Sharding – patterns and antipatterns
Константин Осипов (Mail.ru, Tarantool), Алексей Рыбак (Badoo)

Константин Осипов: Доклад родился из следующего разговора. Я, как всегда, пытался убедить Алексея больше использовать Tarantool, а он сказал, что там до сих пор нет шардинга и, вообще, неинтересно. Тогда мы стали рассуждать о том, почему нет. Я стал рассказывать, что тут нет одного универсального решения, автоматика полная за вас работает, а вы только кофе на работе пьете и все... Поэтому родился этот доклад – чтобы посмотреть на то, какой бывает шардинг, какие методы в каких системах используются, какие преимущества и недостатки, почему нельзя одной "серебряной пулей" все решить?
Если говорить о шардинге, как о проблеме, то, вообще говоря, такой проблемы нет. Есть проблема распределенных систем, т.е. есть больших баз данных, которые горизонтально масштабируются, у них множество задач, мы их перечислили:

В первую очередь, чем больше у вас узлов, тем острее стоит проблема выхода их из строя. Представьте, что у вас из 1000 компьютеров по одному будет ломаться, в среднем, через день или чаще. Поэтому перед вами стоит задача избыточности данных, чтобы не терять их. И это не шардинг. Это, скорее, репликация.
Самая сложная проблема в распределенной системе – это проблема членства, т.е. кто в нее входит, кто не входит, потому что машины выходят из строя, происходят ошибки, и постоянное членство в распределенной системе меняется. Об этом мы тоже не будем говорить.
Есть задача распределенного выполнения сложных запросов. MapReduce или распределенный SQL. Это тоже не оно.
Так, о чем же мы будем говорить?
Мы возьмем одну тему, а именно тему того, как какой-то объем данных, который не помещается на одну машину, можно распределить горизонтально по горизонтальному кластеру, и как этим всем потом управлять.

Алексей Рыбак: Я добавлю. Термин уже устоявшийся, но, все-таки, что же такое шардинг? Вдруг кто-то не знает. Шардинг – это метод, как правило, горизонтального разделения данных. Чаще всего про шардинг говорят не только про распределенные базы данных, но и, вообще, про распределенные хранилища. Мы будем, прежде всего, фокусироваться на базах данных.

Константин Осипов: В нашем докладе мы взяли три вещи, которые составляют из себя сам шардинг, это:
- выбор функции шардинга,
- то, где находятся ваши данные (как вы их находите),
- то, как вы перераспределяете ваши данные.
Мы постараемся сделать так, чтобы этот доклад был не теоретическим, а о том, как это работает в тех проектах, которые мы знаем, т.е. будут истории из жизни.
Алексей Рыбак: Несмотря на то, что мы будем рассказывать всякие истории о том, что и как было сделано, все-таки, основа доклада – методологическая. Чтобы представить, как обычно все делается (а ,так или иначе, все делается лишь несколькими способами), с тем, чтобы устаканились термины, и в следующий раз, если мы будем углубляться в какие-то темы, мы говорили бы на одном языке.
Константин Осипов: Перед нами не стоит задача убедить вас использовать тот или иной продукт, но с помощью этого доклада, может быть, вы сможете лучше понимать, как "под капотом" работает тот или иной продукт, и каковы преимущества и недостатки решения, выбранного разработчиками этого продукта.
Управлять любой системой вы можете, только понимая, как она работает.
Собственно, что такое шардинг на поверхности? Это выбор способа. Этот выбор я обозначу вот так просто:
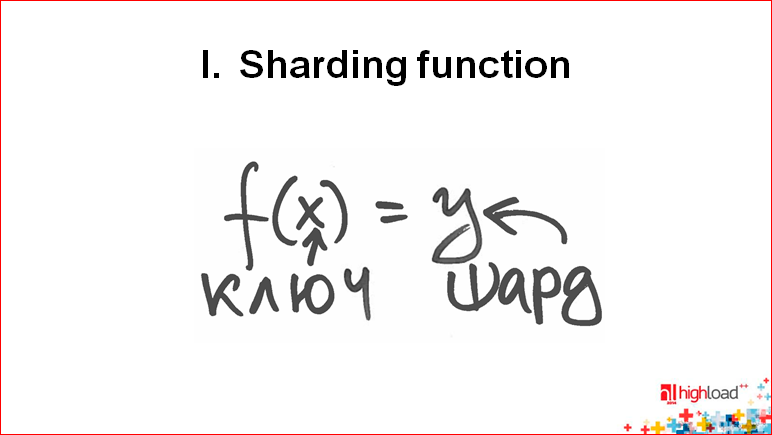
У нас есть некий ключ, мы должны определить шард. Шард – это обычно или IP-адрес, либо DNS-адрес компьютера, на котором все это находится.
На самом деле, формула неправильная, потому что в общем случае здесь должна быть функция от ключа и от количества серверов, т.е. сколько у нас машин или, вообще, от множества серверов. И она должна выдавать нужный сервер, потому что она по-разному работает на разном количестве серверов.
Но прежде, чем мы будем об этом говорить, мы хотим поговорить о чем-то более веселом, а именно о выборе правильного ключа, по которому производится это разбиение. Тут история, в общем-то, такая: вы выбираете ключ, по которому шардите данные один раз, и живете с ним всю жизнь, ну или долго – несколько лет, и получаете все преимущества и недостатки этого дела.
А уже гораздо позже, когда что-то сделать уже нельзя (потому что данные уже определенным образом распределены, система уже работает, downtime невозможен) какие тут, вообще, могут быть проблемы, истории?
Одна история – еще из 2001 г., времен молодости SpyLOG-а – там шардинг был основан на пользователях. Что такое SpyLOG? Сейчас это Openstat. Он собирает статистику посещений, т.е. это такой трекер, счетчик, маленькая кнопочка на страничке.
В общем, все сайты – как крупные, так и мелкие – были на тот момент распределены по 40 машинам. И, соответственно, сайты покрупнее жили вместе с сайтами помельче, т.е. ключом шардинга был ID сайта, например, анекдот.ру, рамблер.ру, яндекс.ру...
