все очень просто: по шаблончику оно все меняется и будет замечательно работать. Это правило создается на базовой таблице.
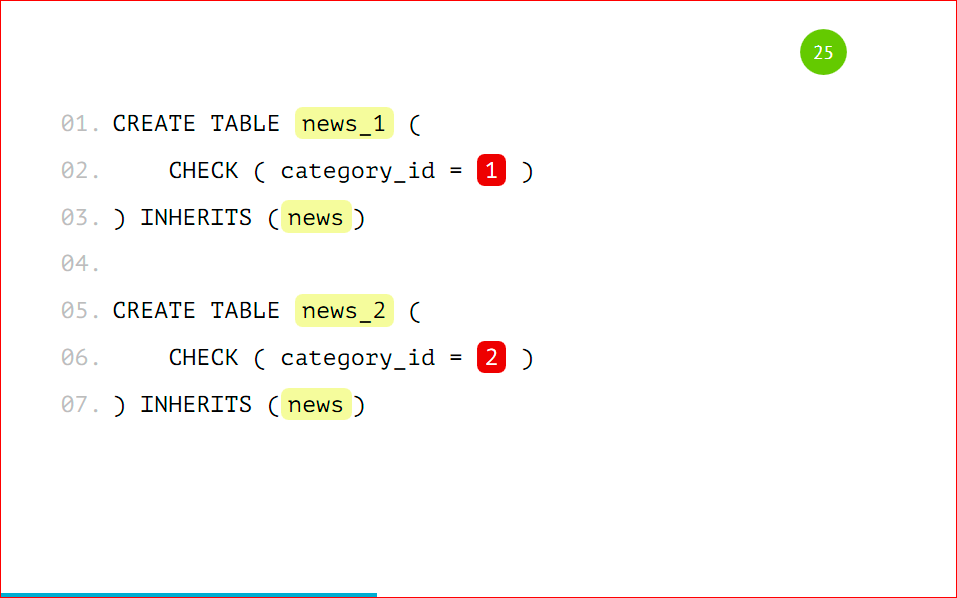
Таким образом мы заводим нужное нам количество партиций.
Для примера я буду использовать 2 партиции, чтобы было проще. Т.е. у нас все одинаково, кроме наименований этой таблицы и условия, по которому данные будут туда попадать. Мы также заводим соответствующие правила по шаблону на каждую из таблиц.
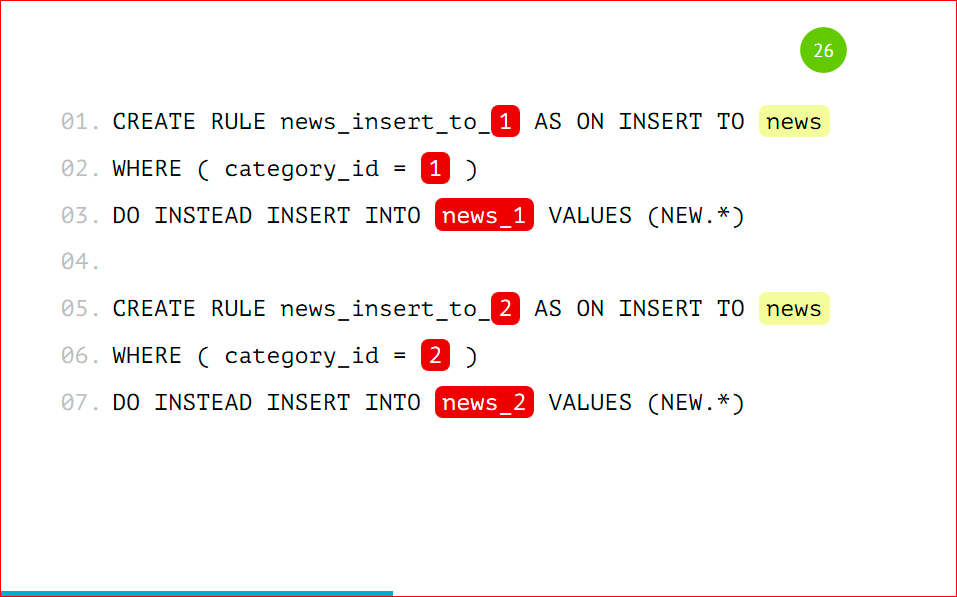
Давайте рассмотрим пример вставки данных:

Данные будем вставлять как обычно, будто у нас обычная большая толстая таблица, т.е. мы вставляем запись с category_id=1 с category_id=2, можем даже вставить данные с category_id=3.

Вот мы выбираем данные, у нас они все есть.
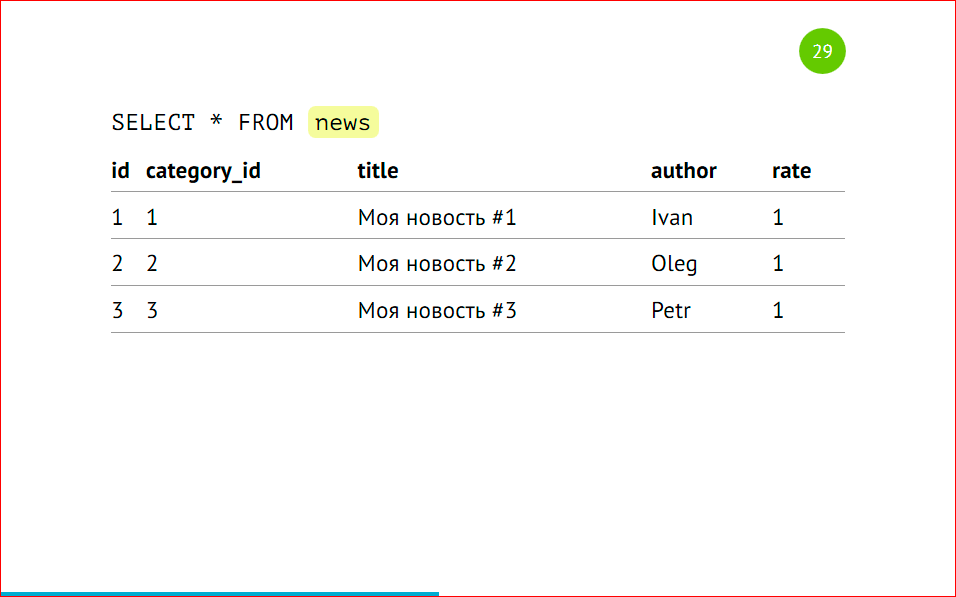
Все, которые мы вставляли, несмотря на то, что 3-ей партиции у нас нет, но данные есть. В этом, может быть, есть немного магии, но на самом деле нет.
