Осваиваем Tarantool 1.6
Теперь наша задача - освоить какую-нибудь из самых продвинутых СУБД в оперативной памяти. Начнём с Tarantool и поможет нам в этом Евгений Шадрин.
Евгений Шадрин (Sberbank Digital Ventures)

Прослеживая новости в течение последних нескольких лет, можно заметить, что новые NoSQL-решения, какие-то релизы появляются чуть ли не каждые две недели. Конечно, многие из этих NoSQL не выживают, проигрывают конкуренцию, пропадают, но мир NoSQL обновляется новыми решениями очень часто.
На конференции есть как люди, которые никогда в жизни не использовали NoSQL, так и люди, которые больше пяти лет используют NoSQL в своих проектах, компаниях. Некоторые даже участвуют в open source проектах. Немного, но такие тоже есть.
Меня зовут Евгений. Я работаю в подразделении сбербанка Digital Ventures – это небольшое подразделение, которое занимается внедрением инновационных продуктов и решений. Т.е. мы делаем IT-прототипы на стыке новых технологий.
В этом докладе я хочу рассказать про свой кейс использования NoSQL-решения со стороны пользователя, поэтому в начале вкратце хотелось бы пройти по теории.
Что же такое NoSQL?

Я использую акроним, что это не только SQL. Это решения, которые содержат в себе модели данных, отличные от реляционных, и призванные решать какие-то вопросы, например, вопрос простоты масштабирования. Зачастую за счет того, что в NoSQL решениях для хранения и работы с данными не нужно задавать конкретные схемы, сущности, много конфигураций, очень легко и просто решать вопрос масштабирования, развертывать большие кластеры с большим количеством узлов, добавлять и удалять эти узлы. Также NoSQL решения зачастую весьма специализированы, т.е. каждая команда разработчиков не всегда старается сделать большой универсальный проект, а пытается решить какую-то задачу. Такая специализация решений позволяет добиться весьма высоких показателей производительности в конкретных задачах. И в таких задачах использовать NoSQL-решения может быть удобно и просто.

Тут я привел наиболее популярные базы данных в порядке классификации. Вы слышали про key-value хранилища Redis и Riak – они используют модель ключ-значение для хранения данных. Документно-ориентированная база данных mongoDB, весьма распространенная и известная. Документно-ориентированная модель чуть более сложная, чем модель key-value и позволяет хранить весьма большую иерархическую информацию. Табличные, матричные базы данных, например, Apache Hbase – можно работать с большим количеством распределенной информации. И база данных, которая поддерживает мультипарадигмы, но я привел ее в качестве примера базы данных, поддерживающих графовую модель. У графовой модели есть преимущество – очень удобно прослеживать связи между данными, что бывает неплохо при работе с проектами -аналогами соцсетей.
Как же из всего этого большого разнообразия нужно выбрать то решение, которое подходит именно вам? Я пользуюсь следующими принципами:

- Не стоит изобретать велосипед. Я встречал команды разработчиков, которые рвались в бой, говоря, что сейчас мы быстро напишем свое небольшое хранилище, которое подходит именно нам, которое хранит те типы данных, которые нужны нам. Все оказывается не так просто. Вот база данных Tarantool разрабатывается больше 4х лет командой профессиональных разработчиков, и постоянно возникают какие-то вопросы, которые стоит решать-решать-решать. Многие NoSQL-решения в возрасте более 10-ти лет. Поэтому правильно выбирать нужное вам решение, исходя из вашей конкретной задачи.
- Большинство баз данных призваны решать какую-то проблему, если вы поймете, какую проблему решаете, вы скорее всего сможете подобрать нужное решение.
- Надеюсь, пункт «опирайтесь на опыт других» понятен. В мире интернета не так сложно залезть, погуглить, почитать книги, в конце концов, в наглую взять и написать разработчикам и сказать: «Скажите, пожалуйста, у меня есть такой кейс, как вы посоветуете его решить?». Многие разработчики весьма отзывчивы и помогают.
- Если вам повезло и для вашей задачи существует несколько решений, то не стоит очень долго внедряться в сравнение производительности, построение тестовых стендов, понимание того, что же лучше – А или Б. Выберите то, что знаете. Сэкономьте время на изучение, на разборку продукта. Если знаете вы – хорошо, если знает ваш коллега – тоже неплохо, всегда можно к нему обратиться.
И краткие перечисления тех кейсов, которые решает NoSQL.