Так получалось, что большие сайты реально укладывали наши машины, потому что один трафик, генерируемый одним ключом шардинга, был больше, чем одна машина могла принять.
Поэтому, когда вы выбираете то, по чему вы шардите данные, вы должны выбрать достаточно маленькой объект, чтобы он не положил систему.
Допустим, в случае фейсбука у вас есть страничка Джастина Бибера, и вы решили шардить данные тоже по пользователям. Естественно, у Джастина Бибера миллион каких-то фолловеров, лайкеров, на каждое его сообщение куча репостов и т.д. Поэтому, наверное, выбор Джастина Бибера в качестве того, по кому вы будете шардить – не самая лучшая идея.
Второй момент, который надо при шардинге держать в голове, что шардинг – это не про нормализацию, т.е. если вы думаете, что есть какой-то канонический способ посмотреть на ваши данные и определить, как вы их будете распределять по вашим машинам, то это не так. То есть, вы должны смотреть не на данные, а на use case-ы, на ваше приложение, на ваш бизнес, и вы должны думать, какой use case в вашем бизнесе самый важный и должен быть самым производительным. Потому что в шардинге всегда есть компромиссы. Какие-то запросы работают быстро, мгновенно, какие-то запросы вы вынуждены будете выполнять на весь кластер. И выбор того, по какому ключу вы шардите, определяет это.
Алексей Рыбак: О Джастине Бибере. А я считаю, что в большей части социальных сетей, на самом деле, выбор пользователя в качестве шардингового ключа – это хороший выбор. Но надо помнить, что если вы при этом все посты, комментарии и пр. упаковываете в один и тот же шард, то будьте готовы, что в какой-то момент у вас будет очень неоднородное распределение данных и, возможно, вам нужно будет использовать в вашем проекте два типа шардинга – один ваш изначальный, по юзерам, а второй – какой-то дополнительный – например, по комментам.
Это естественно будет приводить к тому, что данные будут (с некоей вероятностью) неконсистентными, что вам нужно будет вместо одного запроса делать два. Это не страшно, потому что при этом вы приобретаете возможность как-то расти.
А если вы все упакуете на один шард, то у вас будет все очень сильно разбалансировано, и качество вашего софта и вашего сервиса для пользователей может быть очень низким. Поэтому не страшно, что мы сделаем программирование более сложным, зато у нас все будет достаточно быстро. То есть это вполне себе разумный trade-off.
Константин Осипов: Еще один момент, о котором хотелось бы сказать. Не всегда шардинг-ключ у вас хранится. Например, хранение сессий на мэйл.ру. Допустим, у вас есть ID мэйл.ру, у меня это kostea.mail.ru или что-то такое. Сессия – это тот объект, который идентифицирует девайс, с которого я зашел. Соответственно, у одного логина много сессий. Мэйл.ру хранит все сессии одного пользователя на одном шарде, т.е. ключом шардинга является логин. Но сама сессия, т.е. идентификатор объекта – первичный ключ – это не ключ шардинга. То есть, не всегда так бывает, что идентификатор объекта – это ключ шардинга. И это бывает удобно, поскольку все хранится на одном шарде. Мы можем одного юзера, например, везде разлогинить, если мы подозреваем, что его пароль взломали и т.п. Мы можем легко этим управлять.
Вот пример хороших и плохих шард-ключей:

Алексей Рыбак: Мы к этому примеру будем еще неоднократно возвращаться, поэтому продолжим.
Если вы столкнулись с шардингом, то, скорее всего, это произошло в момент, когда вы наш доклад еще не слышали. Вы попытались что-то поискать в Интернете и ничего особенного не нашли. В течение последних, наверное, десяти лет многие команды прошли один и тот же путь изобретения велосипедов. Поэтому мы начнем рассмотрение наших паттернов или способов организации шардинга с некоторых наиболее распространенных и не самых плохих методов.
В качестве двух первых можно выбрать следующие.
Как правило, все начинается с одного сервера, и есть такой совершенно простой для, в том числе системного администрирования, метод – "йогурт системных администраторов". "Йогурт" – потому что он легкий и полезный.
Прежде, чем мы перейдем к этому способу, я хочу отметить: когда делается большая система, несмотря на то, что она начинается с одного-двух серверов, самое важное, когда она вырастает, это стоимость поддержки – сколько, условно говоря, проблем при эксплуатации всего этого хозяйства возникает. Поэтому удобство системного администратора – это ценность, которая должна стоять, наверное, на первом месте, когда проектируются подобного рода системы.
Итак, у вас есть один сервер, вы подняли реплику, среплицировали на него данные, через какое-то время распределили нагрузку, в том числе по записи, и думаете, что делать дальше. А дальше вы покупаете еще два сервера, у каждого из них появляется своя реплика. Почему реплика? Потому что с точки зрения системного администрирования это достаточно просто – вы настроили реплику, потом на какое-то время там запретили записи, таким образом, вы просто делитесь как амеба, которая изображена на этом рисунке:
Проблема заключается в том, что вам нужно все время удваиваться, а это будет очень дорого. Поэтому надо использовать что-то другое.
Есть некоторая комбинация, основанная на магических числах. Я здесь написал 48, на самом деле это лишь пример для идеи. Чем удобно число 48? Оно делится на 12, на 6, на 4, на 3. Вы можете начать с того, что на одном сервере будете держать 48 схем или 48 таблиц, порезанных изначально на такое число. После чего простыми для системного администратора операциями, дампами вы можете переливать какую-то часть данных на другие сервера. При этом, естественно, где-то у вас должна быть логика координации, о которой мы еще поговорим. Вот этот метод – использование каких-то специальных чисел, которые легко делятся – позволит вам достаточно легко расти, например, до 48-50 серверов.
Константин Осипов: Вообще, когда вы думаете о шардинге, нужно в первую очередь проанализировать вашу предметную область, т.е. что за данные у вас хранятся.
