Масштабируемая конфигурация nginx
Публикуем доклад постоянного члена Программного комитета HighLoad++ Игоря Сысоева, разработчика веб-сервера nginx, на котором работают почти 20% мировых веб-сайтов.
Одно из предназначений nginx - стоять в качестве легковесного фронтенда, обрабатывая простые запросы и проксируя запросы, требующие вычислений на бекенды. Nginx также способен кешировать и осуществлять балансировку между бекендами. Подробнее о трёхзвенной архитектуре читайте в нашей рассылке в статье "Общая логика масштабирования".
Меня зовут Игорь Сысоев, я автор nginx и сооснователь одноименной компании.
Немного о нашей компании. Основана она была в 2011 г., летом мы открыли московский офис, осенью в Сан-Франциско мы объявили о создании компании и получении финансирования, тогда же у нас появился первый коммерческий клиент – Netflix. Летом 2013 г. мы выпустили наш первый коммерческий продукт, весной 2014 г. мы провели первую конференцию в Сан-Франциско, а осенью – вторую конференцию, приуроченную к 10-летию первого выпуска nginx'а.
Среди наших крупных клиентов – Google Air (wi-fi, предоставляемый на борту самолетов компании Deltа в США), Home Depot и Discovery Education. У нас два офиса, один в Сан-Франциско, второй – в Москве. Офис в Сан-Франциско занимается продажами, бизнес-девелопментом, маркетингом, presales и product mаnаgement'ом, а в Москве идет разработка ПО и его поддержка.
Наши продукты:

Мы продолжаем разработку open source. С момента основания компании темпы разработки существенно увеличились, поскольку над продуктом работает множество людей. В рамках open source мы оказываем платную поддержку.
NGINX+ – наш второй продукт, коммерческий, закрытый. Он основан на open source плюс несколько коммерческих модулей. Детальное описание вы можете посмотреть на https://www.nginx.com/.
Переходим к теме. Я буду говорить о масштабируемой конфигурации nginx, но это не о том, как обслужить с помощью nginx сотни тысяч одновременных соединений, потому что nginx для этого настраивать не надо. Нужно выставить адекватное число рабочих процессов или поставить его в режим "авто", поставить worker_connections в 100 000 соединений, после этого заниматься настройкой ядра – это гораздо более глобальная задача, чем просто настройка nginx. Поэтому я буду рассказывать о другой масштабируемости – о масштабируемости конфигурации nginx, т.е. о том, как обеспечить рост конфигурации от сотни строчек до нескольких тысяч и при этом тратить минимальное (желательно константное) время на сопровождение этой конфигурации.
Почему, собственно, возникла такая тема? Около 15 лет назад я начал работать в Рамблере и администрировал сервера, в частности, apache. А у apache есть такая неприятная особенность, которая хорошо иллюстрируется следующими двумя конфигурациями:

Здесь два location'а и они идут в разном порядке. Один и тот же запрос, в зависимости от того, какая конфигурация используется, будет обработан разными файлами – либо php-файлом, либо html-файлом. То есть при работе с конфигурацией apache порядок имеет значение. И отменить это нельзя – apache при обработке запросов проходит по всем location'ам, пытается найти те, которые совпадают каким-то образом с этим запросом, и собирает конфигурацию из всех этих location'ов. Он сливает ее и, в конце концов, использует результирующую.
Это удобно, если у вас маленькая конфигурация – так можно сделать ее еще меньше. Но по мере роста вы сталкиваетесь со следующими проблемами. Например, при добавлении нового location'а в конце все работает, но после вам нужно поменять конфигурацию в середине или выкинуть неактуальный location из середины. Вам нужно просмотреть всю конфигурацию после этих location'ов, чтобы убедиться в том, что все продолжает работать как раньше. Таким образом, конфигурация превращается в карточный домик – вытащив одну карту, мы можем порушить всю конструкцию.
В apache чтобы добавить аду в конфигурацию есть еще несколько секций, которые работают точно так же, они обрабатываются в разном порядке, но из них всех собирается одна результирующая конфигурация. Все это делается в runtime, т.е. если у вас много модулей, то в каждом модуле будет происходить слияние конфигураций (это частично объясняет, почему nginx в некоторых тестах быстрее apache – потому что nginx в runtime конфигурации не сливает). Часть этих секций и большинство директив можно разместить в .htaccess файлах, которые раскиданы по всему сайту, а для того чтобы сделать жизнь вашу и ваших коллег еще «интересней», эти файлы можно переименовать, и ищите эту конфигурацию...