С большинством из них я сталкивался лично.
- «Кэширование» данных – всем известная база данных Memcached. Сюда можно добавить хранение промежуточных данных, т.е. это те данные, к которым мы хотим получить доступ быстро, сейчас, в нужный момент.
- «Работа с большими объемами данных», наверное, не совсем корректно звучит, потому что реляционные базы данных тоже работают с большими, огромными потоками данных… Я имел в виду именно слово «потоки», т.е., например, нам льются откуда-то запросы серверов, и мы хотим их быстро сохранить, а потом разбираться, что с ними делать дальше. Эту задачу, например, неплохо решает Hbase в рамках продукта hadoop.
- Сервисы очередей. NoSQL может выступать как часть сервиса очередей. К примеру, связка RabbitMQ и Redis пару раз встречалась на моей практике – простой удобный бэкенд в виде NoSQL.
- Отдельно я вынес платформы для статистики обработки данных – это когда мы получаем данные и не хотим хранить их все, у нас нет памяти, у нас ограниченные ресурсы. Мы можем эти данные сразу же обрабатывать. Например, получаем какие-то признаки пользователей, ненужные признаки можем выкидывать, остальные нормализовывать и просто хранить их в виде векторов «ключ-значение», к примеру, в Redis’e.
- Еще можно использовать NoSQL в качестве небольшого удобного бэкенда для хранения, т.е. просто взяли и сохранили. MongoDB – достаточно быстро и удобно развертываемая база данных, которая подходит для этого кейса.
Кейсов, конечно, намного больше, но я рассказал те, с которыми сталкивался. Вообще в Sberbank Digital Ventures я занимаюсь разработкой систем, которые работают в режиме реального времени, и основное предназначение таких систем – это получить информацию с сервера, сохранить ее, обработать, понять, что она из себя представляет, и выдать серверу нужный ответ.
К примеру, я получаю нужную информацию о пользователе, который ходит где-то в недрах интернета. Я получаю все данные, которые смог собрать, анализирую их и могу сегментировать пользователя, т.е. отнести его к той или иной категории – т.е. узнать, это молодой человек 25 лет, который интересуется автомобилями, или это молодая девушка 18 лет, которая хочет поступить в университет и ищет, где возьмут взятку за поступление.

Для решения своей задачи я использую NoSQL базы данных Tarantool. В дальнейшем я расскажу, почему и для чего использую, и как она помогла решить задачи, которые передо мной возникают.
На слайде – цитата с главной страницы сайта разработчиков, это их позиционирование «A NoSQL database running in a Lua application server», т.е. сами разработчики позиционируют Tarantool как проект, который состоит из двух частей: 1-ая часть – это нереляционная база данных, 2-ая часть – это Lua application server, т.е. сервер приложений с использованием языка Lua.
Кстати, обратите внимание, что большинство современных значков NoSQL баз данных используют серый цвет и красный, наверно, это в тренде. J
Дальше я буду приводить вам примеры кода, у кого есть возможность, может зайти по ссылке на сервер try.tarantool.org – это интерактивный сервис, куда вы можете зайти и там сразу воспользоваться Tarantool’ом, т.е. это некий интерактивный Tarantool, который выделяется под вас на серверах разработчиков, может, кто-то захочет примеры кода сразу туда вбить.
Что же выделяет Tarantool из большого стека NoSQL-технологий?