Мы также можем сделать соответствующие запросы в определенные партиции, указывая наше условие, т.е.category_id = 1, или вхождение в числа (2, 3).
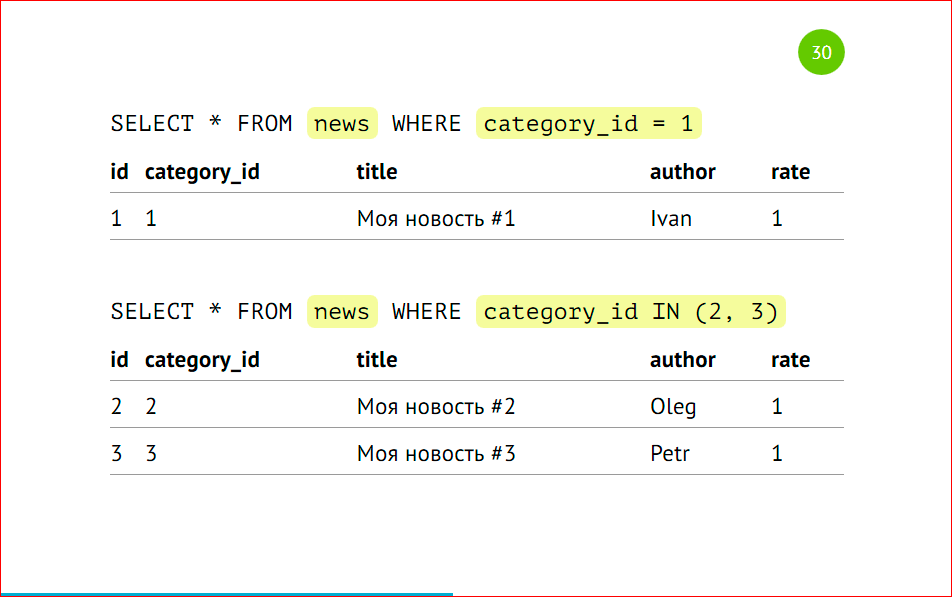
Все будет замечательно работать, все данные будут выбираться. Опять же, несмотря на то, что с партиции с category_id=3 у нас нет.
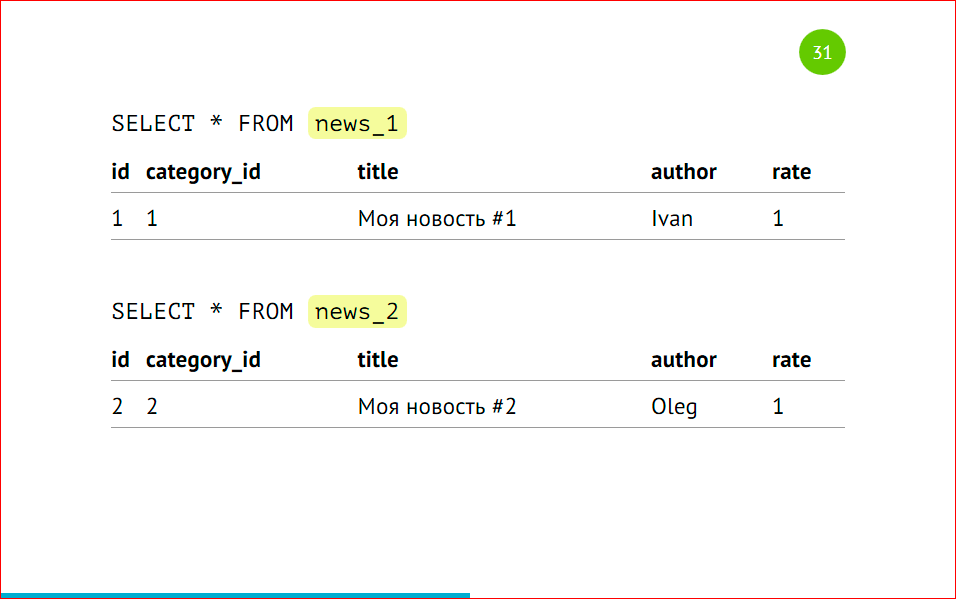
Мы можем выбирать данные напрямую из партиций – это будет то же самое, что в предыдущем примере, но мы четко указываем нужную нам партицию. Когда у нас стоит точное условие на то, что нам именно из этой партиции нужно выбрать данные, мы можем напрямую указать именно эту партицию и не ходить в другие. Но у нас нет 3-ей партиции, а данные попадут в основную таблицу.
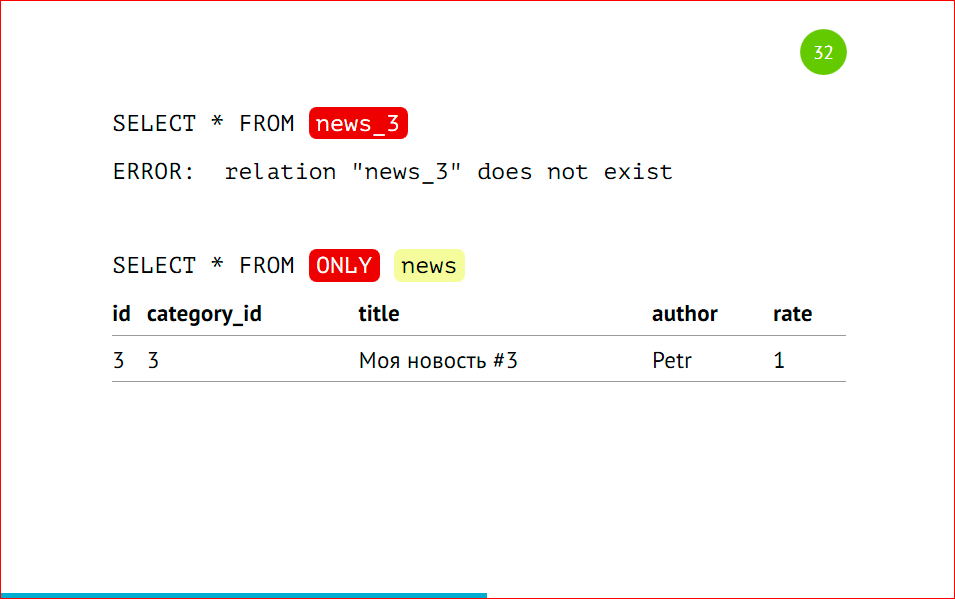
Хоть у нас и применено партицирование к этой таблице, основная таблица все равно существует. Она настоящая таблица, она может хранить данные, и с помощью оператора ONLY можно выбрать данные только из этой таблицы, и мы можем найти, что эта запись здесь спряталась.