А «вишенкой на торте» являются RewriteRules, которые позволяют сделать конфигурацию похожей на sendfile. Немногие оценили юмор, т.к., к счастью, большинство уже не знают, что это такое.
RewriteRules – вообще кошмар. Очень много администраторов приходят не столько с бэкграундом apache, сколько с бэкграундом администрирования apache на разделяемом хостинге, т.е. когда единственным средством администрирования был .htaccess. И в нем они делают очень замысловатые RewriteRules, которые очень тяжело понимать и в силу синтаксиса, и в силу логики.
Это был один из недостатков apache, который меня очень раздражал, он не позволял создавать достаточно большие конфигурации. В ходе разработки nginx я хотел изменить это, я исправил много раздражающих черт apache, добавил своих собственных. Вот так выглядит предыдущий пример в nginx:

В отличие от apache, вне зависимости от порядка location'ов запрос будет обработан одинаково, т.к. nginx ищет максимально возможное совпадение с префиксным location'ом, не заданным регулярным выражением, и после этого выбирает этот location. Используется конфигурация выбранного location'а, а все остальные location'ы игнорируются. Такой подход позволяет писать конфигурации с сотней location'ов и не думать о том, как это будет влиять на все остальное, т.е. получаем своего рода контейнеры. Вы изолируете обработку в одном небольшом месте.
Рассмотрим, как nginx выбирает конфигурацию, которую он будет использовать при обработке запроса. Первым делом ищется подходящий подзапрос сервера. Выбор осуществляется на основе сначала адреса и порта, а затем всех привязанных к данным адресу и порту имен серверов.
Если вы хотите, допустим, разместить сервер на нескольких адресах, написать там много имен серверов, и хотите, чтобы все эти имена серверов работали на всех адресах, то вам нужно адреса продублировать на всех именах. После того, как выбран сервер, внутри сервера ищется подходящий location. Сначала проверяются все префиксные location'ы, ищется максимальное совпадение, потом проверяется, существуют ли location'ы, заданные регулярными выражениями. Поскольку для регулярных выражений мы не можем определить максимальное совпадение, то выбирается location, у которого регулярное выражение совпало самым первым. После этого используются имена конфигурации этого location'а. Если не совпало ни одно регулярное выражение, то используется конфигурация, которая была найдена до этого, с максимально совпадающим префиксом.
Регулярные выражения добавляют зависимость от порядка, таким образом, создавая плохо поддерживаемые конфигурации, потому что жизнь сложнее теории, и очень часто структура сайта – это такая свалка из кучи статических файлов, скриптов и т.д., и в этом случае единственный способ разрулить все запросы – это регулярные выражения.

На этом слайде иллюстрация того, как делать не нужно. Если у вас такие сайты уже есть, то их нужно переделывать.
Когда я рассказывал о порядке обработки конфигурации, это был первоначальный дизайн. Потом появилась возможность описывать location'ы внутри location'а, т.е. инклюзивные location'ы, и порядок немного адаптировался. Т.е. сначала ищется максимально совпадающий префиксный location, потом внутри него ищется максимально совпадающий префиксный location. Такой вот рекурсивный поиск продолжается, пока мы не дойдем до location'а, в котором ничего уже нет.
После этого мы начинаем проверять location'ы с регулярными выражениями в обратном порядке, т.е. мы вошли в самый вложенный location, смотрим, есть ли там регулярное выражение. Если нет, то спускаемся на уровень ниже и т.д. Опять же, первый совпавший location с регулярным выражением "побеждает". Такой подход позволяет сделать такую обработку:
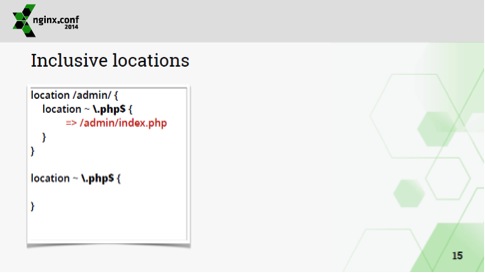
У нас тут есть два location'а с регулярными выражениями, но для запроса /admin/index.php будет выбран вложенный первый location, а не второй.