Tarantool хранит все свои данные в памяти, благодаря этому мы получаем быстрый доступ к этим данным. То, что Tarantool хранит их в памяти – это не значит, что это небезопасно, и данные мы можем потерять. В Tarantool’e есть механизм сохранения данных – у нас есть логи журналов и у нас есть снепшоты – это бинарные снимки состояний. Эти два механизма работают вместе, т.е. у нас есть точки с сохраненными данными, и у нас есть описания действий, которые делались до или после с этими данными. Имея такую информацию, мы всегда можем прийти в нужное состояние.
В свое время хранение данных в памяти приводило к тому, что эта память очень быстро заканчивалась и заканчивается сейчас, но все-таки объемы оперативной памяти постоянно растут, и похожие базы данных получают более широкий спектр применимости. Tarantool использует документно-ориентированную модель данных, т.е. все данные он хранит в некой абстракции, называемой документ, у документа есть свои поля, с которыми Tarantool работает.
Одна из особенностей Tarantool’a как базы данных – это наличие вторичных индексов. Наличие вторичных индексов позволяет сделать действия с данными Tarantool’a более живыми, интересными и быстрыми.
Я пока не использовал транзакции в своих проектах, но Tarantool поддерживает полноценные транзакции. Насколько я знаю, в некоторых компаниях – mail.ru, avito – успешно используют их для решения своих кейсов. В Tarantool’е есть модель легковесных потоков или Green threads. Это многопоточная модель, только потоки создаются не на уровне Unix’a, а внутри самого приложения – это позволяет нам реализовывать какие-то асинхронные вещи, событийные модели.
Также Tarantool работает с сетью и файлами – у него есть свой http-сервер, свои библиотеки, которые сохраняют и открывают файлы – это тоже пригодилось мне в задачах.
Tarantool – это Lua application server, Lua – это встраиваемый язык Tarantool’а. Здесь я привел пример очень искусственного, абсолютно неиспользуемого на практике скрипта для того, чтобы показать, что такое Lua:
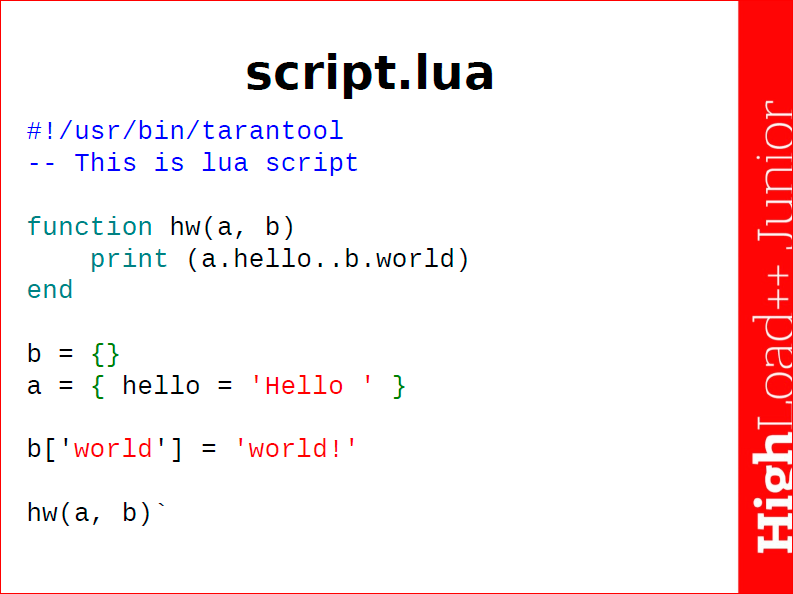
Язык Lua был разработан в Бразилии в католическом университете, он произошел от языка SOL (солнца), который работает именно с данными и был заточен под работу с базами данных. Здесь мы можем видеть, что это не просто скрипт, а исполняемый скрипт. Решеточка и восклицательный знак – это механизм, который позволяет нам задать, кто и как должен запускать этот скрипт. Т.е. введя в консоли tarantool script.lua, мы получим на экране «hello world». Здесь мы видим функцию, которая работает с двумя объектами, и ниже инициализируем сами эти объекты.
Основная структура данных lua – это таблицы. Т.е. объекты a и b – это таблицы, я специально инициализировал их по-разному, чтобы показать, что язык lua очень гибкий и синтакcически приятный. Эти таблицы могут содержать внутри себя другие данные, это могут быть тоже таблицы, а таблицы могут содержать другие таблицы, и иногда по неопытности составлялись очень большие вложенности. Функции тоже могут храниться внутри таблицы и вообще с объектом «функции» тоже можно работать как с таблицей, есть свои методы.
