Как устроена MySQL-репликация
Андрей Аксенов (Sphinx)

Рассказывать буду все то же самое, что и всегда. Если вы читали документацию хотя бы раз, то вы технически, наверное, уже все знаете. Но проблема в том, что, во-первых, никто не читает документацию, во-вторых, документация обновляется, а в-третьих, никто не знает, что и где читать.
В конце будет один самый главный слайд со всякими ключевыми словами. Если вы забудете, то в доке искать вот эти-эти-эти ключевики нет никакой человеческой возможности. А потом прочитал документацию, вынес из доклада 3 ключевика и их прочитал.
Не будет обычного введения типа: «Давайте посмотрим, как настроить репликацию. У нас вообще ничего нет, давайте ее включим, для этого притушим сервер, настроим конфиг тут, перетащим MySQL дамп, не забудем записать позицию в binlog'e, или включим ключик у MySQL дампа, который это делает». Я не уверен, что все это умеют и знают, потому что как бы зачем? Но подобные туториалы под названием "Как взлететь за одну минуту?" их в интернетах много, хотя технически в интернетах вообще все есть, включая исходники.
Начнем с установления терминов. Как оно бывает? Как репликация устроена вообще в любой системе, которая существует на планете? Есть несколько осей измерения, несколько основных вариаций.

Можно сделать синхронную репликацию на физическом уровне, хотя это геморрой страшный, при этом по Push-модели и master-master это можно скомбинировать. Если вдуматься, то это ад и холокост из выбранных решений. Основное, что интересно здесь – это варианты синхронизации той или иной транзакции, т.е. что оно нам гарантирует. Остальное в обзорном виде – как устроена репликация.
Репликация бывает, во-первых. Это не миф. Во-вторых, она бывает синхронная, асинхронная, полусинхронная. На логическом уровне работает с конкретными записями на физической репликации конкретных файлов. Внутри логической – конкретно в применении к базе данных, любой базе данных, не обязательно SQL. На логическом уровне могут возникать еще какие-то интересные градации. И по модели распространения, кто кому изменения пихает push/pull, и по количеству точек записи, либо master-slave, либо master-master.
Репликация – это процесс копирования одной и той же базы данных... Подчеркиваю опять – не обязательно SQL. Когда MongoDB свою копию шарда кладет на соседнюю машину – это тоже репликация, которая делает из одной копии n копий.

Важно понимать, что когда у нас есть много копий, то мы доблестно отмасштабировали чтение из базы данных. Если у нас была база данных, в которую можно впихнуть на одном максимально толстом доступном сервере 1000 записей в секунду (записей в смысле не строк в таблице, а в смысле операций вставки, возможно более сложных, чем одна строка таблицы), если бы мы успевали впихнуть на этом сервере 1000 вставок в секунду и сделать 3000 чтений в секунду, 3000 селектиков, и внезапно сделали 4 реплики, то селектиков у нас будет 12000 в прыжке (на самом деле, скорее всего, чуть меньше), а вставок у нас будет меньше исходной 1 тысячи, потому что в случае с master-slave репликацией у нас одна точка входа, одна точка записи. 3 дополнительные реплики, которые мы подложили, они работают на чтение, они не работают на запись сами по себе.
Репликация отмасштабирует только чтение, записи она не отмасштабирует. Для того чтобы отмасштабировались еще и записи, надо плясать отдельные танцы – шардировать-шардировать-шардировать. Какой для этого механизм представляет MySQL из коробки, я не знаю, т.к. привык делать это вручную.
Важный момент про репликацию – помните, что writes’ы просто так не отмасштабировать, а чтение – можно.
Про синхронизацию. Самый важный момент всех этих возможных осей – как бывает? Бывает синхронная репликация, асинхронная и, типа, полусинхронная.