Кроме того, вторую часть поиска регулярных выражений можно запретить, если пометить location символом ^~:
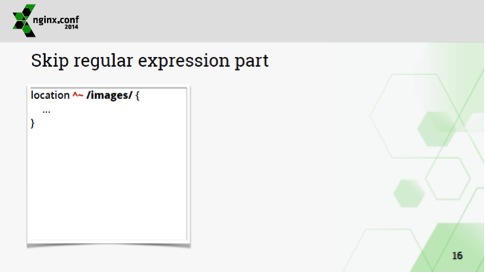
Такой запрет означает, что если этот location показал максимальное совпадение, то после него регулярные выражения искаться не будут.
Очень часто люди пытаются сделать конфигурацию меньше, т.е. они выносят какую-то общую часть конфигурации и просто перенаправляют туда запросы. Вот, например, очень плохой способ перекинуть все в обработку php:
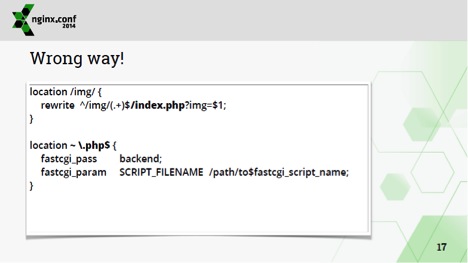
В nginx есть другие методы выделения общих частей конфигурации. Прежде всего, это наследование конфигурации с предыдущего уровня. Например, здесь мы можем написать на уровне http включить sendfile для всех серверов и всех location'ов:

Эта конфигурация наследуется во все вложенные сервера и location'ы. Если нам нужно где-то отменить sendfile, потому что, допустим, файловая система его не поддерживает или по каким-то другим причинам, то мы можем его выключить в конкретном location'е или в конкретном сервере.
Или, например, для сервера мы можем написать общий root, где нужно его переопределить.
Этот подход отличается от apache тем, что мы знаем конкретные места, где нужно искать общие части, которые могут повлиять на наш location.
Единственное, что нельзя делать разделяемым, – например, на уровне http нельзя описывать location'ы. Это было сделано сознательно. В apache это можно делать, но доставляет немало проблем при использовании.
Лично я предпочитаю описывать location'ы явно прямо в конфигурации. Если вам не хочется этого делать, то вы можете его инклудить через внешний файл.

Теперь я хотел бы поговорить о том, почему люди хотят писать меньше, т.е. почему они шарят разделяемые конфигурации. Они полагают, что потратят меньше сил. На самом деле, люди хотят не столько меньше писать, сколько меньше тратить времени. Но о будущем они не думают, зато считают, что, если они сейчас напишут меньше, то так же будет и дальше...
Правильный подход – использование copy-paste. То есть, внутри location'а должны быть все необходимые директивы для его обработки.
Обычный аргумент под любителей DRY (Don't Repeat Youself) заключается в том, что если надо будет что-нибудь исправить, то это можно исправить в одном месте и все будет прекрасно.
На самом деле, современные редакторы имеют функциональность find-replace. Если вам нужно, например, исправить имя/порт бэкенда или поменять root, заголовок, передаваемый бэкенду, и т.п., вы можете спокойно это сделать с помощью find.
Для того чтобы понять, нужно ли вам в данном месте поменять какой-то параметр, достаточно пары секунд. Например, у вас 100 location'ов, вы на каждый location потратите по 2 сек., итого 200 сек. ~ 3 мин. Это немного. А вот когда в будущем вам придется развязать какой-то location от общей части, то это будет уже гораздо сложнее. Вам нужно будет понять, что менять, как это будет влиять на другие location'ы и т.д. Поэтому, что касается конфигурации nginx, нужно использовать copy-paste.
Вообще говоря, администраторы не любят тратить много времени на свои конфигурации. Я и сам такой. У администратора может быть 2-3 любимых продукта, он может с ними возиться очень много, при этом существует десяток других продуктов, на которые времени тратить не хочется. Например, у меня на персональном сайте есть почта, это Exim, Dovecat. Их я не люблю администрировать. Я просто хочу, чтобы они работали, а если надо что-то добавить, чтобы это заняло не больше пары минут. Мне просто лень изучать конфигурацию, и, думаю, большинство администраторов nginx – они такие же, администрировать ngnix хотят как можно меньше, им важно, чтобы он работал. Если вы такой администратор, то используйте copy-paste.