Дальше я приведу пример более практического скрипта, который можно дорабатывать и использовать в каком-то вашем продакшне. Он решает маленькую задачку, решает весьма тривиально – считает количество уникальных посетителей на страничке.
Это т.н. исполняемый lua-скрипт, который будет запускать Tarantool, и он будет выполнять ту последовательность действий, которая заложена здесь.
Вкратце пройдем по блокам того, что здесь есть, а потом разберем подробнее.
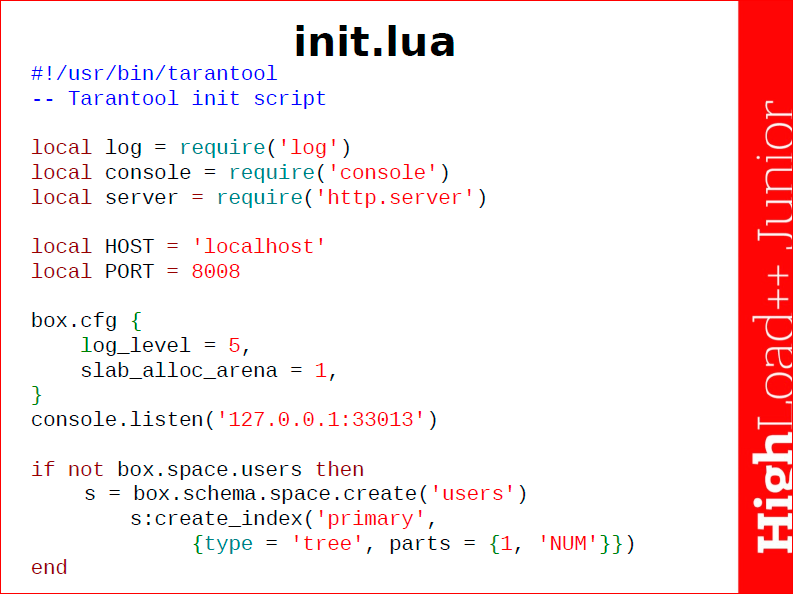
Вверху я подключаю те пакеты, которые мне понадобятся – это lua-шный механизм require, я подключаю пакеты log, console, server. Определяю какие-то константы, которые использую.
Дальше идет конфигурирование базы данных Tarantool с помощью модуля box.cfg, где я задаю два необходимых мне параметра. Я запускаю консоль и создаю сущности нашей базы данных box.schema.space.create('users'), т.е. я создал пространство «users», об этом всем чуть позже расскажу.
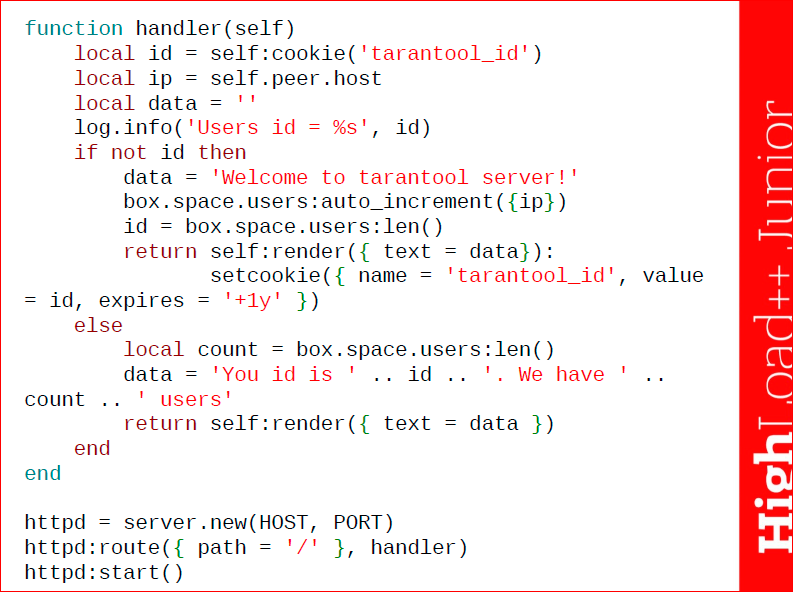
2-ой слайд, который работает с сервером Tarantool’а: я описываю функцию handler – функцию обработчика запросов, а внизу создаю сервер, создаю route для обработки и стартую этот сервер.
Со стороны пользователя выполнение этого скрипта выглядит примерно так:
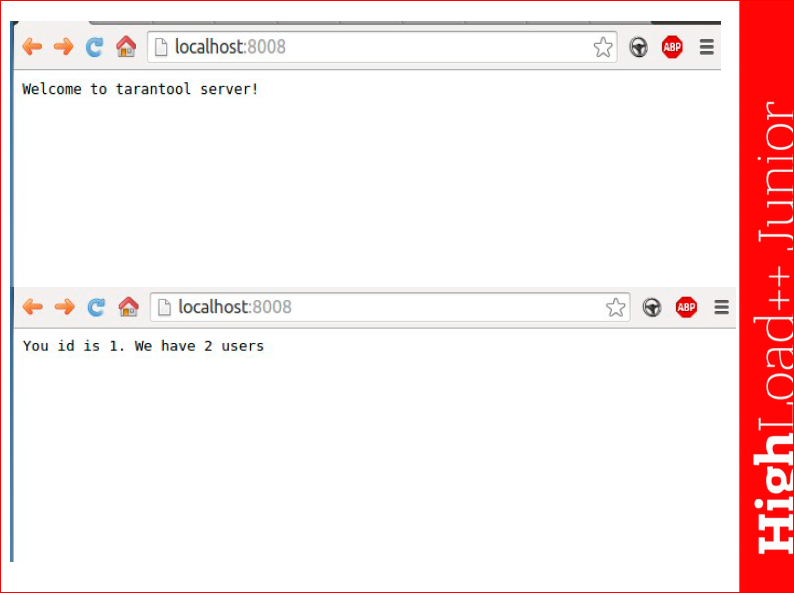
Пользователь зашел, например, на localhost и увидел приглашающее сообщение. В дальнейшем, если он будет обновлять, у него уже будет выссыль на cookie, ему будет присвоен какой-то id, и он будет знать количество уникальных юзеров, которое заходит на эти странички.
Этот небольшой скрипт решает какую-то нужную мне задачу – это ответ на вопрос, почему мы используем язык lua.
Язык lua весьма простой, существуют целые наборы статей «lua за 15 минут», «за 30 минут»… Вам действительно нужно немного, чтобы познакомиться с этим интересным языком. За пару часов вы узнаете все его особенности.
Очень удобно, что основная структура данных – это таблицы. Это позволяет унифицировано работать со всеми остальными данными.
Сам по себе, стандартный интерпретатор lua не очень быстрый, правильно сказать, совсем небыстрый, но существует аналогичный интерпретатор luajit, который делает jit-компиляцию, и он намного быстрее, и он делает lua очень производительным языком.
Есть такая библиотечка luafun – это возможность программировать в lua в функциональном стиле. Благодаря luajit’у эта библиотечка очень быстро работает, вы можете прогуглить, почитать про нее, отзывы про ее производительность – очень интересно.
Также lua – очень хорошо встраиваемый язык и у него прекрасная интеграция с языком С. Благодаря тому, что lua можно запустить внутри языка С, а си-шные процедуры можно запустить внутри lua, lua нашел очень широкую сферу применимости в gamedev’e. Очень много расширений, квестов и различной игровой механики и логики в известной игре «World of Warcraft» написано на lua и до сих пор пишется.
Tarantool, NoSQL – это полноценный lua-интерпретатор, т.е. если вы просто запустите Tarantool, вы можете банально работать с lua.