Данных не может быть гигантски много. Даже, если говорить обо всех людях на нашей планете, то это всего лишь 7-8 миллиардов. Это не так много. Допустим, если мы говорим обо всех рекламных объявлениях на каком-нибудь avito, то это тоже миллионы, но это не экстраординарные значения. Т.е. у вас есть потолок. Любая система растет, но ее рост замедляется по мере того, как она становится крупнее. Поэтому не всегда нужно брать какие-то самые сложные решения, чтобы все максимально масштабировать. Если вы знаете, что у вас будет максимум 10 серверов, возможно, вам нужно простое решение.
Еще хочу отметить, что всегда выбор шардинг-формулы (на слайде эта формула – мы просто делим пополам) связан с решардингом.
Алексей Рыбак: Каким же образом мы распределяем данные между ключами? Пока мы говорили со стороны переноса каких-то схем между серверами. Дальше возникает вопрос: а как мы, вообще, раскидываем данные? Выбрали ключ, раскидали данные по серверам. Здесь есть два самых крупных способа.
Первый способ – что-то похожее на хэширование. Оно не обязательно должно быть консистентным, т.е., грубо говоря, при добавлении новых серверов у вас множество ключей может очень сильно перетасоваться (это следующий момент, о котором мы поговорим). В любом случае, что вы делаете? Если это числовой ключ, его можно просто поделить на число серверов, получить остаток от деления – и это будет номер вашего сервера. Если это строковой ключ, например, e-mail, то от него можно взять числовой хэш, далее сделать то же самое.
Есть более "гаражные" методы – типа выбрать первую букву логина, но поскольку вы никак не определяете распределение логинов по буквам, вы должны изначально учесть распределение букв в языке, но это тоже достаточно сложно. Более того, если вы положите одну букву на один сервер, а потом одна буква в один сервер не влезет, то вам нужно будет очень сильно изменять конфигурацию для того, чтобы потом эту букву раскидать. Очень плохая идея. Я бы сказал, что это антипаттерн.
Обозначим только одну проблему, которая при хэшировании имеет место быть. Это добавление новых серверов. Что у вас происходит при решардинге с точки зрения саппорта? У вас вылетает нода, вам нужно поднять из реплик мастер-ноду для этой части и сделать это максимально быстро. Второе – у вас просто нагрузка выросла, вам нужно докупить новые сервера и максимально быстро ввести их в строй. Соответственно, решардинг является ключевой проблемой.
Если вы просто берете остаток от деления, то появляется большее количество серверов, все хэши "переразмазываются", все ключи, все данные нужно передвинуть. Это очень тяжелая и плохая операция. Она работает, когда вы держите все в памяти.
Например, у нас есть кластер memcached в Badoo. Мы распределили все по остатку от деления, добавили новых серверов (это происходит не так часто), и через, может быть, 5-10 минут все данные пересортировались. Все это происходит достаточно быстро, без особых проблем, потому что передвинуть данные по сети и положить в память другой машины – это фигня.
Если у вас данные юзеров лежат на диске, например, переписка какая-то и т.п., то это значительно более сложная вещь.
Константин Осипов: Есть шардинг «для взрослых». И это вторая часть нашего доклада.

Что это такое? Рано или поздно появляется такая идея, что у нас, вообще, все есть облако, и мы хотим сделать так, чтобы наша база данных эластично масштабировалась. Наша схема шардинга должна быть ровно такой, чтобы нам не приходилось думать обо всех этих маленьких деталях. Это очень заманчиво.
Мы сейчас попробуем посмотреть, возможно это или нет. Мы разберем, как это работает, и вы сами сделаете выводы.
Алексей Рыбак: Здесь есть два очень принципиальных момента, два метода. Мы рассмотрим один из них – Table functions.
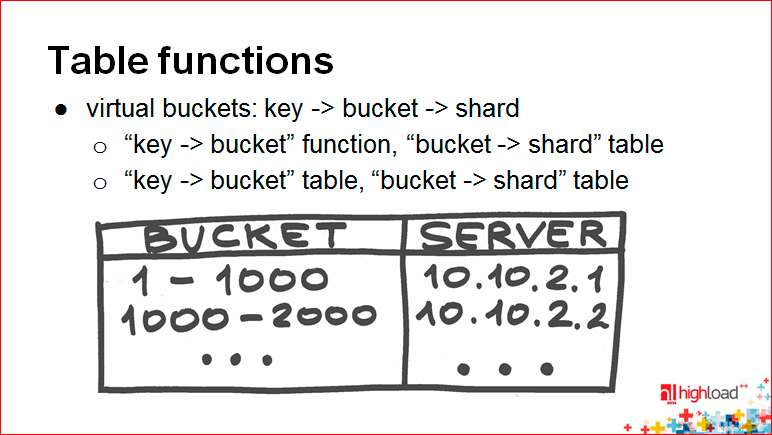
Это всего лишь табличная функция.
Напомню, одна из важных задач этого доклада – договориться, в том числе, и о терминах. Я, например, раньше использовал другие слова для обозначения этого. Я разделял методы на детерминированные, т.е. когда есть некая математическая формула, и недетерминированные, когда можно свободным образом конфигурировать, куда маппится тот или иной ключ.
По большому счету, это и есть табличная функция и консистентное хэширование.
Table functions – это когда у вас просто какой-то config. Использование подходов Table functions к шардингу очень тесно завязано на таком понятии как virtual bucket.
Вспомните, у вас есть функция отображения ключа на шард. Представьте себе, что у вас посередине появляется некое промежуточное отображение, т.е. это отображение превращается в два. Сначала вы отображаете ключ на некоторый виртуальный bucket, потом виртуальный bucket – на соответствующую координату в пространстве вашего кластера.
Существует не очень много методов это все сделать. А еще мы помним о том, что самое главное – это дать свободу и удобство работы системному администратору.
Виртуальные bucket-ы, как правило, выбираются в достаточно большом количестве. Почему они виртуальные? Потому что на самом деле они не отражают реального физического сервера. И используется несколько методов для отображения непосредственно ключа на шард.