Примеры того, как можно коротенькие немасштабируемые конфигурации превратить в то, что надо:
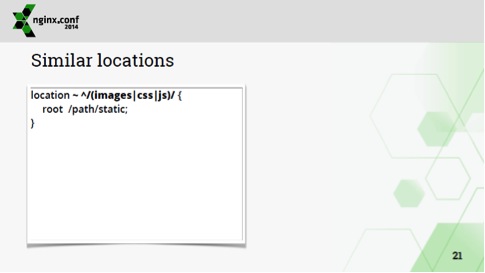
Тут человек думает, что написал регулярное выражение, всего мало, все хорошо. На самом деле, т.к. тут есть регулярное выражение, это плохо – оно может влиять на все остальное. Поэтому лично я делаю вот так:
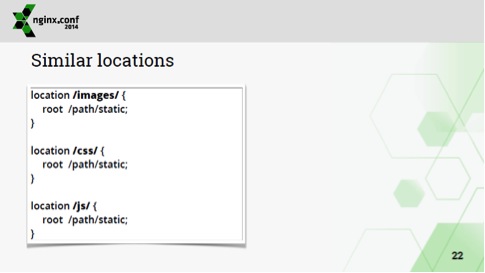
Если у вас этот root общий для всех location'ов или, по крайней мере, используется в большинстве из них, то это можно сделать даже так:
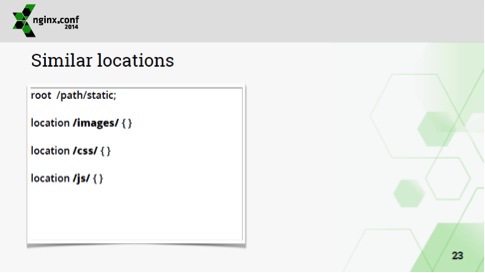
Это, вообще, легальная конфигурация, т.е. совершенно пустая конфигурация location'ов.
Второй способ избежать copy-paste – это вот такой пример:
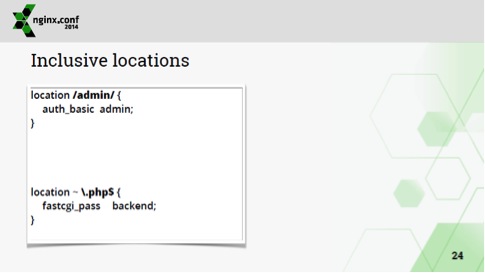
Администраторы, которые раньше работали с apache, думают, что admin/index.php должен запрашивать авторизацию. В nginx это не работает, т.к. index.php обрабатывается в одном location'е, а location/admin совершенно другой. Но можно сделать вложенную конфигурацию и тогда index.php естественно запросит авторизацию.
Часто бывает нужно использовать регулярные выражения для того, чтобы "выкусывать" какие-то части из URL и использовать их при обработке. Вот это плохой способ:
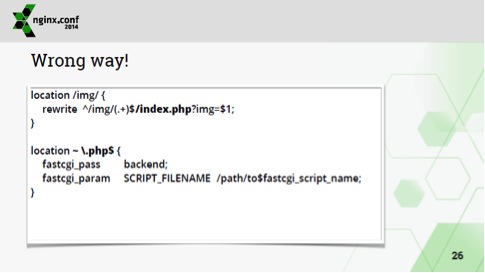
Правильно – это использовать вложенные location'ы, таким образом, мы изолируем регулярные выражения от конфигурации всего остального сайта, т.е. дальше этого location/img/, который помещается на экран, управление не уйдет:

Еще одно место, где можно в nginx достаточно безопасно использовать регулярные выражения, это map'ы, т.е. формировать переменные на основе каких-то других переменных с помощью регулярных выражений и т.д.:
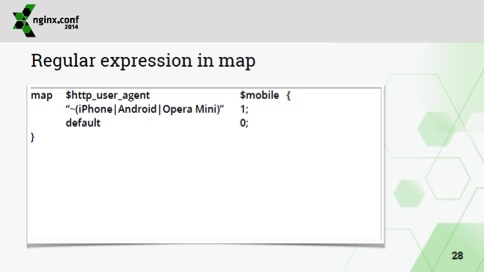
Я ничего не сказал об использовании Rewrites, потому что их не надо использовать вообще. Если вы не можете их не использовать, то используйте их на стороне бэкенда.