Tarantool можно запустить в 2-х сущностях:
- Первая – как интерпретатор, т.е. запустить Tarantool и построчно выполнять какие-то команды – это бывает полезно, если вы что-то не знаете или хотите сделать какую-то команду из документации.
- И с помощью стартового скрипта init.lua (называть его можно как угодно), в котором записана последовательность команд.
Разберем более подробно тот пример, который я привел до этого – стартового скрипта init.lua.

Начинается работа с базой с ее конфигурирования, т.е. механизм box.cfg – это пакет box, который внутри себя содержит табличку cfg, и я могу задавать какие-то ее параметры. Box – это ящик, коробка. Этот пакет отвечает непосредственно за базу данных. Вы можете просто так запустить Tarantool, выполнить процедуры, функции, написать какие-то сообщения и т.д. , но без конфигурирования box.cfg базу данных вы не запустите. В данном случае я задал два параметра, которые мне хотелось бы видеть. Я задал уровень логов, которые будут печататься – это 5-ый уровень, debug- уровень, стандартный debug info error, и я задал очень важный параметр slab_alloc_arena – это та память, которая выделяется в Tarantool’e, точнее в оперативной памяти под алkоцирование и размещение данных. В данном случае «1» – это 1 Гб.
Также пакет box содержит много других вспомогательных вещей и средств, таких как box.info – библиотечка, которая выводит общую информацию о Tarantool’e.
box.slab – важная табличка, с помощью нее мы мониторим данные нашего Tarantool’а и смотрим, сколько у нас места осталось.
box.stat – библиотечка статистики, показывает количество инсертов, селектов и других операций, которые вы совершили.
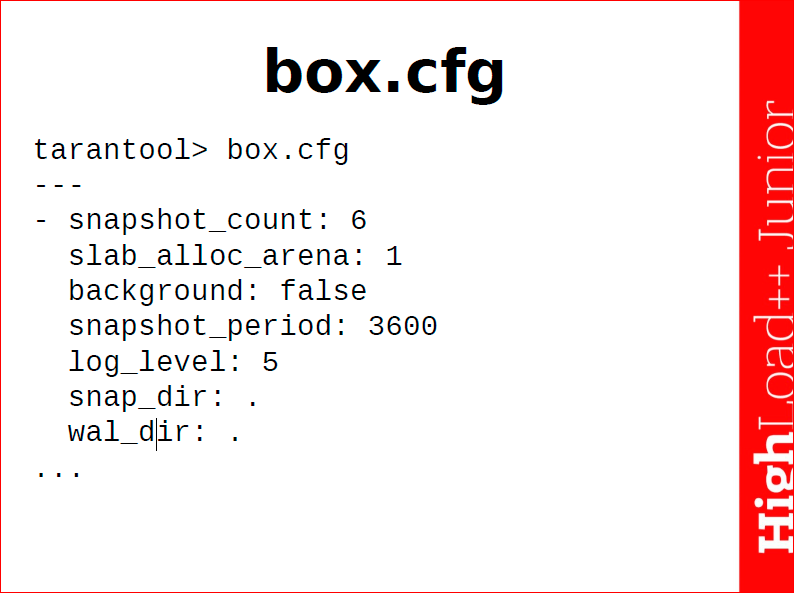
Если в интерпретаторе Tarantool’а после задания параметров набрать box.cfg, то вы получите объект с описанием всех параметров, которые есть, не только те, которые задал я, но и те, которые задаются по умолчанию.
Здесь мы видим то, что задал я slab_alloc_arena – пространство локации 1 Гб, видим log_level 5-ый уровень debug, также видим важный параметр snapshot_count – это количество снимков состояния, которое Tarantool будет хранить. Т.е. он будет хранить последние 6 снимков, которые делали за определенный период. Кстати, этот период тоже здесь задается параметром snapshot_period – 3600 секунд, т.е. раз в час Tarantool будет делать снимок состояния. Вы сами можете выбирать тот уровень безопасности, который вам надо, можно делать хоть каждую секунду, минуту, но это будет отнимать ваши ресурсы очень сильно. Параметры directoria, snap directoria, wal directoria, где вы храните свои снепшоты и логи.

