Общая логика масштабирования
На сегодняшней лекции я попытаюсь вам объяснить, как нужно думать при проектировании высоконагруженной системы.
И первое, что мы с вами будем изучать – это общую схему построения высоконагруженного серверного веб-приложения.
Но для начала – об инженерном подходе. Многие думают, что проектирование крупного проекта – это магия и волшебство. Ничего подобного, этому можно научиться. Важно начать правильно думать и применять некоторые архитектурные приёмы, паттерны проектирования.
Паттернов не так уж и много, их можно изучить и вызубрить. Развить в себе инженерное мышление гораздо сложнее.Спроектируем Сбербанк
Думаю, все вы бывали в Сбербанке, и можете оценить разницу между тем, каким был Сбербанк 10 лет назад, и какой он сейчас. Сбербанк, как это ни странно, использует те же самые паттерны проектирования высоконагруженной масштабируемой системы, что используются в вебе.
Представьте очередь в Сбербанке. Нашей целью является увеличение пропускной способности отделения. Обратите внимание на такой момент – увеличение пропускной способности и увеличение масштабируемости, увеличение скорости обработки одного клиента – это не одно и то же. Можем ли мы увеличить скорость обработки клиента? Можем, но незначительно. Можем ли увеличить пропускную способность всего отделения? Можем, но какими средствами?
Допустим гипотетическую ситуацию – у нас одно окошко и к нему огромная очередь. Понятно, что первое, что мы внедрили бы, это горизонтальное масштабирование – мы бы достроили несколько окошек, посадили бы несколько операторов и направили бы несколько очередей. В чем минусы? Балансировка, затраты, ресурсы, недогруз, долгий рост невозможен...
Не самое эффективное разделение, т.к. вам придется в реальном смысле дублировать все. Т.е. если мы хотим, чтобы каждый оператор обрабатывал все запросы, то нам придется каждому оператору дать по печати, поставить по принтеру, установить весь набор ПО, научить работать со всем этим ПО и различными банковскими инструментами – оператор должен выдавать и кредиты с пенсиями, и платежки отправлять...
Напрашивается не просто распараллеливание очередей, а некая специализация, т.е. мы проводим горизонтальное масштабирование одновременно с функциональным разделением – каждая группа операторов занимается своим делом: кто-то будет исключительно принимать платежки ЖКХ, другие будут выдавать кредиты и т.д.
Это идеальная ситуация или еще что-то можно улучшить? Как еще ускорить процесс?
Для каждого посетителя есть определенная цепочка взаимодействий с ним. Давайте, например, поставим человека, который будет направлять посетителя к нужной группе операторов. Это будет то самое "единое окно" – если вы сейчас зайдете в Сбербанк, то во многих отделениях увидите установленные специальные аппараты. Вы выбираете на нем свой запрос и получаете квиточек, на котором написано, куда вам следует обратиться. Номер этого квиточка высветится над свободным соответствующим оператором. Таким образом, мы организуем, во-первых, конвейер, а, во-вторых, некую входящую балансировку. Т.е. я получил такой квиточек, например, мне нужно заплатить за услуги ЖКХ, подхожу к нужному оператору, оператор готовит документы и отправляет меня дальше, например, на прием денег, т.к. это разные процессы, они могут выполняться с разной скоростью. Например, 10 человек, которые готовят документы, могут загружать только двоих кассиров. Т.е. с введением конвейера и такого рода специализации – у нас не просто разделение по сервисам, еще и в каждом сервисе может быть несколько стадий – у нас появляется возможность балансировать нагрузку и выделять на каждую стадию то количество ресурсов, которое необходимо.
Кстати, сотрудник на входе будет выполнять роль фронтенда, то есть самостоятельно обрабатывать лёгкие запросы – например, отвечать на вопросы “до скольки вы работаете?», “могу ли я оплатить здесь квитанцию” и так далее.
Далее добавим отложенные вычисления. Некоторые процессы (запросы) не обязательно выполнять сразу, их можно выполнить, к примеру, во время спада нагрузки или после окончания рабочего операционного дня. Между прочим, оно так и происходит – у вас берут нужные документы, все оформляют, а проводятся платежи потом. Или, например, вы приходите подать заявку на кредит. В большинстве случаев ваши данные заполняются и отправляются в систему с другой логикой, которая по каким-то своим законам в определенное ею время проверяет, достойны ли вы кредита. Т.е. мы можем выполнять отложенные вычисления и операции без привязки к клиентам, когда это удобно нам.
Что мы можем еще улучшить, чтобы получить идеальный банк? Добавляем предобработку. Предобработка широко используется, например, при прохождении паспортного контроля, когда вы заполняете таможенную декларацию – вы можете видеть примеры заполненных деклараций. В банке мы так же подготовим инструкции, чтобы клиент мог самостоятельно заполнить, например, платежное поручение.
У нас уже довольно сложная система. В ней есть: распараллеливание, предобработка, очередь, балансировка, конвейер и отложенные вычисления.