Здесь можно, как видно на слайде, вставлять данные напрямую в партицию. Можно вставлять данные с помощью правил в основную таблицу, но можно и в саму партицию.

Если мы будем вставлять данные в партицию с каким-то чужеродным условием, например, с category_id = 4, то мы получим ошибку «сюда такие данные нельзя вставлять» – это тоже очень удобно – мы просто будем класть данные только в те партиции, которые нам действительно нужно, и если у нас что-то пойдет не так, мы на уровне базы все это отловим.

Тут пример побольше. Можно bulk_insert использовать, т.е. вставлять несколько записей одновременно и они все сами распределятся с помощью правил нужной партиции. Т.е. мы можем вообще не заморачиваться, просто работать с нашей таблицей, как мы раньше и работали. Приложение продолжит работать, но при этом данные будут попадать в партиции, все это будет красиво разложено по полочкам без нашего участия.
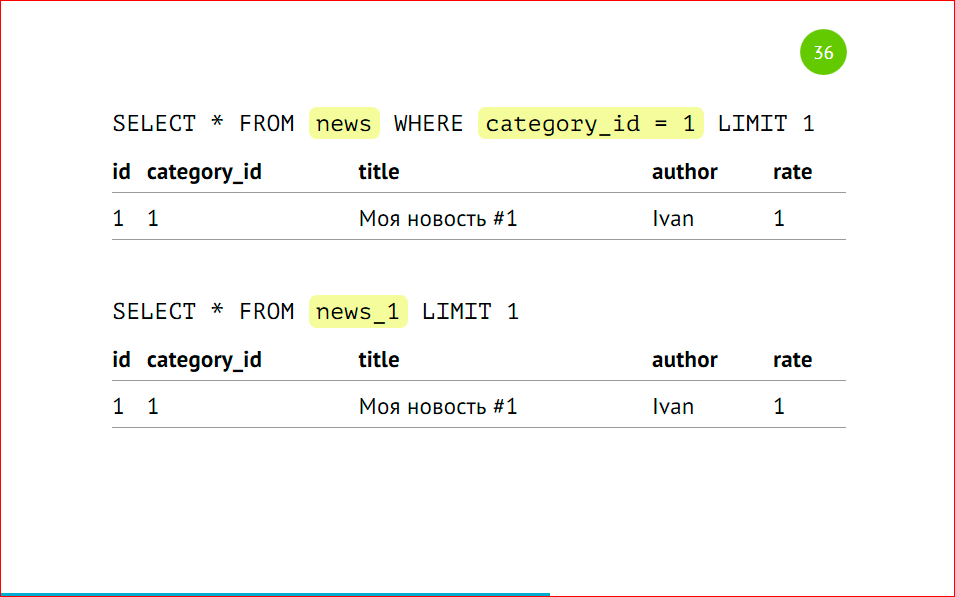
Напомню, что мы можем выбирать данные как из основной таблицы с указанием условия, можем, не указывая это условие выбирать данные из партиции. Как это выглядит со стороны explain’а:
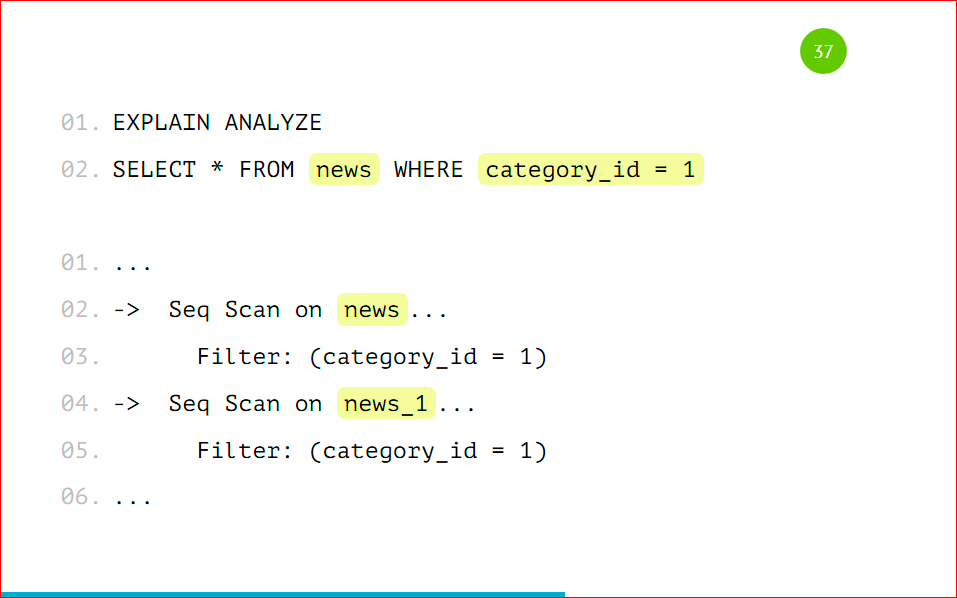
У нас будет Seq Scan по всей таблице целиком, потому что туда данные могут все равно попадать, и будет скан по партиции. Если мы будем указывать условия нескольких категорий, то он будет сканировать только те таблицы, на которые есть условия. Он не будет смотреть в остальные партиции. Так работает оптимизатор – это правильно, и так действительно быстрее.
Мы можем посмотреть, как будет выглядеть explain на самой партиции.
