Строим сервисы на базе Nginx и Tarantool
Переходим от теории к практике — в прошлом письме мы с вами изучили теорию построения СУБД в оперативной памяти, а следующие два письма будут посвящены конкретной реализации и использованию таких СУБД на примере платформы Tarantool. Открывают тему Андрей Дроздов и Василий Сошников.
Андрей Дроздов и Василий Сошников (Mail Ru)

Константин Осипов: Долгое время то, что мы делали с Tarantool, было достаточно эзотерической штукой, потому что не было людей, которые, вообще, могли это как-то применить или объяснить, как это можно применить. И вот, наконец-то, такие люди появились. Они не просто взяли какую-то эзотерическую базу данных, а сделали на ней что-то полезное. И если вас эта технология интересует, то это люди, к которым вам стоит идти. Вам нужно идти не ко мне, потому что я какой-то хардкорный гик, который не понимает человеческих проблем, и я с трудом разговариваю на таком языке. Эти люди попробовали сделать то, что они сделали – поженили Tarantool с Nginx, сделали из этого какую-то полезную штуку. Вау! Я бы этого сделать не смог. Поэтому – «Строим сервисы на базе Nginx и Tarantool».
Василий Сошников: Спасибо, Константин, думаю, это было неплохое представление.
Мы будем говорить, как строить сервисы на базе Nginx и Tarantool – это первая часть этого доклада, я вас познакомлю чуть больше с Upstream-модулем. Во второй части Андрей, мой коллега, расскажет о том, как в Tarantool реализован шардинг. И третья часть – мы вам покажем отчет, о том какой RPS, какой лейтенси и какие показатели мы смогли со всего этого снять на реальных данных.
Немножечко фактов о Tarantool. Tarantool – это не только база данных, как многие знают, это еще потрясающе гибкий и мощный application-сервер. В нем также присутствует шардинг, в нем есть мастер-мастер репликация асинхронная, в нем есть снепшоты…
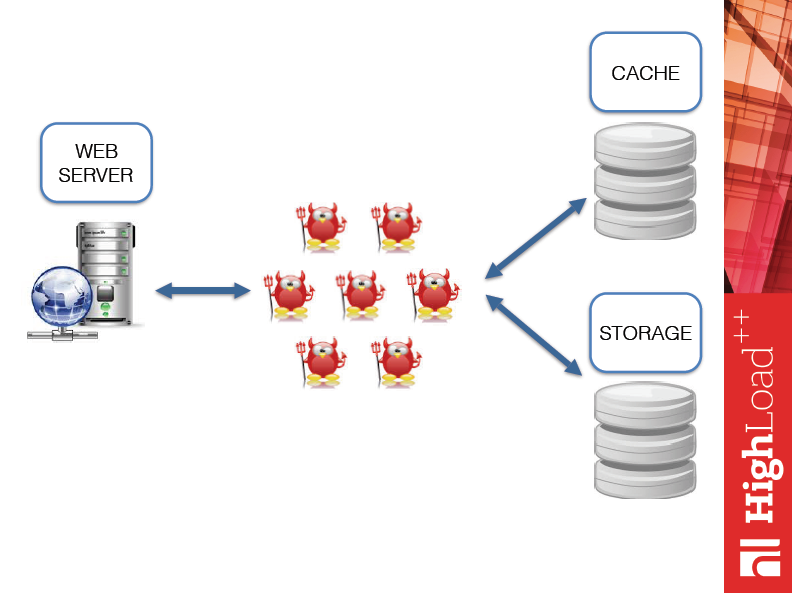
Думаю, многим из вас известна эта схема: у нас есть некий хоровод демонов, который пляшет между кэшем, стораджем и веб-сервером. Решая какие-то практические бизнес-задачи, вы всегда сталкиваетесь с проблемой не только бизнес – как решать ту или иную логику, – но и с вопросами: какой фреймворк использовать, какие протоколы использовать, как правильно синхронизировать кэш и сторадж, что с этим всем делать? Поэтому, т.к. у Tarantool есть прекрасное свойство, а именно application-сервер, я подумал: «Почему сразу не ходить из Tarantool в Nginx? И как у нас изменится эта схема?».