Это еще не все. Добавим кэширование. Мы можем заранее распечатать различные стандартные бланки, или у операционистов может быть какое-то заранее заполненные формы, например, он вбивает БИК, и все координаты и реквизиты банка подставляются автоматически.
Еще мы можем ввести толстого клиента – это может быть Сбербанк-онлайн, банкомат перед входом в банк – вы можете воспользоваться этими возможностями для проведения массы операций. У нас получилась система, которая довольно серьезно увеличила пропускную способность офиса. Мы всего лишь включили логику, и все стало понятно – как, что делать, и какие ограничения, проблемы у нас возникают даже на такой абстрактной системе, как очередь в Сбербанке. Нет никакой магии – всего лишь логика, инженерный подход и, может быть, немного интуиции.
Увеличение производительности
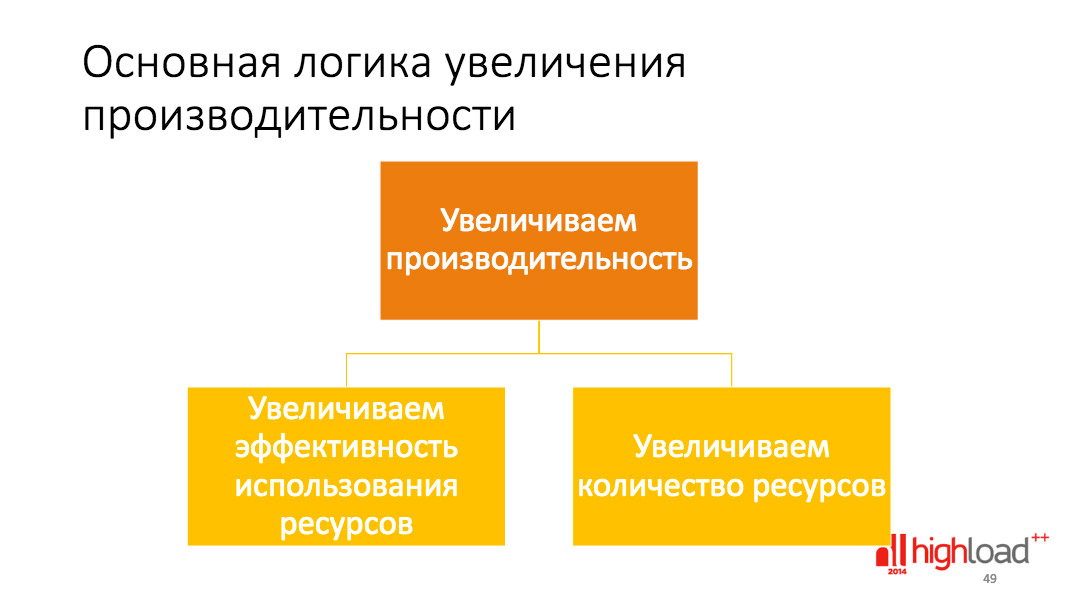
Первое, что мы можем сделать – увеличить эффективность имеющихся у нас ресурсов. Мы можем сделать так, что тот 1 сервер или 5 серверов, что у нас есть, будут использоваться с большей эффективностью. Раньше 5 серверов хватало для обслуживания 1 млн. запросов, теперь – 5 млн.
Существует огромная область, которую мы сегодня рассматривать не будем, – это оптимизация и тюнинг. Важная область, но она слишком привязана к конкретным инструментам, т.е. для MySQL – это одни настройки, особенности плана выполнения запросов, для PostgreSQL – другие, для MongoDB – третьи... Для различных ОС подход к кэшированию различен... Поэтому мы сегодня не будем затрагивать оптимизацию и будем работать только с точки зрения архитектуры – какие архитектурные приемы мы могли бы внедрить, чтобы увеличить эффективность использования ресурсов, которые у нас уже есть?
Рано или поздно неизбежно мы придем к моменту, когда дальнейшее увеличение эффективности использования того, что есть, уже будет невозможно. Нам придется научиться использовать новые ресурсы, включать новое аппаратное обеспечение и научить нашу систему работать на нескольких серверах, научить ее параллелиться, шардиться, горизонтально масштабироваться и т.д.
В рамках нашей рассылки мы будем много говорить о паттернах – архитектурных приемах, которые увеличивают эффективность использования ресурсов. Но для начала – самые основы. Итак, пусть у нас есть типичная веб-система. Она обладает некими особенностями. Какие у нас есть принципиальные классы запросов к веб-системе? Это быстрые статические запросы (картинки, css, js-скрипты) и некие запросы, требующие вычислений.
Первое, что мы можем сделать – это ввести инструмент №1 – трехзвенную структуру.
Трёхзвенная структура
Трехзвенная структура заключается в следующем. Мы выделяем некие звенья в обработке наших запросов, и каждое звено специализируется на обработке или выполнении определенного класса задач.