Evil – тоже не рекомендуемая конструкция в nginx, потому что, как работает внутри Evil, знает человек 10 в мире, и вы вряд ли входите в их число.
Вот такая конфигурация, когда у нас два if (true):
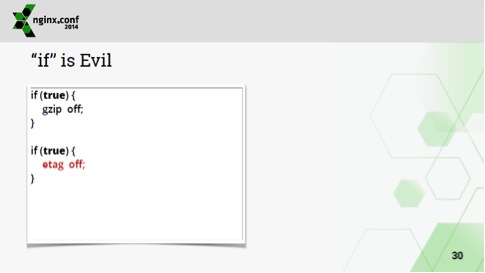
Ожидается, что у нас будут выключены gzip и etag. На самом деле отработает только последний if.
Есть одно безопасное использование if – это когда вы используете его для возврата ответа клиенту. Можете использовать rewrite в этом месте, но я его не люблю, я использую return (он позволяет добавить код и т.д.):

Резюмируем:
- использовать желательно только префиксные location'ы;
- избегайте регулярных выражений, если же регулярные выражения все-таки нужны в конфигурации, то их лучше изолировать;
- используйте map'ы;
- не слушайте людей, которые говорят, что DRY – это всеобщая парадигма. Это хорошо, когда вам нравится продукт, или вы программируете продукт. Если же вам просто нужно облегчить свою администраторскую жизнь, то copy-paste – это для вас. Ваш друг – это редактор с хорошим find-replace;
- не используйте rewrites;
- используйте if только для возврата какого-то ответа клиенту.
Вопрос из зала: Если я использую rewrites http на https, его где лучше использовать – в nginx или на бэкенде?
Ответ: Его использовать в nginx. Идеально это так – вы делаете два сервера. Один сервер у вас plane text'ы и он делает только rewrites. В этом месте будет буквально несколько директив – server listen на порту, server name, если нужен, и return в 301 или 302 на https с дублированием request URI. Там даже rewrite не нужен, используйте return.
Если вы хотите что-то более сложное сделать, то где-то можно вставить if. Допустим, часть location'ов у вас отрабатывают в plane text'е, опишите их с помощью регулярных выражений в map'е, например, а все остальное можно редиректить на https. Или, наоборот, вставить внутри каждого location'а по одному if, который будет редиректить на https.
Вопрос из зала: Спасибо за nginx. У меня несколько шутливый вопрос. Вы не планируете добавить ключик запуска или ключик компиляции, который не даст использовать директиву include, не даст использовать if, регулярные выражения в location'ах?
Ответ: Нет, вряд ли. Мы обычно добавляем какие-то директивы, улучшаем их и потом делаем их deprecated. Они какое-то время выводят warning в логе, прежде чем пропасть полностью, но они работают в каком-то режиме. Мы вряд ли будем делать то, что вы сказали, мы лучше напишем хороший User Guide, возможно, по материалам этого выступления.
Вопрос из зала: Обычное желание, которое возникает при использовании if, это потому что его можно использовать в сервере и в location'е, а map использовать нельзя. Почему так получилось?
Ответ: Все переменные в nginx вычисляются on the map, т.е. если map описываем на уровне http, это не означает того, что при обработке запроса эта переменная будет вычисляться обязательно. Map нужен для того, чтобы отмаппить что-то в одно, а потом что-то одно – в другое, а результирующую переменную вы можете использовать в if или внутри какого-то выражения, проксировать куда-то и т.п. Map – это просто как бы декларация... Может быть, их имеет смысл переместить на сервер для того, чтобы сделать их локальными для сервера, если у вас одна и та же переменная. Там просто было сложнее программировать, поэтому они были вынесены на глобальный сервер. В nginx нет переменных, которые были бы локальными внутри сервера.
С точки зрения performance никаких проблем нет, это просто неудобство. Надо будет сделать, допустим, три сервера и три map'а, а у переменной будет префикс "сервер такой-то"... Вы можете их, в принципе, описывать перед сервером, т.е. эти map'ы – одна будет перед первым сервером, потом перед вторым... По конфигу не надо будет скакать вверх-вниз, они будут ближе к серверу.
Вопрос из зала: Я плохо знаком с логикой работы return'ов. Расскажите, пожалуйста, где стоит использовать return'ы вместо rewrite'ов, какие-то use case'ы конкретные?