А изменится она так:
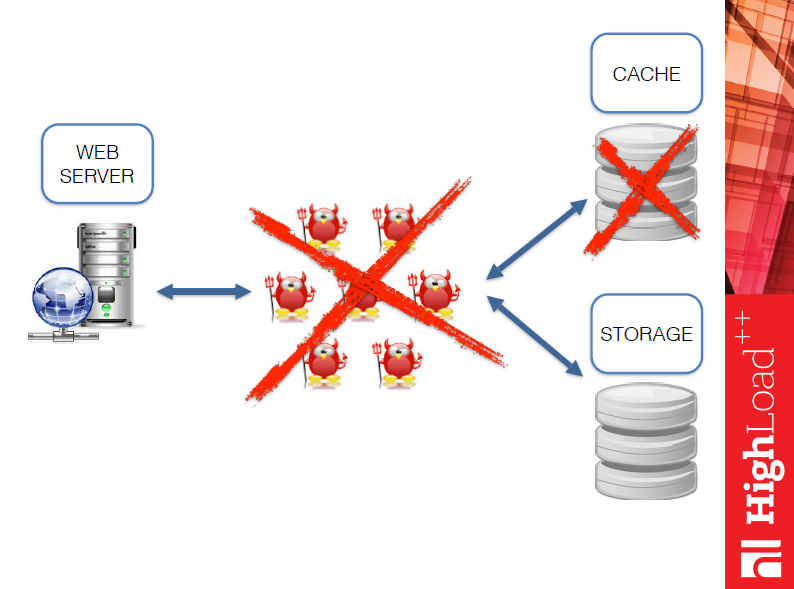
Уходит набор разносортных демонов, возможно даже на разных языках, и уходит кэш, поскольку Tarantool изначально все-таки база данных. И схема наша будет выглядеть так:
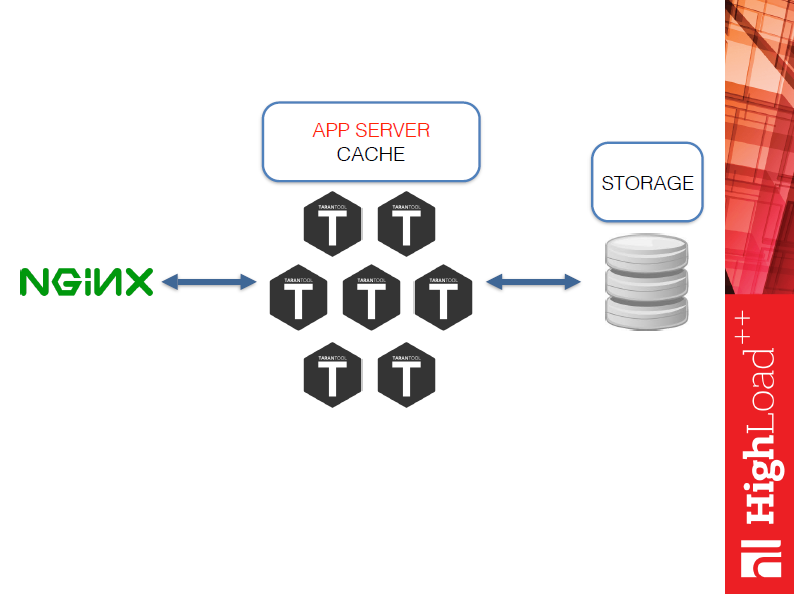
О ней немного подробнее. Nginx принимает данные от клиента (клиент может быть обычным браузером, может быть каким-то вашим демоном), кладет эти данные в Tarantool’льное выполнение, после чего получает ответ именно как application-сервер. Т.е. вы достаточно просто можете написать любой функционал на Lua.
Многие любят использовать Tarantool с каким-то другим стораджем, предположим MySQL, либо чем-то еще, поэтому сторадж я в этой схеме специально оставил. Он может быть, а может его и не быть, а, может быть, стораджем будет сам Tarantool.