Синхронная означает, если у вас commit прошел, то база вам обещает, что не просто commit прошел, а он еще и прошел на удаленных нодах. Т.е. мы commit сделали, подключились к одной конкретной ноде, к одному конкретному серверу, эти данные в идеале, чтобы обеспечить и масштабируемость по чтениям и доступность данных, должны улететь на соседние машины, и транзакции там должны зафиксироваться. Это синхронная репликация.
Понятное дело, что на каждый commit дожидаться ответа от удаленных нод, о том, что они и прочитали данные, и успешно накатили транзакцию – это довольно долго, во-первых, и геморройно, во-вторых. Во-первых, ноды могут конкретно лагать, и транзакция, которая на master'е уже пробежала, она теоретически может на каком-нибудь slave'e проиграться сильно потом. Говорят, бывает, что репликация лагает неделями (я такого не видел). Причем не специально, т.е. это удобно для целей backup'а – ты DROP TABLE сделал на основном боевом сервере, и у тебя есть 2 недели, чтобы передумать. Но синхронная репликация – это медленно, счастья от нее особого нет.
Не очень интересен вариант под названием "асинхронная репликация", потому что гарантий нет, совсем никаких. Но ок, транзакция зафиксировалась локально, это тебе что-нибудь гарантирует? Правильный ответ – нет. Потому что возможно, что все остальные реплики лежат дохлые, и те данные, которые вы вкатили на master, они у вас никуда не резервируются. Если у вас master просто упадет, в смысле SQL-сервер упадет, то все хорошо условно, он эти изменения с Write-Ahead Log'a проиграет, но если у вас внезапно демоническая сила подожжет сервер, и он сгорит, прям весь, то данные, которые вы якобы зафиксировали, они на самом деле зафиксировались на одной машине.
Синхронность – хорошо с точки зрения надежности, но медленно. Асинхронность полная – зафиксировали локально транзакцию и не ждем вообще удаленные реплики – очевидно быстро (ничем же не отличается от локального commit'a), но никаких гарантий по надежности.
Возникает промежуточный вариант – полусинхронная репликация – это когда commit возвращает успех, в тот момент, когда локально транзакция уже зафиксирована, селекты к master'у уже начнут возвращать новое состояние, новый баланс, и удаленные сервера уже скачали эти данные, уже скачали эту транзакцию, но возможно еще не успели накатить, то ли накатят через 2 секунды, то ли через 2 недели – как повезет. Это самый важный момент, с которым на практике придется сталкиваться, и делать выбор, настраивать и т.д.
По-моему, все эти 3 варианта есть в MySQL'e, с тем единственным исключением, что синхронная репликация там есть не в традиционных, привычных всем движках и т.д. Слышал я одну легенду об InnoDB кластере, что некая адская машинка, пришедшая к нам из телекома, с чудовищными требованиями по доступности все держит в памяти, доступность 17 девяток, синхронная мультимастер-репликация, все работает… Одна проблема – живьем ее никто не видел. Людей с прямым опытом работы с InnoDB кластером найти не удается.
Какая еще теоретически бывает репликация?
Теоретически, вместо того, чтобы работать с внутренними данными внутри базы на логическом уровне, неважно с какими данными, то ли с отдельными обработанными транзакциями, то ли со стейтментами напрямую, но на логическом уровне можно изловчиться и скопировать базу на физическом уровне.

Предположим, что у вас есть мощный ZFS, который на уровне файловой системы размазывает все данные, которые база успевает писать на диск, на много-много серверов и хорошо справляется с этой задачей. Чисто теоретически – вот вам репликация, с тем отличием от случая, который хочется, что она вам обеспечивает клевый горячий backup, распределенный на несколько серверов, но не обеспечивает горячую реплику, которую можно еще для чтения использовать. Технически, наверное, можно и так. Но я, правда, не слышал, чтобы это было сильно популярным. На логическом уровне проще с одной стороны, внутри базы реализовать на физическом вообще смысла нет, и становится возможным делать не просто backup, который куда-то отгружается, но и реплики, с которых еще и читать можно.