Один метод – это когда первая часть «key to bucket» function – это просто какой-то хэш или консистентный хэш, т.е. какая-то часть, которая определяется по формуле, а bucket непосредственно на шард отображается через config.
Вторая вещь более сложная – когда вы и то, и то отображаете через config. Более сложная, потому что вам, условно говоря, для каждого ключа нужно еще помнить, где он лежит. Вы приобретаете возможность передвинуть любой ключ куда угодно, но с другой стороны вы теряете возможность легко и быстро, имея просто маленький config в «bucket to shard», из ключа определить bucket и потом пойти достаточно быстро пойти в нужное место.
Константин Осипов: Почему эти варианты, вообще, возникают? Мы сейчас будем говорить о роутинге и о решардинге. Здесь все, в принципе, красиво, удобно, полностью управляемо, но у вас появляется некое состояние. Это состояние вам нужно где-то хранить, его нужно менять. У вас увеличилось количество серверов, вам нужно поменять ваши таблицы. Тут есть два подхода: первый – вы забиваете на то, что у вас есть состояние, пытаетесь этим состоянием управлять; второй подход – вы пытаетесь максимально математизировать вашу формулу, и тогда у вас максимально детерминировано, без какого-либо состояния можно определить, куда идти при роутинге.
Вот один из подходов, который позволяет как-то функционально описать схему шардинга. Это подход с консистентным хэшированием.
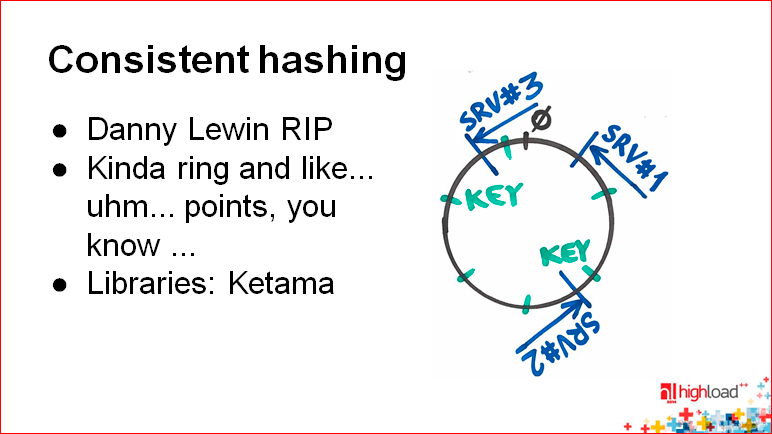
Сначала расскажу, как он устроен. Мы представляем, что весь диапазон нашей хэш-функции отображается не на прямую от 0 до 232 (~ 4 млрд.), а на кольцо. Т.е. у нас 4 миллиарда находится примерно там же, где 0, мы, как бы, завязываем нашу прямую.
Если мы просто используем хэш-функцию, мы должны при добавлении новых узлов все это перехэшировать. Получается так, что у нас используется остаток от деления на количество узлов.
А здесь мы не используем остаток от деления на количество узлов. Мы делаем так – мы хэш-функцию, возможно другую, применяем и к идентификатору сервера, и также располагаем сервера на этом кольце. Таким образом, получается, что каждый сервер отвечает за некий диапазон ключей после него на кольце. Соответственно, когда вы добавляете новый сервер, он забирает те диапазоны, которые находятся перед ним и после него, т.е. он частично делит диапазон. Не требуется перетасовки всего абсолютно.
Алексей Рыбак: Я, когда давно это услышал в первый раз, я все равно ничего не понял. Если и вам ничего не понятно, не страшно.
Идея здесь такая: в консистентном хэшировании при добавлении новых нод вы перетасовываете только небольшую часть ключей. И все.
Как это сделано, можете посмотреть по соответствующим ключевым словам.
Константин Осипов: Еще пара слов о недостатках этой истории с хэшированием. Речь, все-таки, идет о неких случайных величинах. Хэш-функция – это некий рандомизатор, он берет ваше естественное значение, дает вам рандомное в ответ на это. Все случайно выпадает куда-то на кольцо. И это не обеспечивает в простом случае идеального распределения, т.е. у вас может так получиться (см. на картинке), что сервер №3 находится рядом с сервером №1, а между серверами №2 и №3 такое большое полукольцо – практически половина данных.
Для того чтобы консистентное хэширование работало правильно, еще нужно добавлять некое состояние в виде виртуальных bucket-ов, таблиц отображения. А виртуальные bucket-ы нужно где-то хранить. Маппинг между виртуальными bucket-ами и серверами. Т.е. у вас появляется состояние. Это не чистая математика.
У нас есть еще один интересный слайд с ключевым словом Guava/Sumbur:
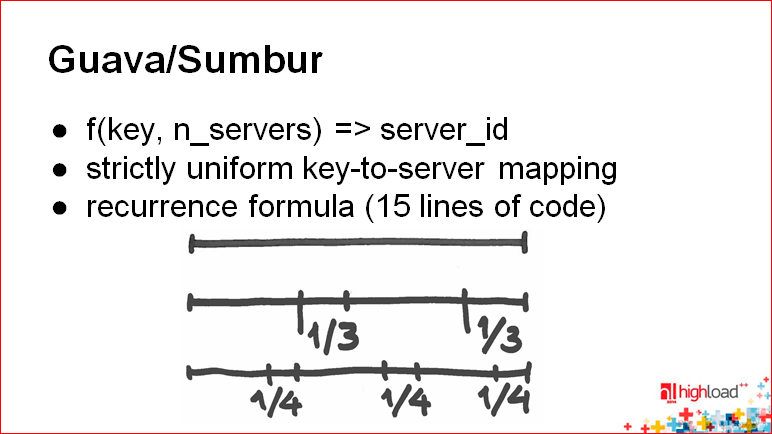
Идея Guava – у вас исчезает состояние, вообще. В принципе, это функция, которая берет ключ и количество серверов, а выдает вам server_id. Когда вы на это смотрите, вы понимаете, что на самом деле шардинг-функция – это именно вот такая история – отображение ключа и количества серверов на server_id.