Вот пример пакета box.info. Здесь можно посмотреть информацию о Tarantool’е, т.е. если Tarantool запущен как демон, вы можете узнать его pid, узнать версию Tarantool’а, на данный момент актуальна версия 1.6.5, вы можете посмотреть время беспрерывной работы, и можете узнать статус, в котором находится ваша машинка.
После того, как вы сконфигурировали данные, мы переходим к созданию самих сущностей, самих данных внутри Tarantool’а.
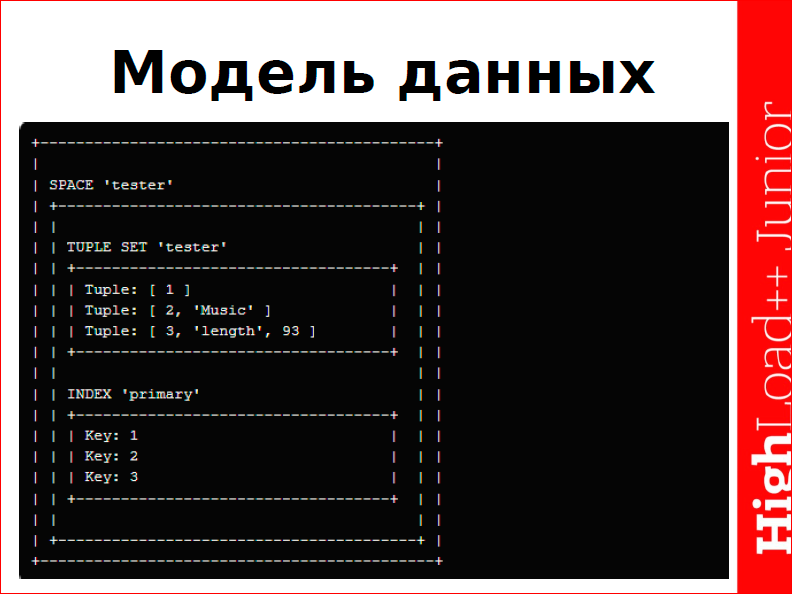
Здесь я привел картинку из документации – это изображение модели данных Tarantool, т.е. в Tarantool’е данные хранятся в space’ах, в каждом space’е есть сущность tuple – это записи и индексы, которые вы задаете, первичные или вторичные.
После конфигурации переходим к заполнению базы данных, т.е. мне нужно пространство, в котором я буду задавать информацию о юзерах.

Вы можете заметить, что я поместил эту информацию в условную конструкцию, сделано это для того, что если по какой-то причине ваш Tarantool был остановлен, и вы запускаете его заново при сохраненных снепшотах и икслогах, то Tarantool, прежде чем запуститься, восстанавливает свое состояние, т.е. он берет снепшот и проделывает действие из икслогов. Если вы запустили так, он не даст вам создать нужное пространство users, но оно скорее всего вам и не надо, поэтому очень часто вставляем такую проверку для того, чтобы не получать ошибку. Если у нас такого пространства не создано, то мы создаем space и создаем к нему индекс. В данном случае – это primary – первичный индекс в виде деревьев и представляет собой одно число.
В дальнейшем в скрипте мне необходимо добавлять новые записи о юзерах. Можно это делать с помощью стандартного инсерта, где мы передаем ключ-значение, но в моем случае в этом простом скрипте удобно это делать с помощью auto_increment’а. Юзер будет заходить, и ему автоматически будет присваиваться ключ на единицу больше, чем количество записей в базе на данный момент. Если я хочу узнать количество записей в своей базе, я могу воспользоваться стандартным механизмом len(), как видите, синтаксис весьма прост и понятен.

Как уже говорилось выше, Tarantool – это не просто база данных, это полноценный lua application server. Вероятно, разработчики здесь подразумевали то, что на языке lua вы можете писать любые модули и пакеты и тем самым реализовывать ту логику, которой вам не хватает. Т.е. вы не изобретаете велосипед большой, вы можете изобрести несколько маленьких, если вам очень нужно или этого нет в других решениях.
Посмотреть все это вы можете на github’e, репозиториях. Основные модули, которые так или иначе используются, – это модуль tarantool http, модуль tarantool queue очередь. К примеру, try.tarantool.org написан полностью на Tarantool’е, там используется Tarantool-хранилище, Tarantool-сервер. Также Tarantool поддерживает lua rocks – это пакетный менеджер Tarantool’а, который работает со своим репозиторием, и очень удобно устанавливать пакеты. Одной командой это делается.