Модели рассылки изменений – кто кому звонит – push/pull. Pull – это если реплики тащат изменения с master’а. Push – это если master вдобавок к задаче обработки транзакций еще и вынужден slave’ы менеджить. Теоретически где-то бывает push, но я совершенно забыл, в каких эзотерических системах используется этот странный метод push – «Когда мне транзацию впихивают, я и так работаю за всех, я вам изменения всем рассылаю, еще и я ответственный. Да вы охренели, дорогие реплики, тяните изменения сами, кто из вас там сдохнет, кто выживет – вообще не моя проблема, я сервер, я занят, я хочу фыр-фыр-фыр, а мне надо 30 тыс. транзакций в секунду commit'ить».
Есть важная дифференциация – master-slave, master-master. Традиционно встроенная в MySQL репликация – master-slave. Т.е. есть одна ведущая нода, которая принимает все изменения, все остальные – ведомые реплики, в которые, технически, к несчастью, вы тоже можете сделать какое-то изменение. Т.е. у вас стоит master с основной таблицей и основным балансом пользователей, условно говоря, в вашем маленьком предбанкротном банке, у вас есть много реплик, потому что не клево хранить баланс... С точки зрения креативной бухгалтерии и уклонения от уголовного преследования, наоборот, клево хранить все на сервере, который стоит в «газели», законекчен по wi-fi, и как только приходит следственный комитет, «газель» уезжает. А что ты с ней сделаешь? Это частная собственность ее досматривать нельзя. С этой точки зрения клево иметь один master, а в других, более приличных случаях хочется иметь еще несколько реплик.
Master-slave модель – есть основные master-копии, есть несколько (теоретически read-only) реплик, которые только вытаскивают изменения с основной master-копии. К несчастью, в том числе в MySQL, можно на эти ведомые реплики, все равно, просунуть какое-то изменение прямо туда – на master'e у нас балансы меняются, все это разлетается на N реплик, а тут кто-то на одной реплике берет и что-то меняет, это может привести к бедам.
Еще бывает master-master модель, когда изменения можно пихать во много серверов разом, и они промеж себя этими изменениями обмениваются и пытаются удерживать консистентность данных. Понятно, когда у вас есть master-master репликация, то начинается поистине интересный креатив – вот, у вас стоит один сервер, условно говоря, в Бангкоке, второй – в Йоханнесбурге. Там свет долетает по прямой за вполне измеримое время, а ворона вообще никогда не долетит. И транзакция, которая прошла в Бангкоке, хорошо, если она не трогает никаких данных, по сравнению с транзакцией, которая в этот момент проходит в Йоханнесбурге. Но если они обе пытаются менять один и тот же баланс, то начинается масса интересных вещей: а в какое время была зафиксирована транзакция здесь, а в какое там, а на сколько расходятся часы, а какие данные они меняют, а в каком порядке их следовало применять?
Может возникнуть какой-то конфликт, и система может умудриться его автоматически разрешить, а может не смочь. Но в этом есть определенное счастье. Иногда оно помогает скейлить записи, а иногда – нет. Если у вас в конечном итоге все записи должны прилететь на один сервер, как вам поможет тот факт, что у вас 5 точек входа? Они же все равно сходятся в одной конкретной базе, и ее производительность будет bottleneck'ом. Читать в любой схеме можно с любой точки. Что у вас один master и 5 реплик, что у вас 6 master’ов, которые друг с другом успевают всяким меняться – читать можно со всех точек.
Важный момент – в каком формате передаем изменения между нодами? Вариантов не много.

Можно передавать сами запросы исходные. Пользователь заслал какой-то запрос, мы складываем его в протокол, в log, и его передаем на реплику. Либо можно вместо этого передавать измененные строчки. И то, и другое по-своему плохо. Можно смешивать, но это, по-моему, хуже всего.
Как сделано в MySQL? Правильный ответ: "А хрен его знает, товарищ прапорщик". Потому что в MySQL в зависимости от версии есть разные capabilities у сервера, т.е. версия 5.6. может полусинхронную репликацию делать, т.е. ты можешь заслать commit и молись… Еще получить гарантии, что этот commit не только прошел, а что реплики его хотя бы вычитали/скачали у тебя. Кроме того, дело осложняется тем, что фичу-то в каждой отдельной версии и сделали, но она не обязательно включена, а если включена, то может работать не так, как вы ожидаете.
Как устроено все на самом деле? Асинхронная репликация или синхронная, что это значит? А значит это следующее.

Master работает как обычно, вдобавок из-за репликации пишет специальный протокол под названием binary log (=binlog), который потом будет рассылать по сетке. А что мы пишем в этот binlog – то ли сами строчки, то ли стейтменты – это как раз про binary log. Т.е. дополнительная нагрузка на master из-за репликации, как вещи в себе, довольно не высокая. Введем дополнительный log, ну и хрен с ним, мы по сетке его рассылаем – это тоже довольно ненапряжно.
Единственный подлый момент, связанный с архитектурой MySQL – это то, что нет никакого MySQL на самом деле – это все миф и иллюзия, т.е. есть MySQL общий слой, который оптимайзер, репликации и т.д. и т.п. А есть физический уровень хранения данных. И вот архитектура MySQL'евская со втыкаемыми движками хранения pluggable storage engines, она приводит к тому, что у InnoDB свой Write-Ahead Log, т.е. ты суешь запись в MySQL – она прилетает в конкретный движок, в конкретный storage engine, если MyISAM, то все просто – записали в файл, потеряли, ништяк. Если в InnoDB, то все сложнее, пишем в памяти, пишем Write-Ahead Log, иногда сваливаем странички на диск. А за счет того, что Write-Ahead Log у каждого движка либо есть, либо нет, либо хрен его знает, то для репликации MySQL должен ввести свой собственный binlog. Получается overhead, который, если не аккуратно настроить и мало железа, может оказаться довольно нехилый.
В самом деле, то у нас storage engine, то у нас движок хранения делает работу – хранит данные, фиксирует транзакции и для этого ведет свой протокол. Было бы клево, если бы этот протокол Write-Ahead Log от InnoDB , либо его аналоги в других движках можно было использовать для репликации, но нет – нельзя. Это расплата за то, что в MySQL можно втыкать сторонние движки.
Получается, что слишком много записей на каждую запись и вот появляется дополнительная. Увы и ах. Но на самом деле дополнительная линейная запись в binlog – это не так страшно, особенно если вы ее избавите от всяких ненужных sync'ов, вынесете на отдельный диск и т.д.