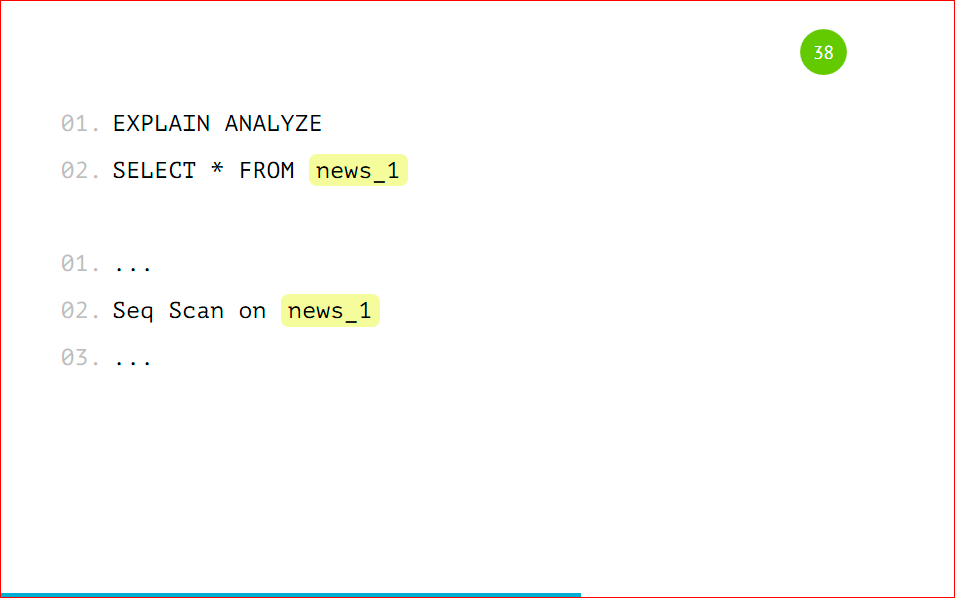
Это будет обычная таблица, просто Seq Scan по ней, ничего сверхъестественного.
Точно так же будут работать update’ы и delete’ы. Мы можем update’тить основную таблицу, можем также update’ы слать напрямую в партиции. Так же и delete’ы будут работать. На них нужно так же соответствующие правила создать, как мы создавали с insert’ом, только вместо insert написать update или delete.
Перейдем к такой вещи как Index’ы.

Индексы, созданные на основной таблице, не будут унаследованы в дочерней таблице нашей партиции. Это грустно, но придется заводить одинаковые индексы на всех партициях. С этим есть что поделать, но придется заводить все индексы, все ограничения, все триггеры дублировать на все таблицы.
Как мы с этой проблемой боролись у себя. Мы создали замечательную утилиту PartitionMagic, которая позволяет автоматически управлять партициями и не заморачиваться с созданием индексов, триггеров с несуществующими партициями, с какими-то бяками, которые могут происходить. Эта утилита open source’ная, ниже будет ссылка. Мы эту утилиту в виде хранимой процедуры добавляем к нам в базу, она там лежит, не требует дополнительных extension'ов, никаких расширений, ничего пересобирать не нужно, т.е. мы берем PostgreSQL, обычную процедуру, запихиваем в базу и с ней работаем.
Вот та же самая таблица, которую мы рассматривали, ничего нового, все то же самое.

Как же нам запартицировать ее? А просто вот так:
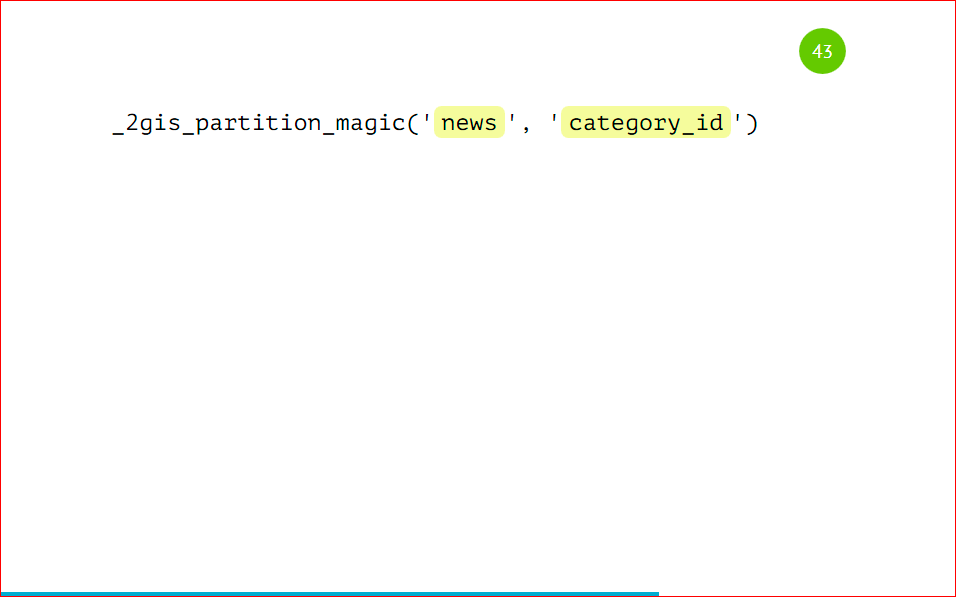
Мы вызываем процедуру, указываем, что таблица будет news, и партицировать будем по category_id. И все дальше будет само работать, нам больше ничего не нужно делать. Мы так же вставляем данные.
У нас тут три записи с category_id =1, две записи с category_id=2, и одна с category_id=3.

После вставки данные автоматически попадут в нужные партиции, мы можем сделать селекты.
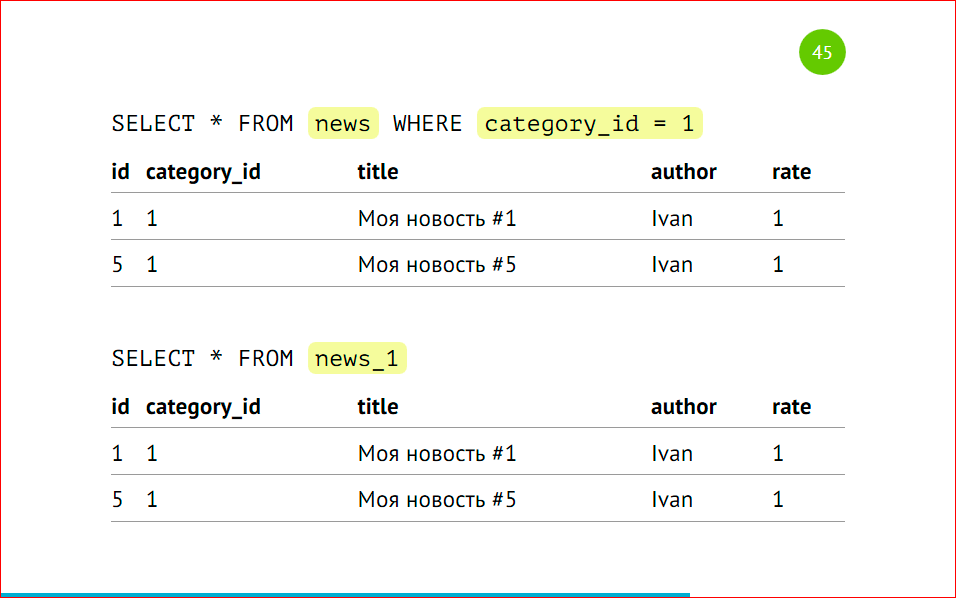
Все, партиции уже создались, все данные разложились по полочкам, все замечательно работает.