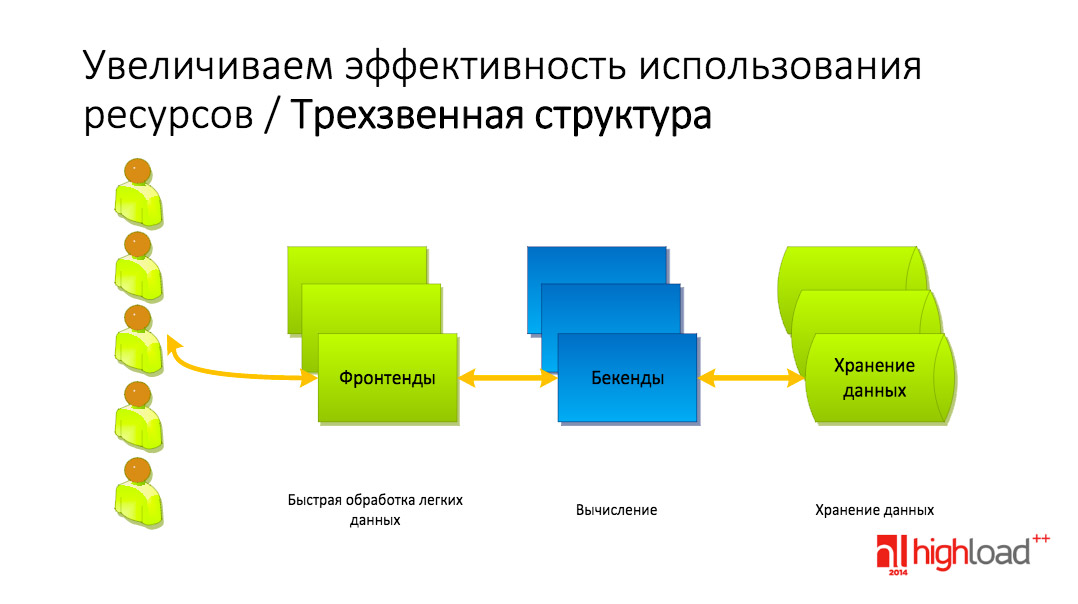
1-е звено – это так называемые фронтенды, предназначенные для быстрой обработки легких данных, как правило, статики. Эти запросы обрабатываются тут и не проходят на массивный, тяжелый бэкенд.

В чем основное отличие? Для фронтенда используются такие легковесные сервера, как ngnix, разработанный Игорем Сысоевым. В разработке подобных серверов огромное внимание уделяется тому, какое количество ресурсов тратится на обработку одного запроса. Я помню, как Игорь бился над тем, чтобы на один запрос приходилось как можно меньше килобайт, и на обработку одного запроса на фронтенде памяти тратится, действительно всего несколько килобайт, т.е. структуры данных сервера, которые хранят в себе все необходимое для обработки запроса, измеряются килобайтами, если не сотнями байт. Чего не скажешь о массивных бэкендах, в которых зачастую использование нескольких мегабайт для обработки запроса – вполне обычное дело. Бэкенды, как правило, это тяжелые приложения, в которых происходят вычисления, зашита бизнес-логика, и обрабатывать статические запросы бэкендом попросту неэффективно.
Следующий слой – это хранение данных, в простейшем варианте – база данных.
У каждого уровня свои задачи и своя логика масштабирования. Такое разделение является самым первым шагом и используется в подавляющем большинстве веб-проектов.
Фронтенд
Для чего нужен фронтенд, кроме быстрой обработки легких данных?

Сейчас это уже не так актуально, но когда Интернет был очень медленным, одной из основных причин для внедрения фронтенда было обслуживание медленных клиентов. Это означает следующее. К ngnix приходит запрос от пользователя, который сидит на GPRS. Он медленно-медленно запрашивает страницы и так же медленно постит фотографии. Если мы из фронтенда тут же отпроксируем это соединение к бэкенду, то у нас все время, пока будет закачиваться картинка, бэкенд будет простаивать в ожидании этой картинки. Именно поэтому подобные системы построены таким образом, что они сначала целиком и полностью принимают запрос, потом быстро устанавливают соединение с бэкендом, быстро отдают запрос, быстро получают ответ, быстро кэшируют его у себя и потом опять медленно-медленно отдают его медленному клиенту.
Типичная схема – пока ngnix занят отдачей медленному клиенту, бэкенд уже готов принимать следующий запрос. Поэтому ngnix, когда мы его тестировали 3-4 года назад, был способен обрабатывать десятки тысяч запросов в с секунду, в отличие от обычного бэкенда.
Итак, инструмент №1 – трехзвенная архитектура – позволит нам более эффективно использовать имеющиеся ресурсы. Даже в рамках одной машины вы можете запустить ngnix, бэкенд и БД. В большинстве случаев это будет более эффективно, чем тяжелый apache и бэкенд, смотрящий во внешний мир.