На slave’e все интересней, потому что slave’у недостаточно файл прочитать, ему еще поработать надо для того, чтобы свое состояние догнать до того, которое наблюдается на master'е. Он может обрабатывать чтение, для этого и придуман. К несчастью, он может обрабатывать вставки тоже. Внутри для репликации здесь основные два концепта – это thread, который качает данные с master’а (или разных master’ов) бинарные логи, которые лежат на master’e и складывает их локально. Буквально: читает файл по сетке и локально пишет копию этого файла.
Там мог бы быть SCP, Rsync или что угодно еще, команда CP через NFS. По факту оно реализовано парой-тройкой SQL statement’ов, которые slave дает на master’e, после этого ему в socket начинают литься бинарные данные, которые он пишет на диск – тупо копирование файла по сетке. Поэтому проблемы под названием "у меня что-то не то с копированием – binlog с master’a не успевает в relay log локальный скопироваться" возникают редко. Задача прочитать файл по сетке не сложная, ее уже лет 60 решают и научились решать. Значительно смешнее задача проигрывания этих binlog’ов. Нам прилетают какие-то изменения с master’a, мы должны применять эти транзакции. Фарш начинается здесь. Нужно отслеживать позиции везде, т.е. где мы сейчас стоим на master’e, куда мы сейчас записали все это локально (локально называется relay log.
Путь записи. Как оно работает в случае приятном и простом, когда у вас один сервер и больше ничего?

Просто как палка. Какой-то клиент-писатель подцепился к серверу, сунул запись, транзакция зафиксировалась, запись, условно говоря, попала в таблицу, после этого она доступна приложениям читателя, все.
В момент, когда появляется репликация, путь может быть более извилист. Запись не только попадает в измененное в таблицу на master’e, она еще попадает в binary log на master’e, что не очень напряжно, после этого оно попадает в relay log на slave’е, что опять не очень напряжно, тупо копирование файлов. После этого начинается самый интересный момент с проигрыванием. Основной bottleneck и тормоза – они здесь. Они в попадании из relay log’a в таблицу на slave’е. Отсюда оно уже из slave’а доступно читателям, и здесь начинается счастье, т.е. читатели могут обращаться не только к master’у, но и к slave’у, чтение уверенно растет.
Что за данные конкретно лежат в binary log? Как бывает, как хорошо, как плохо, и как посмотреть?