Пакеты. Пакеты нужно подключить.
Под пакетом подразумевается какой-то другой lua скрипт, реализующий какую-то логику и, подключая этот пакет, вы можете получить методы из этого файла, какие-то данные из этого файла, какие-то переменные. На этом примере я подключаю с помощью lua’шного механизма require два пакета – console и log.
Console я запускаю на local host’е и вешаю на порт 33013. С помощью пакета log я могу делать записи в журнал логов. Под консолью здесь подразумевается консоль администратора или удаленная консоль управления – это механизм, который позволяет вам следить за состоянием своего Tarantool’а. Сделать это не сложно: если у вас консоль запущена, вы можете стандартными средствами Unix’а или еще какими-нибудь, например, telnet’ом и rlwrap’ом. telnet нужен для подключения на порт, для его прослушки, a rlwrap нужен для удобного ввода команд, сохранения истории команд.
Вы можете зайти на тот Tarantool, который у вас работает, и посмотреть какую-то информацию из box.info или box.stat.

Тот пакет, который я использую, и который весьма часто нужен – это пакет tarantool http. Это пока еще ограниченный http сервер, но работающий со многими механизмами, которые нужны. В данном случае я подключил пакет, создал сервер, повесил route для обработки, запустил его. А потом в функции handler я вернул ответ серверу, я вернул текстовую информацию и установил cookie пользователю – tarantool_id, value = id. Также задал время экспирации, т.е. время удаления, здесь cookie хранятся год.

Основные механизмы tarantool http позволяют реализовывать минимальную логику, т.е. здесь есть сервер, весьма полноценный, есть клиент, tarantool http работает с cookie’ами и поддерживает lua как некий встраиваемый язык каких-нибудь переменных внутри Template’а. Т.е. мы можем на lua писать маленькие процедурки внутри html.
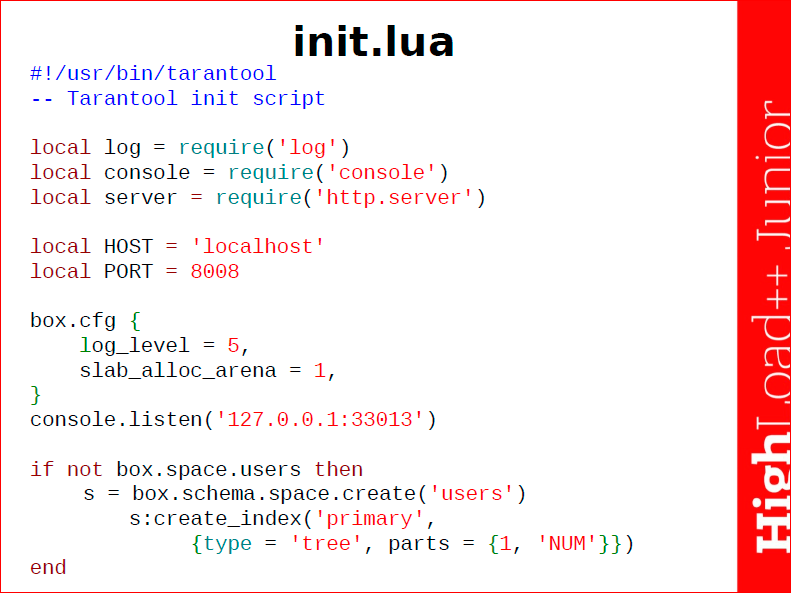
Я постарался рассказать основные моменты этого скрипта и еще раз, чтобы закрепить, можно пройтись, т.е. вам должно быть уже более понятно. У нас исполняемый скрипт Tarantool’а с комментарием. Дальше у нас происходит подключение пакетов через require. У нас есть две переменные – host и port. Дальше происходит конфигурирование Tarantool’a box.cfg, и я задаю два параметра – log_level (уровень журналирования) и slab_alloc_arena (пространства для локаций).
Я создаю консоль администратора, которой буду пользоваться. Дальше, если у меня нет нужного space, я создаю space users – box.schema.space.create и создаю к ней индекс.
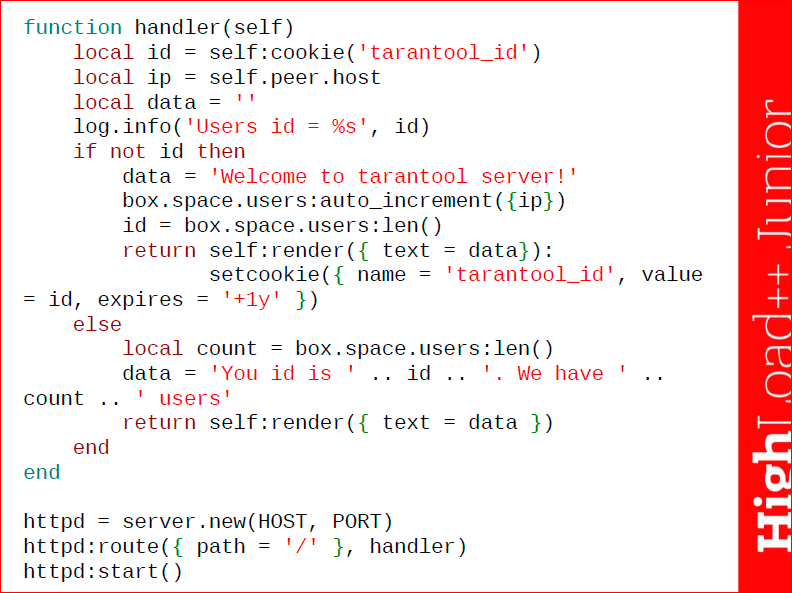
В функции обработки я получаю cookie, которые содержатся у пользователя, который зашел на мою страницу, я смотрю его IP, делаю запись в лог. Если id нет в tarantool_id, тогда я заношу автоинкрементом информацию об ip этого пользователя в базу, смотрю его id и возвращаю приветственную информацию data и присваиваю cookie значение id. В противном случае я считаю количество записей у нас в таблицах и возвращаю пользователю просто количество юзеров. И в конце, когда я описал функцию, я запускаю сам сервер и уже с ним работаю.
Это несложный пример, но благодаря модулям и расширяемости доступа языка lua его можно дописывать-дописывать-дописывать и через какое-то время довести до такого состояния, которое используется в реальных проектах.