У вас отношение к решардингу может поменяться. Вы думаете, что решардинг – это полное изменение перераспределения, и непонятно, как находить данные между старыми и новыми шардами, что делать во время решардинга.
Главная идея таких математических функций – это то, что вы всегда можете попробовать новую схему шардинга практически при любом распределении данных между нодами в кластере. Попробовав эту схему, если не получилось, т.е. вы не нашли ключа, вы можете попробовать предыдущую. Если и предыдущая не подошла, то вы точно знаете, что ключа нет.
Вторая тема, которую мы разбираем, – это, собственно, роутинг, т.е. то, каким образом мы можем искать нужные ключи в нашем мегакластере.
Алексей Рыбак: На самом деле это вопрос о том, каким образом организована архитектура вашего приложения, какие компоненты за что отвечают.
По большому счету, здесь есть три самых распространенных метода.

Мы написали пять, но самых распространенных – три:
- это «Умный клиент»;
- прокси;
- координатор
и еще парочка "извращений".
«Умный клиент» – это очень просто.
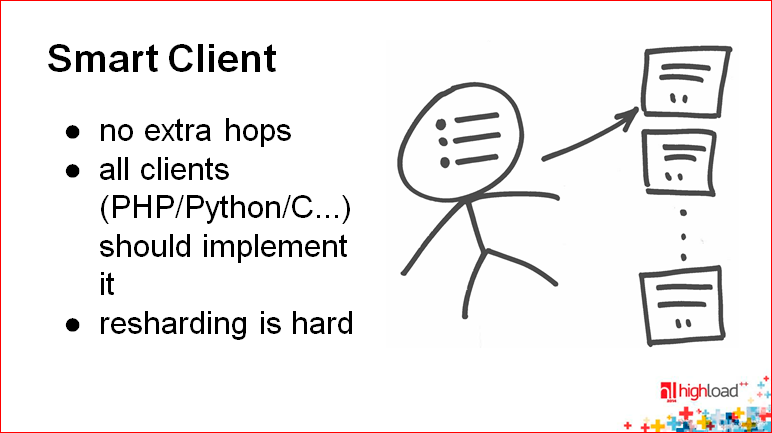
Представьте себе, что у вас есть табличная функция, которая использует маппинг ключа на bucket. Используется какой-то хэш, какая-то формула. Затем у вас есть некоторый config, который состоит из всего лишь небольшого количества данных, например, 1000 маппингов, 1000 строк, 1000 соответствий ключ-значение. В результате, это все где-то зашито в ваш клиент. Ваш клиент получил ключ, сразу определил, на какой сервер идти, и сразу пошел на этот сервер.
В принципе, хороший метод, самый простой и самый клевый. За одним исключением – в случае, если у вас разрастается инфраструктура, и вам в какой-то момент нужно задевелопить кучу других каких-то клиентов, на других языках, для других приложений, то вам нужно повторить эту логику – это во-первых. Во-вторых, если вам нужно сделать каким-то образом решардинг, и сделать это с нулевым maintenance subwindow, то это сделать довольно сложно, потому что вся логика – в процессах приложений, которые сейчас работают. Каким-то образом вам надо сигнализировать, что что-то сейчас будет меняться, карта такая-то будет становиться другой и т.д. Все это, в общем, достаточно сложно.
Дальше простая история – это прокси.
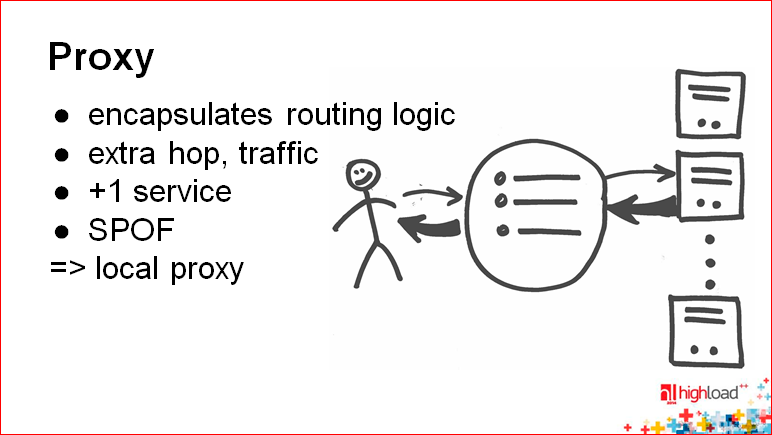
Прокси – это программистская мечта.
Константин Осипов: В принципе, какова логика мышления? Вы начинаете с клиента, потом у вас что-то начинает не получаться, и вы говорите: «Ага, прокси! Давайте эту логику унесем с клиента и вынесем ее в прокси».
Алексей Рыбак: Есть некоторое количество продуктов и подходов, в том числе в highload-программировании (будем это так называть), где речь идет о том, что «Я – девелопер, я не хочу ничего решать, ничего думать. Вот есть у меня объект, я хочу его сохранить. Я бы хотел, чтобы у меня это работало одним простым API, и не думать, потому что мне же надо еще делать продукт, а тут какие-то сложности... Мне это не интересно».
Есть некоторое количество решений, которые эксплуатируют именно вот это желание девелопера. И прокси, в некотором смысле, отражает следующую идею: «ОК, ты работал с одной базой, ты будешь продолжать работать с одной базой».
Это, в принципе, не обязательно. Не каждый прокси должен отвечать этим условиям.
Представьте себе, что прокси делает следующее: он принимает запрос, как будто к одной ноде, вернее, как будто к одному приложению, и клиент просто не знает о том, что на самом деле за этим прокси есть много нод.
Какая-то логика применяется внутри прокси, он определяет, на какую ноду идти, делает запрос, получает данные, потом передает эти данные назад клиенту. Это очень удобно, хотя бы потому, что ничего специально учить не надо, разговаривать можно как с одной базой, как мы привыкли, и если у нас есть какие-то клиентские приложения, которые уже написаны, нам их переписывать не надо.