Зависит, к несчастью, и гибко настраивается.
Все любят системы, где есть одна кнопка "сделать хорошо", нажал ее – и тебе хорошо. Но такие системы научились строить на улице красных фонарей, но не в IT, поэтому в IT вечно какие-нибудь дуделки, вертелки и настройки.
Настройки – как раз те binlog_format, про которые я говорил, – SBR/RBR/mixed. Либо фиксируем сами запросы в том виде, в котором они прилетели от клиента, либо смотрим, например, что мы обновляем всю таблицу с пользователями, а пользователей у нас в таблице 10 млн, внезапно маленький запрос на 50 байт приводит к обновлению 10 млн строк. И что, нам обновленные 10 млн строк писать в этот log? Это плохо. В этом случае сильно эффективней писать само выражение. Наверное, из-за этой логики в основной массе версий MySQL оно дефолтиться в statement based репликацию, т.е. в тупую реплицирует сами SQL-запросы. Оно сохраняет и реплицирует как есть, без всякой дополнительной магии. Думаете, оно хотя бы стадию парсинга проходит, какое-то бинарное дерево пишет, хоть как-то облегчает работу slave’ам? Ни хрена, прям как есть. Запрос прилетел, в таком виде и будет записан. Как максимум, кавычки вокруг названий таблиц поставят на всякий случай и все.
Возникает один неприятный момент с этой statement based репликацией – в момент, когда у нас на master’e возникают некие недетерминированные функции, которые даже на первый взгляд могут казаться детерминированными. Что происходит, когда мы реплицируем этот запрос? Мы отключаем на master’e всех людей, которые не логинились в последние 100 дней по часам master’a. А реплика может проиграть этот запрос через 3 дня с одной стороны, плюс на ней сисадмин мог случайно забыть перенести time-зону с другой стороны, плюс на ней общий дрифт часов мог устроить расхождение еще на несколько дней со стороны третьей. Т.е. для краткости клево записать в протокол этот запрос и его проиграть на реплике. На практике у вас обязательно разойдутся данные внутри этого запроса. Обязательно, даже если вы не заметите. Понятное дело, если гранулярность достаточно высокая – вам повезло, значения now разошлись, но это не привело к расхождению в выбранных юзерах, то все хорошо.
Во всех остальных случаях – все плохо. В этих случаях нужно писать измененные строчки в запрос. Идея-то хорошая, но приходит пушной зверек "опа горностай".

Значит время несинхронно, расхождение и еще масса осложнений, которые делают запрос недетерминированным... Нам надо писать строчки. Строчки писать больно, по той причине, что много данных, по сравнению с запросом, но в некоторые моменты необходимо. И внезапно приходим к ситуации, как в том анекдоте:
– Чувак, как ты со своей бородой спишь?
– Сука, я из-за тебя вообще спать не могу, под одеяло ее суну – неудобно, над одеялом суну – тоже неудобно.

Statement based репликация, когда у нас SQL запросы, вроде бы хорошо, но и плохо одновременно. А RBR – row based репликация, когда сами копии строк складываются в протокол – тоже хорошо, но плохо.
Есть вариант "давайте получим лучшее из обоих миров" и будем смешивать, называется Mixed binlog format.