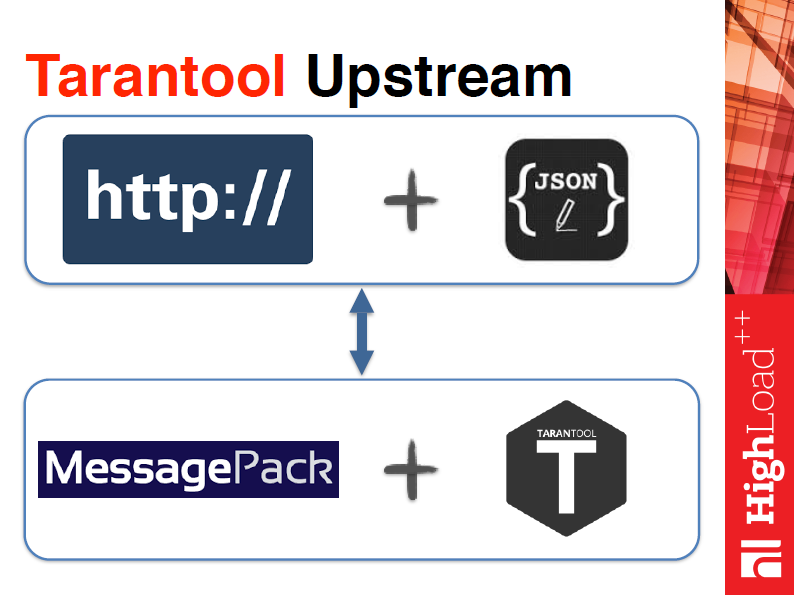
Немного об Upstream-модуле. Upstream-модуль базируется на http и Json. Json доставляется в Upstream-модуль посредством постзапроса. Это строго структурированный объект, где вы говорите имя метода, говорите, какие параметры, и говорите идентификатор сообщения. Похож на Json RPS. Имя метода и параметры, которые вы указали, преобразуются асинхронно в MassagePack (тот, который понимает Tarantool), уйдут в Tarantool, и произойдет вызов этой функции. После этого вам вернется результат.
Тут есть несколько интересных моментов. У Nginx, если не считать парсинг Json’а, этот модуль его сильно не тормозит, что мы покажем дальше.
А теперь реальный use case. Когда мы все это начали, возник вопрос: а действительно ли это так здорово и решает проблемы, с которыми мы сталкиваемся? И поэтому мы задумались, какую задачу решать? Естественно, поскольку мы люди амбициозные, мы решили выбрать задачу весьма сложную и взяли википедию. Википедия базируется на MySQL, она вся кэширована-перекэширована. Но мы решили взять не всю википедию, а только самую сложную ее часть, а именно граф категорий.
Что такое граф категорий? Граф категорий википедии – это статьи, термины и любые другие определения, на которых вы видите ссылки внутри википедии. Т.е. предположим, типичный случай графа категорий – вы начали читать об египетском фараоне, закончили читать о ложке. Казалось бы, как вы перешли туда? На этот вопрос мы тоже ответим.
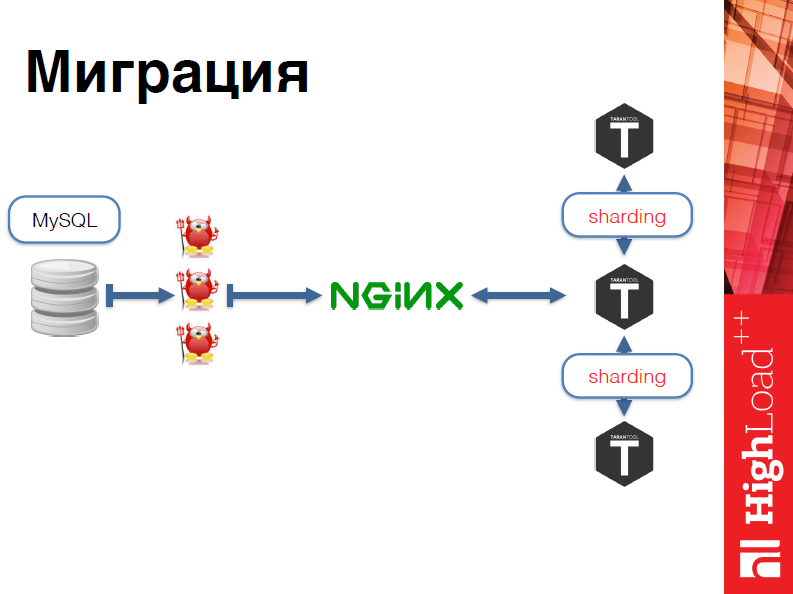
Теперь о миграции, как это происходило? Мы написали несколько демонов, которые из MySQL брали данные по википедии и преобразовывали их в Json, пихали в Nginx, Nginx пихал в Tarantool. После чего Tarantool в шардинге эти данные распределял, потому что википедия достаточно большая.