Какие мы получаем за счет этого преимущества:
· при вставке мы автоматически создаем партицию, если ее еще нет;
· поддерживаем актуальную структуру, можем управлять просто базовой таблицей, навешивая на нее индексы, проверки, триггеры, добавлять колонки, и они автоматически будут попадать во все партиции после вызова этой процедуры еще раз.
Мы получаем действительно большое преимущество в этом. Вот ссылочка: https://github.com/2gis/partition_magic.
На этом первая часть доклада закончена. Мы научились партицировать данные. Напомню, что партицирование применяется на одном инстансе – это тот же самый инстанс базы, где у вас лежала бы большая толстая таблица, но мы ее раздробили на мелкие части. Мы можем совершенно не менять наше приложение – оно точно так же будет работать с основной таблицей – вставляем туда данные, редактируем, удаляем. Так же все работает, но работает быстрее. Приблизительно, в среднем, в 3-4 раза быстрее.
Перейдем ко второй части доклада – это горизонтальный шардинг.
Напомню, что горизонтальный шардинг – это когда мы данные разносим по нескольким серверам. Все это делается тоже достаточно просто, стоит один раз это настроить, и оно будет работать замечательно. Я расскажу подробнее, как это можно сделать.
Рассматривать будем такую же структуру с двумя шардами – news_1 и news_2, но это будут разные инстансы, третьим инстансом будет основная база, с которой мы будем работать:
Та же самая таблица:
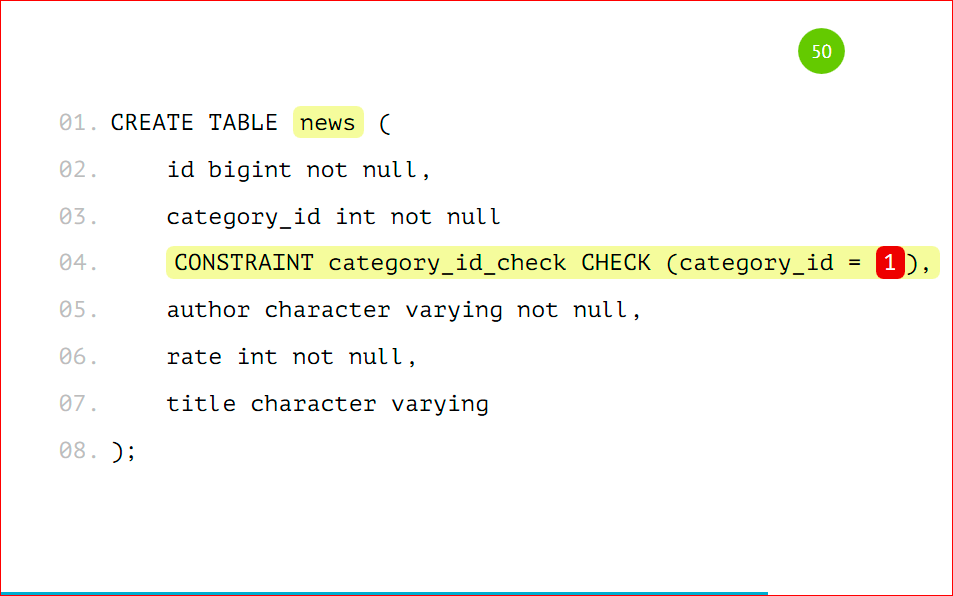
Единственное, что туда нужно добавить, это CONSTRAINT CHECK, того, что записи будут выпадать только с category_id=1. Так же, как в предыдущем примере, но это не унаследованная таблица, это будет таблица с шардом, которую мы делаем на сервере, который будет выступать шардом с category_id=1. Это нужно запомнить. Единственное, что нужно сделать – это добавить CONSTRAINT.
Мы еще можем дополнительно создать индекс по category_id:
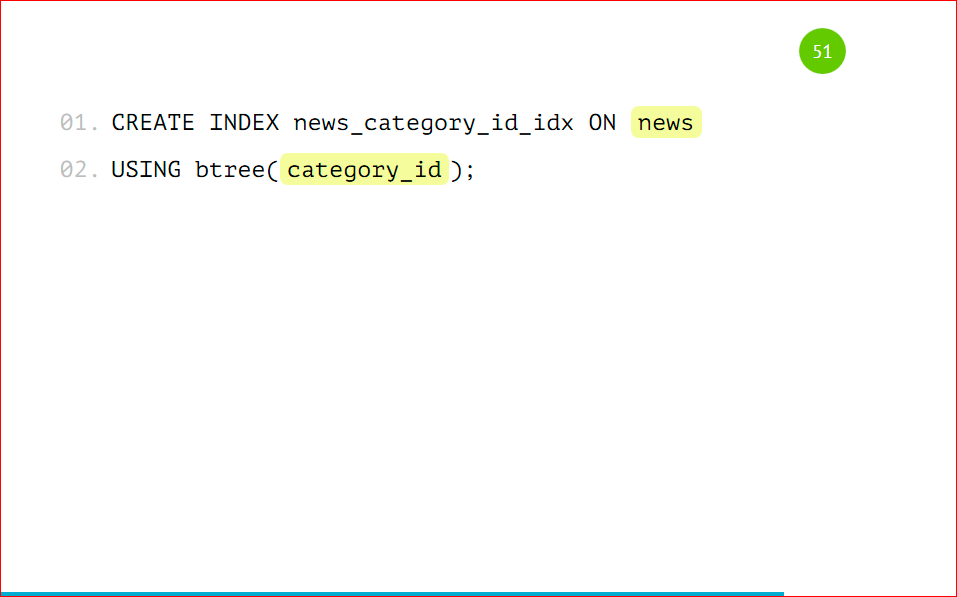
Несмотря на то, что у нас стоит check – проверка, PostgreSQL все равно обращается в этот шард, и шард может очень надолго задуматься, потому что данных может быть очень много, а в случае с индексом он быстро ответит, потому что в индексе ничего нет по такому запросу, поэтому его лучше добавить.