Там по умолчанию он дефолтится в тот же самый statement format, т.е. в протокол складируются все запросы, которые вы шарахали к базе данных, за исключением селектов, которые ничего не меняли, но иногда при определенных условиях доку откровенно страшно читать, чувствуется, что там вот такой вот список условий, что невозможно его запомнить, в принципе. Иногда оно само переключается на row based репликацию. Теоретически оно должно работать хорошо. Т.е. по умолчанию логировать стейтменты, минимизировать тем самым трафик между master’ом и репликой, но иногда переключаться на row based. Cмущает, что mixed format товарищи из MySQL включили дефолтным в небольшом окне версий, что-то типа с 5.1.12 по 5.1.28, а потом на всякий случай выключили и вернулись обратно к statement based репликации. А потом вернулись опять к row based репликации – не могут никак определиться.
Как посмотреть, что там за данные лежат? Вдруг когда-нибудь понадобиться.
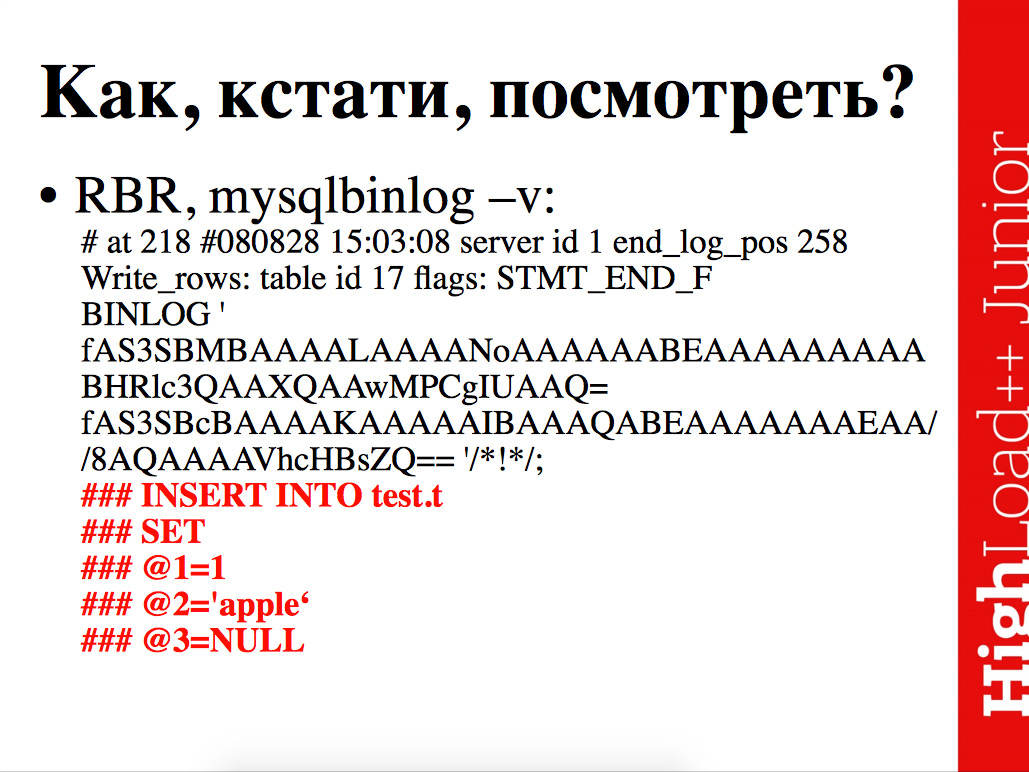
Там довольно нехитрый бинарный формат, который, если хочется, руками довольно просто разбирать, но даже этого делать не надо – есть утилита mysqlbinlog.
Утилита mysqlbinlog в момент, когда оно туда пишет сами SQL-запросы, показывает прямо SQL-запросы, весь фарш бинарный, который кодирует все эти серверы ID, позиции в логе и прочие интересные штуки, она форматирует в текстовый вид и показывает запрос. Без ключика "–v", для road based репликации вам покажут вот такой вот клевый дамп, как на слайде. Спасибо, что based 64, спасибо, что не бинарь. В случае с ключиком "-v" оно его немного разбирает и имена колонок не восстанавливает, но показывает значения, которые в этом бинарном дампе закодированы – это для row based репликации.
Для statement based репликации все просто – утилита просто лог смотрит.
Дальше, что происходит внутри? Мы поняли, что происходит на master’e, когда мы включили репликацию. У нас завелся binary log, в него что-то началось писаться, писаться в разных форматах, с разными проблемами, и именно эти данные будут улетать на slave, на реплики.
Что происходит на slave’е? На slave’е, к несчастью, начинается все самое интересное.

Ок, есть спецтред, который качает binary log, локально его пишет в relay log, после чего другой спецтред из этого relay log свежепрочитанные данные проигрывает. Естественно на slave’е другое имя файла, другие позиции в relay log’ax, по сравнению с binlog’ами. И это до определенного момента важно, потому что в MySQL вплоть до версии 5.5 включительно чувствуется матерая ошибка молодости – нет никакого механизма идентифицировать транзакцию, которая где-то там случилась, кроме как по имени файла и позиции в этом файле. Транзакция значит, что ваш баланс в банке решительно поменялся и идентифицируется вплоть по версии 5.5 буквально парой. На master’e лежит файл binlog.013, в нем в позиции 571 лежит эта транзакция – это единственный метод опознать ее уникальность. Если кто-то слил вместе файлы на сервере, или переименовал, или они выпуржились, или т.д., то "все пропало, шеф", "атас, менты, смывай наколки".
Когда работает – все хорошо, проблема в том, что когда ломается – позиции слетают, файлы переименовываются, и прочие интересные вещи происходят, то этот механизм идентификации транзакции по имени файла на другом компьютере... Его нет локально уже, у нас локально на реплике relay log, binlog’a, возможно, вообще нет. Позиций на каждую транзакцию не нахранишься. Это одна большая беда.
Вторая – не то, чтобы ошибка молодости, а традиционно от лени, сначала сделали, чтобы хоть как-то работало, а потом много лет делаем, чтоб заработало нормально – это тот факт, что slave однопоточный в обоих местах. Понятное дело, что thread, который тащит данные по сети, он может очень много данных прокачать по сети, и nginx тому примером. Ты иди загрузи сервер с nginx'ом, который статику раздает на 100% CPU – удачи в бизнесе. А тот факт, что thread, который проигрывает свежескачанные транзакции однопоточные, вот это уже убийство, из-за этого возникает репликационный лаг и прочие неприятные эффекты. У вас master всей своей 32-х ядерной мощью, и умудряясь использовать хотя бы 12 из этих 32-х ядер на полезную работу, доблестно commit-ит транзакцию, а после этого репликой в один thread... Как в известном мультике: "Он пока на своих 4-х ногах на своей лошади 1-2-3-4, а ты на 2-х раз-два, раз-два". Вот вплоть до 5.5 включительно slave’ы «раз-два, раз-два», и производительности этого потока может хватить, может не хватить.
Вплоть до 5.5 включительно емкость slave’а невозможно нарастить добавлением ядер – не успевал и не будет успевать, только гнать по частоте и азотную установку для охлаждения. Это грустно, но, к несчастью, в MySQL тоже не дураки сидят (просто тормоза), и поэтому начинают насущные проблемы менять и фиксить.
С версии 5.6 наконец-то началась борьба с обоими дебильными проблемами – сделали мощную фичу под названием Global TID – глобальные идентификаторы транзакций, которые ликвидируют беду под названием "все, что происходит на master’e, мы опознаем по имени файла и смещению в этом файле". Не дай бог что-то с файлами произойдет.