Ответ: Вообще, rewrite заменяется на такую конструкцию: location с регулярным выражением, в котором можно сделать какие-то captures – захваты, выделения, и на директиву return. Т.е. один rewrite – его левая часть в location'е, а правая часть – это то, что будет в return'е после кода ответа. Return предлагает возможность возврата разного кода ответа, а в rewrite для возврата клиенту есть только 301, 302. Return может вернуть 404 с каким-то телом, может – 200, 500, может вернуть redirect. А в его теле можно использовать переменную, что-то написать. Если это 301, 302, то это не тело, это уже URL, на который нужно сделать redirect. В общем, у return'а богаче функциональность.
Вопрос из зала: У меня прикладной вопрос. Nginx можно использовать как почтовый прокси. Можно ли дать SMTP-доступ в почтовый клиент, отправить письмо через этот почтовый клиент, и nginx'ом перехватить данные и отправить на скрипт, минуя почтовый веб-сервер? Сейчас мы эту задачу реализуем, используя postfix – он перехватывает письмо и дальше кидает на скрипт, где происходит обработка.
Ответ: Я сомневаюсь, что это можно сделать посредством nginx. Я могу описать кратко функциональность, которая есть в SMTP Proxy в nginx. Он умеет делать следующее – к нему соединяется SMTP-клиент, показывает какую-то аутентификацию, nginx идет во внешний скрипт, проверяет имя-пароль, а потом говорит, пускать клиента на какие-то сервера (и передает, на какие конкретно), либо не пускать. Это все, что он умеет делать. Если решено куда-то пускать, то nginx по SMTP соединяется с этим сервером и передает ему. Ложится ли это в Ваш сценарий, я не могу сказать. Вряд ли.
SMTP Proxy с авторизацией появился, потому что в Рамблере для клиентов почты есть специальный сервер, через который эти клиенты отправляли почту. И оказалось что около 90% соединений – это не клиенты Рамблера, а спам и вирусы. Чтобы не нагружать postfix'ы, не поднимать лишние процессы, перед этим поставили nginx, который проверяет, предоставляет ли этот клиент свои аутентификационные данные. Собственно, для этого это и было сделано – просто, чтобы отбивать "мусорных" клиентов.
Вопрос из зала: Вы сегодня упомянули про контейнеры, это, конечно, многообещающий подход, но он подразумевает изменяющуюся топологию и динамическую конфигурацию. Сейчас это пока приводит к тому, что люди строят некие внешние "костыли", которые периодически реагируют на события изменения топологии, генерят через какой-нибудь шаблон актуальный конфиг nginx'а, подсовывают его и пинают, чтобы пересчитал конфиг. Интересно – у компании есть какие-то планы по развитию в сторону контейнеризации, т.е. в сторону обеспечения более удобных и естественных средств для этого тренда?
Ответ: Смотря, что Вы подразумеваете под контейнерами в данном случае. Я, когда говорил про контейнеры, сравнивал, я говорил, что эти location'ы выглядят изолированно друг от друга.
Вопрос: Мы вернулись обратно к docker’у, к возможности запуска бэкендов где-то в контейнерах, который динамически исполняется на разных хостах, и нужно, грубо говоря, добавить в балансировку новый хост...
Ответ: У нас в NGINX+ одна из частей Advansed Load Balansing, как раз, подразумевает, что вы можете динамически добавлять сервера в апстрим. Получается, вам не нужно делать reload конфига nginx'а, а все это делается на лету – для этого есть API.
Еще туда включены активные хелсчеки. Когда обычный open source nginx соединяется с бэкендом, если бэкенд не отвечает, то к нему nginx некоторое время не обращается, т.е. своеобразный хелсчек тоже здесь есть, но страдают клиенты. Если у вас 50 клиентов одновременно пошло на один бэкенд, а он лежит или по таймауту отвалится через 5-10 сек., то клиенты это увидят, и только после этого их перебросят на другой апстрим. В NGINX+ у нас есть проактивное тестирование бэкендов, т.е. бэкенды сами тестируются, и клиенты на упавшие бэкенды просто не отправляются.
Вопрос: И, раз есть активный хелсчек, то, может, уже и запилили тогда красивую JSON-образную страничку статуса, которую можно отпарсить?
Ответ: Да, у нас есть мониторинг, он доступен, в том числе, и через JSON, а также он есть в виде красивого html'а.