Жирные стрелочки на этом слайде указывают, где потекли данные. Например, видно, что жирные данные текут уже в два места. Одно место – это между прокси и, собственно, нодой данных. Другое место – это между прокси и клиентом.
Для больших производительных систем это является неким дополнительным условием, которое надо иметь в виду – удвоение трафика внутри площадки.
Константин Осипов: Прокси перегружается. Вы увеличиваете их количество. Прокси выходят из строя, у вас появляется еще одна точка отказа. Решение неидеальное, но какой еще потенциальный профит у этого решения? Вы в прокси можете также заниматься load balancing-ом, вы можете смотреть, какие ноды у вас вышли из строя, т.е. автоматически определять, делать failover полностью прозрачным для прокси. Т.е. прокси позволяет сделать логику приложения очень простой.
Есть некий способ упростить всю эту технологию, если сделать так чтобы прокси работала на том же хосте, на котором работает само приложение.
Еще одна проблема прокси – вы должны распространять состояние шардинга, т.е. прокси должны знать, где какой ключ находится. И тут мы приходим к следующей технологии, которая упрощает именно эту историю – технологии вынесения этого состояния в единое место – в координатор.
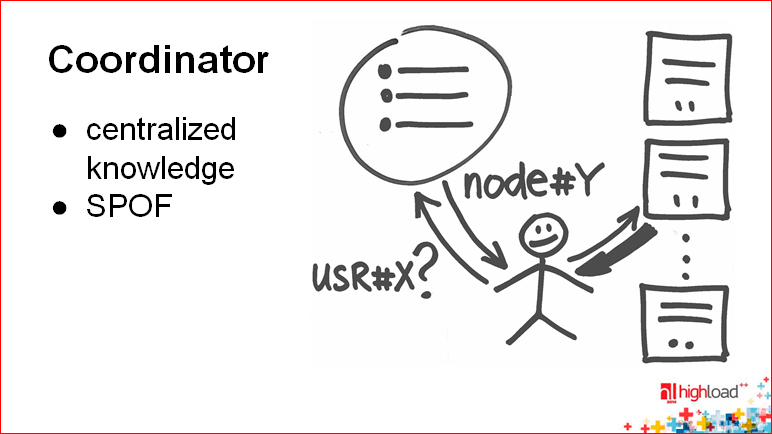
Алексей Рыбак: Координатор – это вещь, похожая на предыдущие (т.е. клиент, по- прежнему, ничего не знает), но совершенно другая. Координатор – это просто такой классный парень, который очень быстро отвечает на простые вопросы «Куда мне идти?». Получает маленькую порцию вопросов, т.е. длина вопроса небольшая, быстро дает ответ, после этого клиент сам устанавливает соединение и идет на нужную дата-ноду. Здесь преимущество заключается в том, что у вас убирается сложность прокси.
Сам по себе координатор можно собрать «на коленке». Это может быть какой-то высокопроизводительный сервер с базой данных, специальным образом приготовленный. Может быть специализированная база данных. Может быть какая-то in-memory БД.
Запрограммировать прокси – это очень трудоемкая задача, а координатор запрограммировать – это, условно говоря, день работы.
Эта архитектура обладает определенными проблемами. Если координатор вдруг упадет, то все пропало. Но с другой стороны, координатор – вещь крайне простая и ее очень легко резервировать через асинхронный мастер-мастер, даже мастер-слэйв.
Константин Осипов: Представим, что мастер у координатора упал, у вас система по-прежнему остается доступной, просто вы не можете делать сложные вещи типа решардинга, добавления узлов, т.е. это не так страшно.
Алексей Рыбак: Если у тебя используются табличные функции, где для каждого (даже пользователя) сохраняется его место, то координатор является некоей базой данных, которая всегда должна быть открыта на запись. В противном случае у тебя перестает работать регистрация.
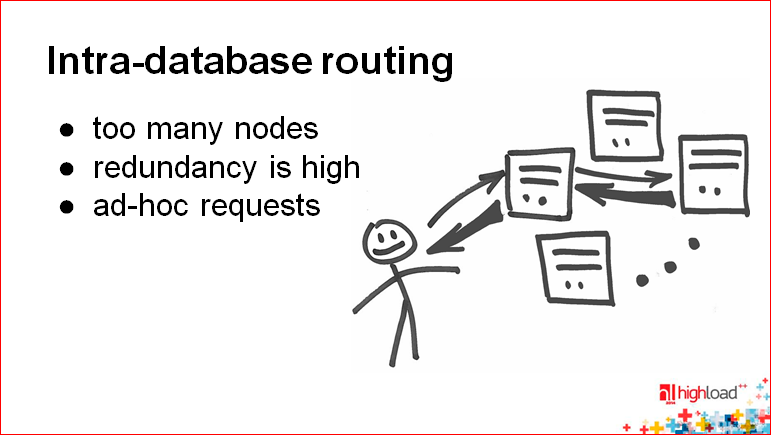
Константин Осипов: А здесь уже мегасложная история. Допустим, вы не хотите, чтобы у вас были прокси, и хотите, чтобы база данных была очень умная и сама все роутила. Представьте себе торренты – это будет очень похожая аналогия. Т.е. нод очень много, данных очень много. Вы не знаете состояние всего кластера, потому что постоянно меняются ноды. Тогда вы можете использовать роутинг внутри вашего кластера, внутри самой базы данных.
Идея такая – если я знаю своих соседей и какой-то другой узел в кластере, который не является моим соседом, то я могу всегда найти то место, где лежит мой ключ. Т.е. на любую ноду приходит ключ, если он знает хотя бы о двух своих непосредственных соседях и, допустим, о рандомном узле в этом облаке. Он может посмотреть, его ли это ключ, ключ ли это его соседей слева и справа. Если нет, то он форвардит его той ноде, которая является рандомной. Этот процесс сходится за логарифмическое время, и получается не так много хопов.