Теперь к каждой транзакции добавляется некий уникальный номер, и у slave’а появляется целый новый ряд проблем, под названием "вдруг на нем кто-то херанул запись ошибочную, а его запромотили до master’a и тогда по GTID’ам мы же поймем, что запись немедленно должна разлететься на все остальные сервера" .Т.е. ты на slave’е убил какую-нибудь таблицу случайно, не нужна была, и на этом конкретном slave’е оно проканало, потом slave’ запромотили до master’a, в этот момент транзакция проиграется на всех остальных нодах кластера. Будет счастье.
Но, тем не менее, фича приятная и полезная, потому что, когда сервер может автоматически идентифицировать транзакции по некоему уникальному номеру, и тебе не надо смотреть с лупой на бинарный лог и вычислять, какая позиция в relay log’e локальном соответствует какой позиции в исходном binary log’e, который уже стерли – это приятно. Когда этим может заниматься автоматика, а с GTID’ами она может, это вот хорошо.
Кроме того, сделали "многопоточные" slave’ы в 5.6.5, т.е. если ваши изменения, которые льются в одну схему всех остальных баз данных, в MySQL известную как database, то ничего не поможет. Но если у вас несколько разных databases, и между ними несвязанные транзакции, то 5.6 умеет их наливать в несколько потоков. Подчеркиваю, изменениям в одну таблицу оно не поможет никак. GTID’ы немного сажают производительность, но зато потом сильно экономят количество седых волос при восстановлениях при сбоях.

5.7, по-моему, в beta’e многолетней, вроде бы еще не generally available. Там борьба продолжается.
В 5.6 вернули функциональность под названием "group commit binlog", которая позволяет делать поистине многопоточную репликацию. В чем счастье? Раньше, до группового commit’a, до того, как его заставили снова работать, транзакции в binlog писались по одной: записал одну, делай fsynс, записал одну, делай fsynс – это с точки зрения общей производительности нехорошо.
Клево распознавать транзакции, которые независимо трогают разные данные и в лог их вкладывают небольшими группками – в несколько раз меньше записей в бинарный лог, по объему их столько же, но системных вызовов меньше write и fsync’ов меньше.
Binlog group commit приделали обратно еще в 5.6, но начиная с 5.7.2 вдобавок приделали поддержку этого дела, чтобы делать многопоточную репликацию на slave’ах. Как обычно, оно выключено по умолчанию и GDIT’ы выключены, и эти новые достижения тоже выключены и их нужно рукой подпихивать и включать и для того, чтобы счастье наступило, вам недостаточно проапгрейдиться на новую версию, вам надо еще всякое понавключать.

Еще в версии 5.7.7 сделали, с моей точки зрения, странные изменения – переключили дефолтный формат бинарного лога. 100 лет с версии 4.1 жили со statement based репликацией, но переключились на row based репликацию, при этом сменили дефолт binlog_format (есть настройка, что писать в binlog – то ли строчки, то ли statement’ы, то ли что), но при этом не сменили дефолт binlog_row_image. Это вызывает неподдельный интерес, потому что волшебная настройка binlog_row_image означает – в момент, когда мы пишем какое-то изменение в binlog, у нас есть несколько вариантов, что туда дописать.