У Tarantool’а очень много разных пакетов. Есть пакет работы с json’ом, есть пакет fiber (я ниже расскажу о нем чуть подробнее), есть пакет yaml, криптографическая библиотека digest (содержит основные необходимые механизмы шифрования). Есть свой пакет сокетов не блокирующих, и вы можете сами работать по сети, реализовывать какие-то протоколы, есть работа с msgpack’ом, если библиотечка file input output для работы с файлами. И есть интересный механизм net.box, он позволяет работать Tarantool’у по бинарному протоколу, например, с другим Tarantool’ом – это получается очень быстро и удобно. Также реализован net.box.sql для работы с какой-нибудь реляционной SQL базой данных

Файберы – это т.н. легкие потоки, которые работают по модели green threads. Основное отличие их от стандартных потоков – это то, что они работают внутри Tarantool’а, создаются внутри Tarantool’а, поэтому создаются они достаточно быстро, и у них неплохая производительность переключения. Они могут пригодиться вам, если вы реализуете какую-то асинхронную модель, или вам нужно, чтобы был запущен какой-то демон, выполняющий параллельно основной логике еще что-то.
Основные принципы работы с файбером: файбер нужно создать, файбер можно поставить в режим ожидания с механизмом fiber.sleep, и fiber_object – это есть fiber.create, вы можете его всегда консольнуть и завершить работу с ним.
Очень удобная библиотечка fiber.time, которая с event loop’а, считающего время, всегда может вывести нам нужное значение.
С помощью библиотечки fibers написана очень популярная используемая библиотека – это библиотека expirationd – это библиотека, которая может производить удаление из базы по каким-то признакам, обычно это время, т.е. все, что хранится месяц, может удаляться и очищаться.
Про Tarantool можно говорить долго, мы тоже не знаем всего, не знаю, знают ли разработчики все о нем. всегда можно почитать на документации tarantool.org, в последнее время она поменялась и стала более читабельной.

Tarantool поддерживает большинство Unix-подобных систем, у них есть свой buildbot, и мы всегда следим за появлением новых пакетов, мы работаем на red hat’e. И также разработчики Tarantool’а являются официальными мантейнерами пакета Tarantool в том же Debian’e.
И очень важный пункт, который мне нравится – это то, что в Tarantool’е возможна связь с разработчиками. У меня были вопросы, я нашел разработчиков в скайпе. Костя Осипов – главный разработчик Tarantool’а читал на этой конференции небольшой доклад про очереди. Это очень важно, особенно для начинающих разработчиков, – обратиться и узнать из первых уст, как делать то или иное. Надо быть готовым, что ребята, которые разрабатывают open source, весьма своеобразны, там весьма своеобразное комьюнити. Возможно, эта картинка сможет больше, чем я мог бы сказать:

Но в то же время, общение в комьюнити может быть очень интересным опытом, который позволит вам расти самому и делать свои проекты немного лучше.
В конце, хотел бы подвести итоги по докладу.

У каждого NoSQL есть своя сфера применения. Зачастую очень сложно сказать, какая база лучше, хуже, какая производительнее, они действительно часто решают разные задачи.
Инструмент разработки – это очень важно, правильно подобранный инструмент позволяет вам разрабатывать быстро и легко и избежать массы проблем, но не стоит забывать, что идея, цель – важнее, все-таки задача каждого разработчика – это решать проблему, реализовывать какие-то свои идеи и делать этот мир немножко лучше.
Надеюсь, я смог показать вам, что Tarantool совсем несложный, и вы можете попробовать его использовать тоже. Спасибо за внимание.