Такие технологии используются в очень больших базах данных, где у вас 100 тысяч узлов и более, и вы не можете где бы то ни было хранить эту информацию.
Так работает, например, Redis. Они сделали форвардинг запросов для того, чтобы упростить клиента.
Также это может быть актуально, если вы хотите, чтобы у вас все работало, как прежде, т.е. хотите сохранить совместимость. В этом случае сама БД выступает как прокси.
Мы подходим к теме решардинга.

Почему огурчики? Представьте, что вы упаковали все по баночкам. И тут выясняется, что вам нужно все это переделывать. Вот это примерная история про решардинг.
Алексей Рыбак: Почему решардинг важен, мы уже сказали. На самом деле ре-шардинг это всегда больно, потому что нужно передвигать огромное количество данных. Можно говорить о том, что это будет аффектить клиента, сеть. Передвижение больших данных – это всегда достаточно большое окно – время, на которое мы должны выключить какую-то часть системы. При этом клиенты не должны этого заметить.
Константин Осипов: Можно придумать онлайн-решардинг. Это не так страшно, но, все равно, возникают проблемы с консистентностью данных. Т.е. у вас данные какой-то короткий момент времени, какой бы он ни был маленький, живут на двух узлах, и вам нужно на этот маленький момент времени, что называется, не облажаться. Один из узлов может выйти из строя, а вы можете забыть, где это было. Даже если вы – это какой-то крупный продукт, эти проблемы точно так же возникают, просто как они решаются – вы этого не видите, это находится «под капотом».
Алексей Рыбак: Здесь очень важно понимать простую вещь, что решардинг идеален, если вы, вообще, не двигаете данные, т.е. если вы ничего не делаете, то вы и не облажаетесь.
Константин Осипов: Но и двигать просто бывает невозможно. Если у вас одна нода, допустим, терабайт данных, то добавление новой ноды, куда бы вы ее ни добавили, это, в первую очередь, сеть. У вас может просто лечь та стойка, в которой находится эта нода. Поэтому не всегда решардинг, в принципе, возможен.
Если мы говорим, что есть какие-то супер продукты, которые решают, вообще, всю головную боль от нуля до бесконечности нод, то это неправда, потому что рано или поздно они встанут, в том числе, в эту проблему.

Алексей Рыбак: Итак, мы говорим о том, что передвигать данные – плохо. Какие паттерны и и принципы можно использовать для того, чтобы данные не передвигать вовсе?
Константин Осипов: Самые успешные внедрения – это внедрения, которые каким-то образом обходятся без автоматического или ручного решардинга, т.е. админы, вообще, не думают об этом. Об этом думает только девелопер.
Один из подходов – «update is a move». Идея следющая – всегда, когда вы меняете кокой-то ключ, вы его неявно двигаете. Допустим, у вас ключ шардинга – это, собственно, ключ шардинга и timestamp. Когда вы меняете данные, вы меняете timestamp, и он у вас естественным образом оказывается на другом шарде. Вы можете в какой-то момент закрыть апдейты на определенный шард и рано или поздно просто его вывести из строя. Т.е. очень просто передвигать данные, очень просто выводить данные из строя.
Такую идею мы собираемся использовать в хранении почтового индекса в мэйл.ру, когда мы индексируем те слова, которые используются в определенном e-mail-е. Есть юзер, есть e-mail (почтовый ящик), и есть список слов-идентификаторов. Мы из этого строим обратный индекс, т.е. у нас шардинг идет по юзеру и по слову, и мы добавляем к этому timestamp.
Когда определенным юзерам приходит почта, мы должны обновить обратный индекс, соответственно, обновить определенные слова. Они при этом могут переехать на новый шард. Таким образом, это все может расти.
Если же у вас большие таблицы, большие объекты, конечно же, вы не будете двигать их каждый раз.
Алексей Рыбак: Решение действительно неплохое, но представить себе, что вам нужно собирать теперь эти данные, делать поисковый запрос, а ты не можешь пойти в какую-то одну конкретную ноду… Нужно делать что-то сложнее.
Константин Осипов: Второй подход – «data expiration».
Аексей уже рассказал о memcached в Badoo. В нем просто добавили несколько серверов, явно не решардили, данные естественным образом заэкспайрились – получилась новая схема шардинга.
Этот же подход можно использовать где угодно, где вы можете старые данные просто удалять. Тогда вы новые данные льете на новые ноды или закрываете какие-то старые ноды. Данные сами собой просто постепенно переезжают.
Алексей Рыбак: Здесь ключевым моментом являются части – горячая и холодная. Автоматически появляются на вашем кластере горячая и холодная части, и может оказаться, что если вы неправильно подобрали какие-то конфигурации или веса, то горячая часть будет очень маленькой, и число серверов, которые вам нужно постоянно добавлять для того, чтобы поддерживать горячую часть (например, если это на twitter или выборы Обамы)...
Константин Осипов: Была такая история, что в twitter изначально новые твитты лились на новые ноды. Когда у них резко возросла нагрузка, потому что люди просто стали больше твиттить, они внедряли один сервер в неделю, потом понадобилось два сервера в неделю... В какой-то момент у них админы просто зашивались, потому что твитты генерировались очень активно, и постоянно нужно было добавлять новые сервера – уже пачками. В итоге они ушли от этой схемы и теперь старые твитты хранят вместе с новыми.
Алексей Рыбак: Холодная часть оставалась достаточно большой, в результате очень большая часть кластера, которая могла бы быть использована, просто не использовалась.
Третий паттерн здесь очень простой. Он используется в Badoo, и, скорее всего, в гигантском количестве других мест. Вы добавляете новые сервера и на некоторое время новых пользователей льете только на них.