Как настроить шардинг на основном сервере?
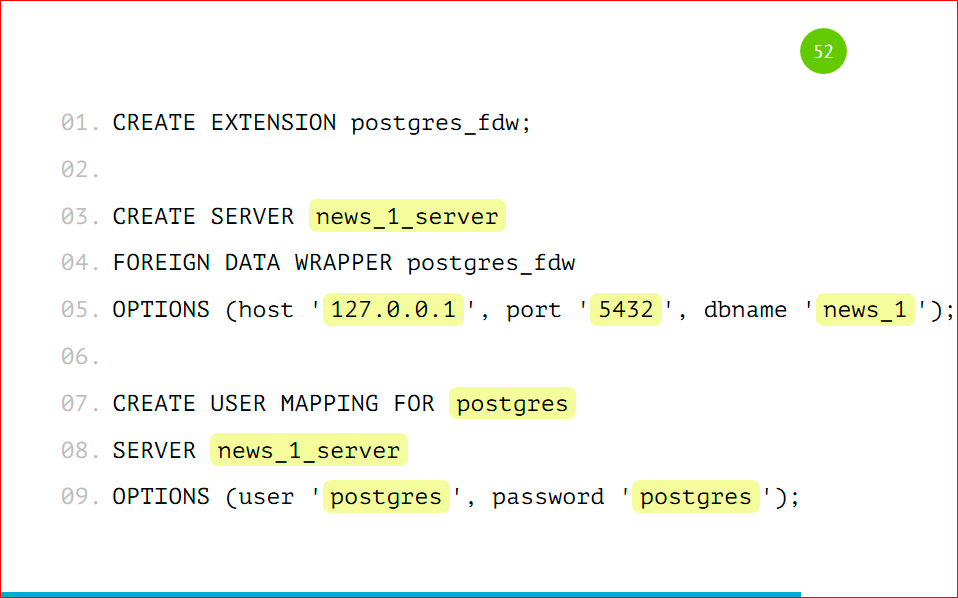
Мы подключаем EXTENSION. EXTENSION идет в Postgres’e из коробки, делается это командой CREATE EXTENSION, называется он postgres_fdw, расшифровывается как foreign data wrapper.
Далее нам нужно завести удаленный сервер, подключить его к основному, мы называем его как угодно, указываем, что этот сервер будет использовать foreign data wrapper, который мы указали.
Таким же образом можно использовать для шарда MySql, Oracle, Mongo… Foreign data wrapper есть для очень многих баз данных, т.е. можно отдельные шарды хранить в разных базах.
В опции мы добавляем хост, порт и имя базы, с которой будем работать, нужно просто указать адрес вашего сервера, порт (скорее всего, он будет стандартный) и базу, которую мы завели.
Далее мы создаем маппинг для пользователя – по этим данным основной сервер будет авторизироваться к дочернему. Мы указываем, что для сервера news_1 будет пользователь postgres, с паролем postgres. И на основную базу данных он будет маппиться как наш user postgres.
Я все со стандартными настройками показал, у вас могут быть свои пользователи для проектов заведены, для отдельных баз, здесь нужно именно их будет указать, чтобы все работало.
Далее мы заводим табличку на основном сервере

Это будет табличка с такой же структурой, но единственное, что будет отличаться – это префикс того, что это будет foreign table, т.е. она какая-то иностранная для нас, отдаленная, и мы указываем, с какого сервера она будет взята, и в опциях указываем схему и имя таблицы, которую нам нужно взять.
Схема по дефолту – это public, таблицу, которую мы завели, назвали news. Точно так же мы подключаем 2-ую таблицу к основному серверу, т.е. добавляем сервер, добавляем маппинг, создаем таблицу. Все, что осталось – это завести нашу основную таблицу.

Это делается с помощью VIEW, через представление, мы с помощью UNION ALL склеиваем запросы из удаленных таблиц и получаем одну большую толстую таблицу news из удаленных серверов.
Также мы можем добавить правила на эту таблицу при вставке, удалении, чтобы работать с основной таблицей вместо шардов, чтобы нам было удобнее – никаких переписываний, ничего в приложении не делать.
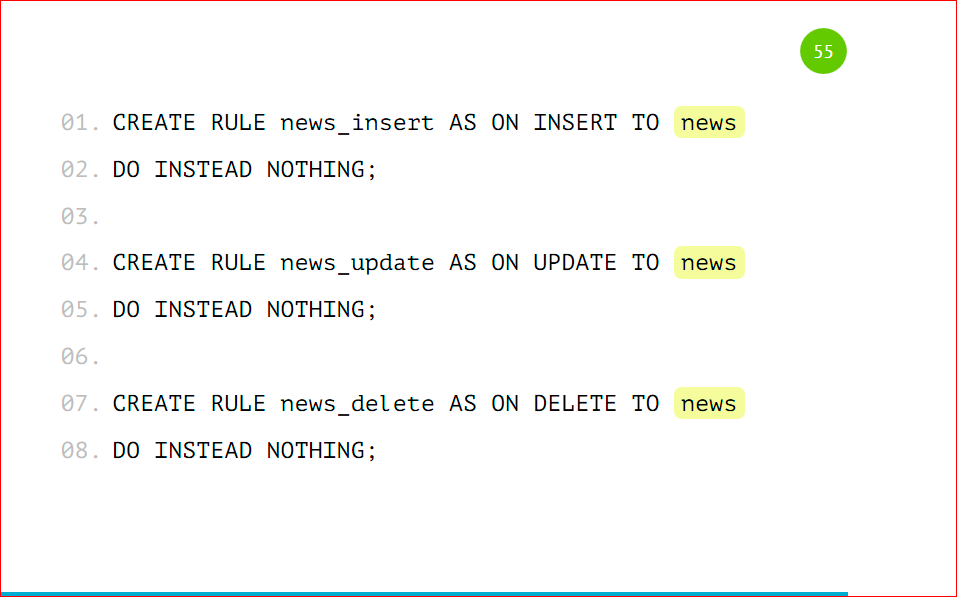
Мы заводим основное правило, которое будет срабатывать, если ни одна проверка не сработала, чтобы не происходило ничего. Т.е. мы указываем DO INSTEAD NOTHING и заводим такие же проверки, как мы делали ранее, но только с указанием нашего условия, т.е. category_id=1 и таблицу, в которую данные вместо этого будут попадать.