Первая идея, что приходит мне в голову, – это у нас запись номер 123, ей ставят значение 456 в такую-то колонку, давайте это и запишем ID123 – новое значение 456. Если подумать еще немного, для полной паранойи, можно записать не только новое значение 456, но и предыдущее значение 455, чтобы в случае, если у нас что-то все-таки сломалось и транзакции пошли не в том порядке, мы могли понять, что транзакция, которую мы собираемся накатывать, внезапно пытается изменять другие данные.
Наверно, из соображений максимальной паранойи и хрен с ней с производительностью, MySQL дефолтится в режим, когда в log’e хранятся не просто измененные данные и идентификатор записи, а полная копия всей строчки до изменения, и полная копия всей строчки после изменения. Т.е. это прикольно, когда у вас таблица из 2-х колонок, но когда у вас 3-х килобайтная в среднем строчка, а вы в ней меняете одно маленькое поле, это означает, что в binlog пишутся все 6 Kбайт, из них поменялось 4 байта, которые вы поменяли в числовой колонке.
Это настраивается, слава богу, есть binlog_row_image, который дефолтится в full, но который можно перемкнуть в Noblob хотя бы, либо в Minimal. Но почему-то оно дефолтится именно в full. Как обычно, все плохо, но неплохо. Я уверен, что есть причины для того, чтобы делать именно так, но мне они неизвестны.
Надо понимать, что интересный момент в 5.7.7 произошел. Апгрейдитесь до 5.7.7 и, если у вас явно в конфиге не прописано, внезапно формат binlog’a меняется.
Дефолт сменился, при этом сменился, на мой взгляд странно, но я не разработчик MySQL и не знаю полной мотивации, которая стоит за этим изменением. В общем и целом, ситуация с версиями такая. Каждый день что-то интересное происходит, не всегда хорошее, но, тем не менее, жить с этим можно все равно.
Итого итоги подведем про версии.

MySQL ширится и мастерски развивается – делают новые клевые фичи, которые закрывают старые головные боли.
5.7 с введением групповых commit’ов, и, как следствие, возможностью многопоточную закачку на slave’ы делать, тем самым закрывает старый головняк под названием "у нас slave не успевает и не успеет никогда".
GTID’ы ликвидировали старую операционную беду под названием "как бы прикольно идентифицировать транзакцию по имени файла где-то там далеко за горизонтом, но не прикольно потом разбирать сломанный инстанс".
5.7 с GTID’ами и групповыми commit’ами, и, как следствие, многопоточным проигрыванием изменений на slave’е – совсем хорошо, но не в тот момент, когда ты Facebook и полгода просто выкатываешь это изменение. Но даже в тот момент, когда ты Facebook и полгода выкатываешь это изменение, ты в конце концов, когда все выкатил, все равно пишешь в блоге, что было сложно, но в итоге – хорошо, все-таки оно того стоило.
Если 5.7 очково ставить и всякие многопоточные штуки включать очково, то хотя бы 5.6 плюс глобальные TID хотя бы – так хорошо.
Традиционно в MySQL вызывают изумление принятые дефолты, дефолты странные, т.е. всякое новое полезное делают, но это дело отключено. Местами, когда эти дефолты меняются, они тоже меняются как-то странно. Переключились на row based репликацию, по умолчанию логируем полную строчку, что в моем понимании, в общем случае – ад и холокост. И не понятно, стоит ли профит в одном проценте случаев деградацией в 99-ти? Так что с дефолтами надо зорко озираться. Озираться с одной стороны, и просто так новый функционал не заработает – надо его включить, с другой стороны.
Также немаловажная деталь там, где я пишу 5.7, надо иметь в виду 5.7.2 или 5.7.7 или 5.7.12, где наконец-то починили Showstopper баг или что-то типа того. Т.е. версий 5.6, 5.7 недостаточно, еще минорные версии важны, вот в 5.7.2 добавили вот это, в 5.7.7 сделали вот это, т.е. даже минорная версия может интересно подкузьмить.

В принципе, все не так и сложно, но для того, чтобы внятно эксплуатировать и чуть лучше понимать, где у тебя беда надо представлять себе ряд ключевых слов, которые мы сегодня попробовали себе представить.
И 2-ая половина доклада очень кратко в слайдах – вопросы с одной стороны и ряд стандартных проблем с другой стороны.

Есть ряд стандартных проблем и должно быть теперь понятно, как их чинить.

Возможен ряд всяких фокусов с MySQL’льной репликацией – несколько master’ов в цепочку завязать, сделать catch-all slave, сильно покреативить с репликацией, немножко потрансформировать данные в ходе репликации.

Некоторое количество ключевых слов, на счет которых можно дальше читать про репликацию.