Это имеет смысл особенно для нашего проекта – у нас есть определенное время жизни юзера, т.е. он приходит на сайт Badoo и живет там какое-то время – кто-то год, кто-то полгода. Очевидно, если проект живет 10 лет, то за это время было несколько поставок «железа». Что мы делаем? Мы добавляем новое «железо», в конфигураторе говорим, что на старые сервера временно новые данные (новых пользователей) не регистрируем. Новые пользователи начинают заполнять новые машины, в результате через какое-то время мы видим, что нагрузки более-менее сравнялись. После этого мы открываем регистрации на старые сервера, и таким образом в ручном режиме (не каждодневно, может быть, раз в месяц, в несколько месяцев) просто распределяем нагрузку.
Мы называем этот паттерн «Новые данные на новые сервера». На самом деле, это временно новые данные на новые сервера, потом вы новые данные льете везде.
Константин Осипов: Тема, которую мы не будем подробно рассматривать – это наличие схемы и изменения в пошарденных данных. Какие-то БД сейчас schema-less, но в целом это отдельная серьезная тема, о которой тоже стоит думать админам.
Алексей Рыбак: Огромное количество людей спрашивают про это – а как сделать так, чтобы вы поддерживали схему? Большая часть людей говорит о том, что они думают над сложно версионированной схемой и т.д.
Здесь есть очень простой подход, который работает почти на всех задачах. Первое – нужно сначала затюнить ваше приложение таким образом, чтобы оно работало и на старой и на новых схемах. После этого вы апгрейдите базу данных, потом еще раз меняете приложение, избавляясь от старья, от предыдущей версии и в приложении и в БД. Также выпиливаете все, что вам при этом сказал мониторинг.
Ну, в общем, все.
Вопрос из зала: Я слышал о добавлении timestamp-а в обратный индекс. Непонятно – зачем? Т.е. я ищу какое-то слово в своей почте, откуда я знаю, когда она ко мне пришла? Как идти на ноду?
Константин Осипов: Timestamp используется просто для того, чтобы это автоматом переехало. Это используется в ключе шардинга, но не при поиске. При поиске другой индекс, т.е. когда делается поисковый запрос, то не используется эта часть. Она используется, условно говоря, при апдейте.
Вопрос из зала: Но мне индекс нужен для того, чтобы искать потом. Обратный.
Алексей Рыбак: С индексом все нормально. Вопрос: где это все лежит? Вся проблема в том, что не происходит координации на какую-то конкретную ноду. Идет запрос параллельно со всего кластера. На самом деле, это выбор между двумя архитектурами большого распределенного поиска. Это отдельная тема.
Один способ – это ты пытаешься все уложить на одну ноду и достать с нее. Он не работает на больших масштабах.
Другой способ – когда ты все "размазал", со всех собрал, потом начинаешь релевантность высчитывать, сортировать и отдаешь клиенту.
Вопрос из зала: Timestamp не является ключом шардинга?
Константин Осипов: Нет, не является.
Вопрос из зала: Newdata – он не сервер. А как это согласуется с sharding function?
Алексей Рыбак: Это согласуется с sharding function следующим образом. Конкретно для случая Badoo. Мы не используем никаких формул. Как только вы используете формулу, вы не можете передвинуть отдельного пользователя между двумя местами. И у нас встала задача, где нужно конкретных пользователей двигать между дата-центрами, для того чтобы пользователь, который из Европы полетел в Америку, проснулся утром и начал пользоваться сайтом Badoo быстро, но в новой теме, в новой страyе.
Мы sharding function не используем, у нас все хранится в соответствии один к одному. Это означает, что вы добавляете новые сервера, а ваш код определяет, куда можно регистрировать, получает при регистрации идентификатор нужного шарда и заносит эти данные туда.
Я вам рассказал, как это сделано в Badoo. Теперь представим себе, что вам нужно все уложить в один дата-центр. Тогда вы можете использовать функцию для маппинга на bucket, а bucket на шард будет маппиться config-ом. Вы в этот config можете внести информацию о том, что на такие-то bucket-ы регистрация запрещена. Вы сначала раскладываете этот код, туда же вы добавляете новые bucket-ы, на которые регистрация разрешена, и они маппятся на новые сервера. Через какое-то время опять раскладываете этот код.
В любом случае сделать это через одну-единственную функцию, например, консистентного хэширования или еще как-то, невозможно. Поэтому всегда используются комбинированные подходы.
Вопрос из зала: Был слайд про шардинг на уровне БД, т.е. когда база данных сама понимает, где что лежит, раскладывает все... Есть какие-то успешные кейсы реально больших систем, где все это хорошо работает?
Константин Осипов: Кейсы есть.
Во-первых, если у вас все-таки не очень большие ключи и не очень большие значения, то это может работать успешно. Если у вас не очень большое приложение, т.е. вам нужно «из коробки», но все-таки на несколько узлов – на один узел не умещается, то вы можете использовать все автоматические системы – и Redis, и Mongo – все, что сейчас заявляют, что у них есть автоматический шардинг. Это не значит, что это не работает. Это работает. Оно есть в Cassandra, Hadoop, Mongo, Redis Cluster. В Tarantool-е скоро будет.
Если у вас управляемое внедрение, не очень большое – это первый случай в вашей нише. Если у вас, наоборот, сверхбольшой, вы полностью понимаете, как работает эта система – это тоже ваш случай. А где-то посередине, не имея экспертизы продукта, вы легко можете упереться в ограничения этого продукта. Т.е. вы должны знать, как это все работает, тогда вы можете этим управлять.
Но, в целом, это тренд и, как и машины с автоматической коробкой передач – рано или поздно это будет везде.
Алексей Рыбак: Это, к сожалению, правда. Потому что я представляю девелоперское комьюнити, которое все это изобретало, делало своими руками с помощью грязи и палок. И вот, через какое-то время появляются какие-то продукты, которые что-то о себе заявляют. Первое время ты думаешь: «Да что вы умеете? Я уже это все давно прошел». А они взрослеют, после этого ты понимаешь, что все это есть «из коробки», и те знания, которыми ты обладал – они уже не нужны, потому что все это уже делается какими-то продуктами.
Я думаю, что у нас есть еще несколько лет. Пока того, что работает идеально, в этой сфере нет, но оно очень скоро появится.