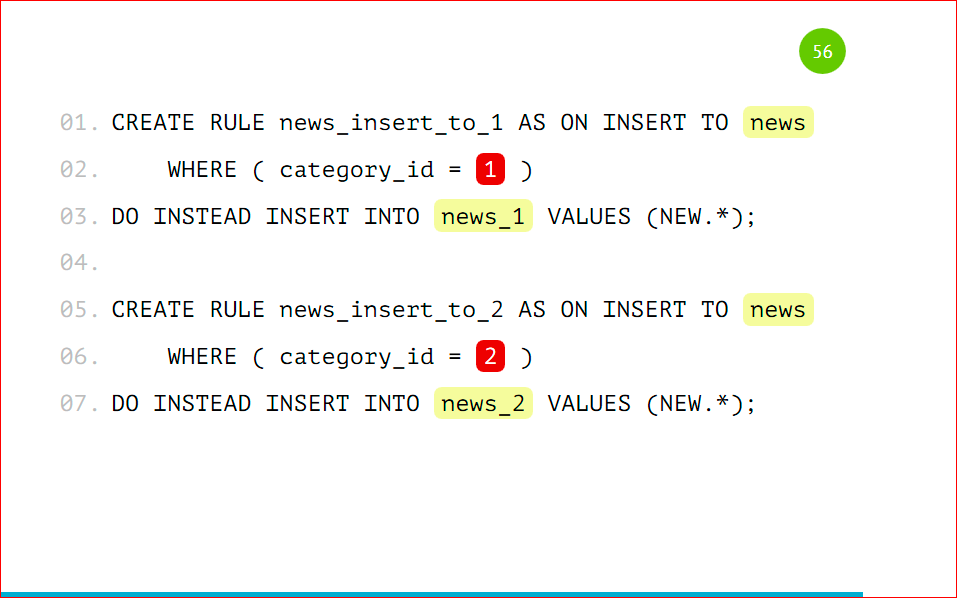
Т.е. единственное отличие – это в category_id мы будем указывать имя таблицы.
Также посмотрим на вставку данных.
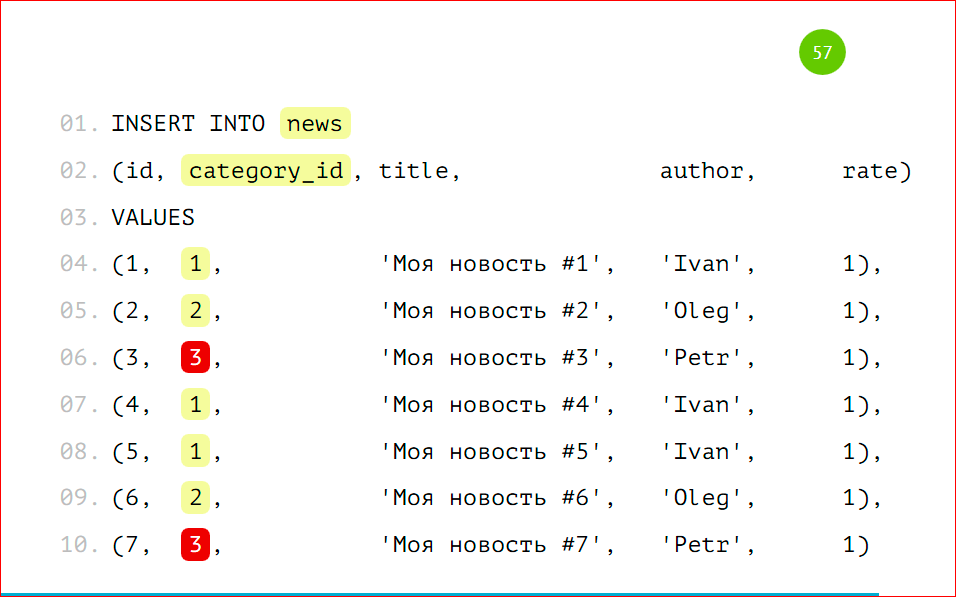
Я специально выделил несуществующие партиции, т.к. эти данные по нашему условию не попадут никуда, т.е. у нас указано, что мы ничего не будем делать, если не нашлось никакого условия, потому что это VIEW, это не настоящая таблица, туда данные вставить нельзя. В том условии мы можем написать, что данные будут вставляться в какую-то третью таблицу, т.е. мы можем завести что-то типа буфера или корзины и INSERT INTO делать в ту таблицу, чтобы там копились данные, если вдруг каких-то партиций у нас нет, и данные стали приходить, для которых нет шардов.
Выбираем данные.
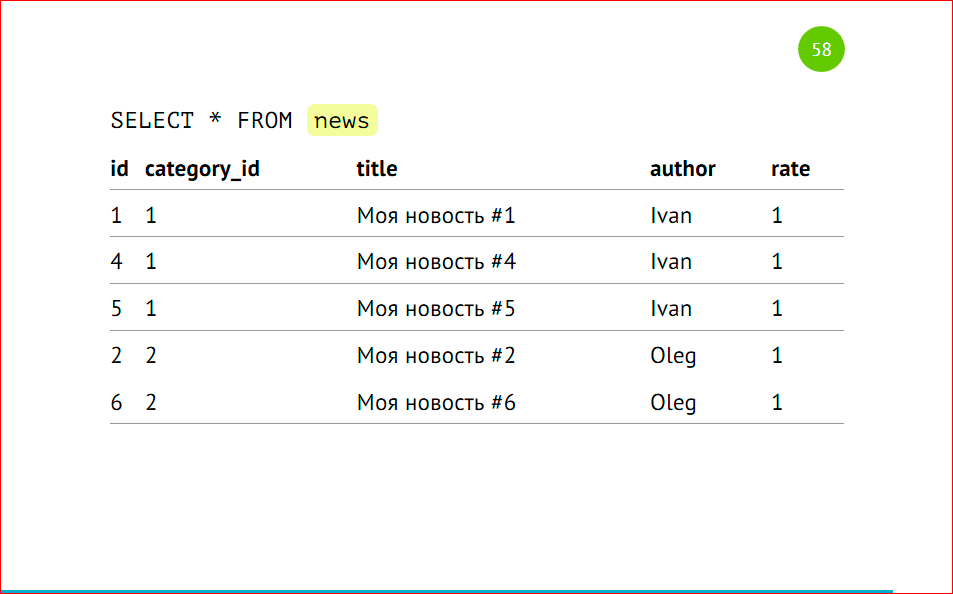
Обратите внимание на сортировку идентификаторов – у нас сначала выводятся все записи из первого шарда, затем из второго. Это происходит из-за того, что postgres ходит по VIEW последовательно. У нас указаны select’ы через UNION ALL, и он именно так исполняет – посылает запросы на удаленные машины, собирает эти данные и склеивает, и они будут отсортированы по тому принципу, по которому мы эту VIEW создали, по которому тот сервер отдал данные.
Делаем запросы, какие мы делали ранее из основной таблицы с указанием категории, тогда postgres отдаст данные только из второго шарда, либо напрямую обращаемся в шард.
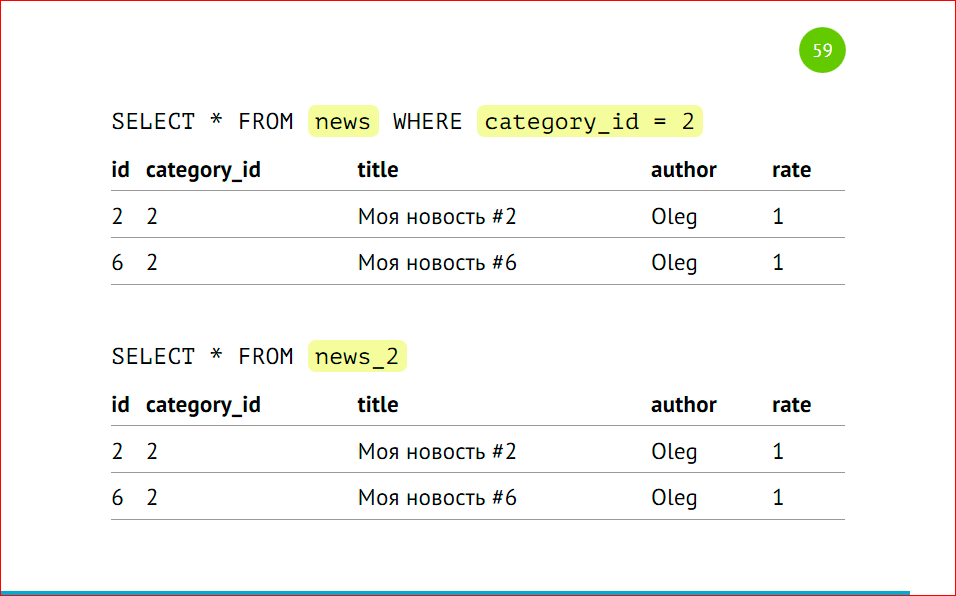
Так же, как и в примерах выше, только у нас разные сервера, разные инстансы, и все точно так же работает как работало раньше.
Посмотрим на explain.
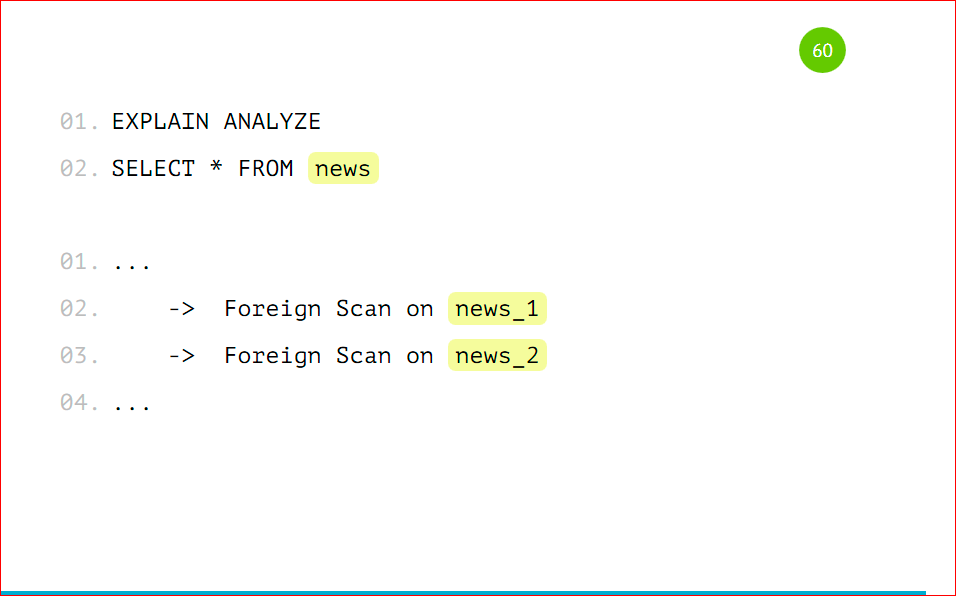
У нас foreign scan по news_1 и foreign scan по news_2, так же, как было с партицированием, только вместо Seq Scan-а у нас foreign scan – это удаленный скан, который выполняется на другом сервере.

Партицирование – это действительно просто, стоит всего лишь несколько действий совершить, все настроить, и оно все будет замечательно работать, не будет просить есть. Можно так же работать с основной таблицей, как мы работали ранее, но при этом у нас все красиво лежит по полочкам и готово к масштабированию, готово к большому количеству данных. Все это работает на одном сервере, и при этом мы получаем прирост производительности в 3-4 раза, за счет того, что у нас объем данных в таблице сокращается, т.к. это разные таблицы.
Шардинг – лишь немного сложнее партицирования, тем, что нужно настраивать каждый сервер по отдельности, но это дает некое преимущество в том, что мы можем просто бесконечное количество серверов добавлять, и все будет замечательно работать.