В чем главное преимущество этой схемы? Допустим, мы загрузили только русский сегмент википедии, мы бы захотели загрузить английский. Все, чтобы надо было сделать здесь – это просто добавить еще несколько машин. И конечная архитектура для википедии выглядит так:
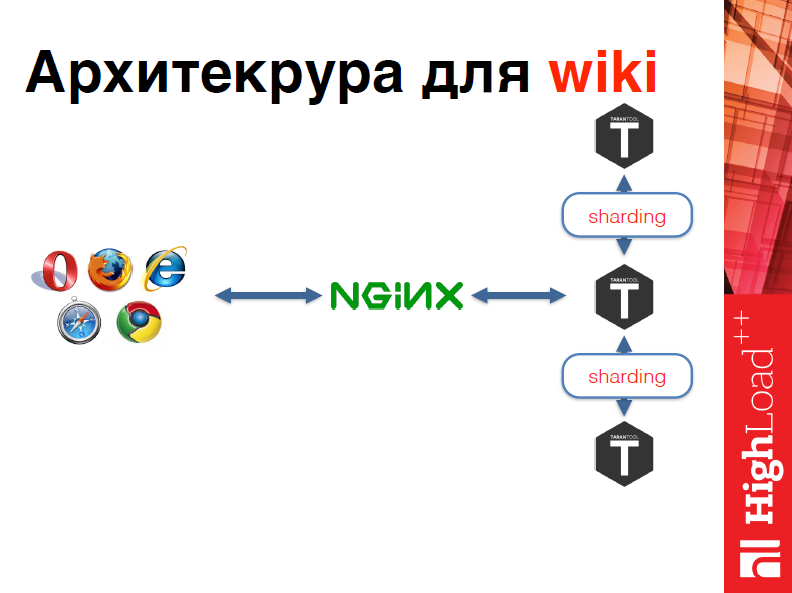
Т.е. у нас есть некоторые клиенты, которые ходят в Nginx, который в свою очередь ходит в Tarantool, берет данные и возвращает их клиенту.
Я упоминал о ложке и Фараоне. Давайте поищем связь вместе.
По этому URL’у – http://wiki.build.tarantool.org – сейчас висит этот сервис, вы можете туда зайти, что-то ввести, и он вам построит граф категорий. Вы поймете, насколько это интересно, и то, что связи там можно найти неожиданные. Ко всему прочему, там есть несколько нюансов – надо писать с большой буквы в поиске и слова разделять не пробелом, а нижним подчеркиванием. Мы просто не успели GUI допилить, потому что на весь этот проект мы с Андреем потратили один день выходных, т.е. где-то 8-9 часов, что доказывает, что это сделать действительно просто. Очень просто данные, которые лежат, устоялись, которые сделаны через избыточность как MySQL, их можно легко, просто и компактно разместить в Tarantool.
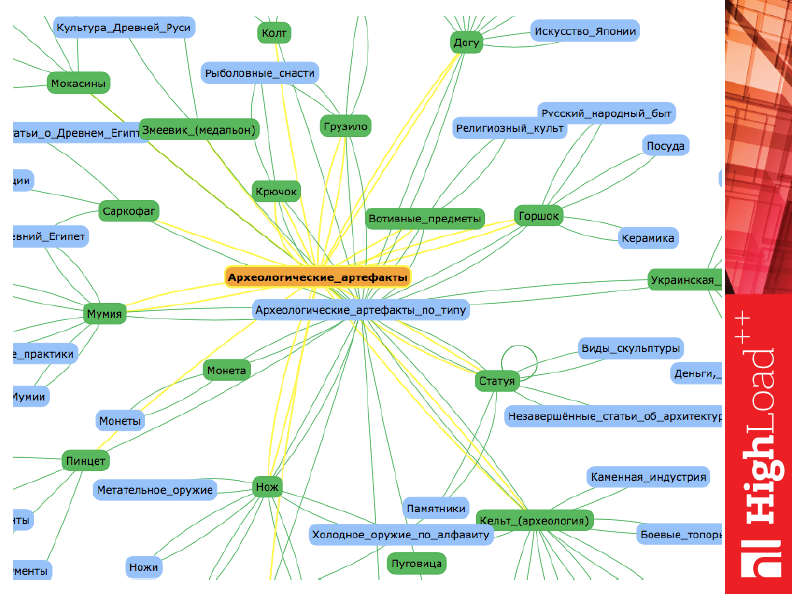
Для тех, кто не вышел в Интернет, это пример того графа, который будет там представлен. Т.е. как видно, связано через археологические артефакты.
Андрей Дроздов: Привет, теперь я расскажу о том, как устроен шардинг. Очень многие из вас сталкиваются с шардингом по работе. Думаю, основная идея понятна: когда возникает такая ситуация, что хранить данные на одном компьютере невозможно, мы прибегаем к шардингу.
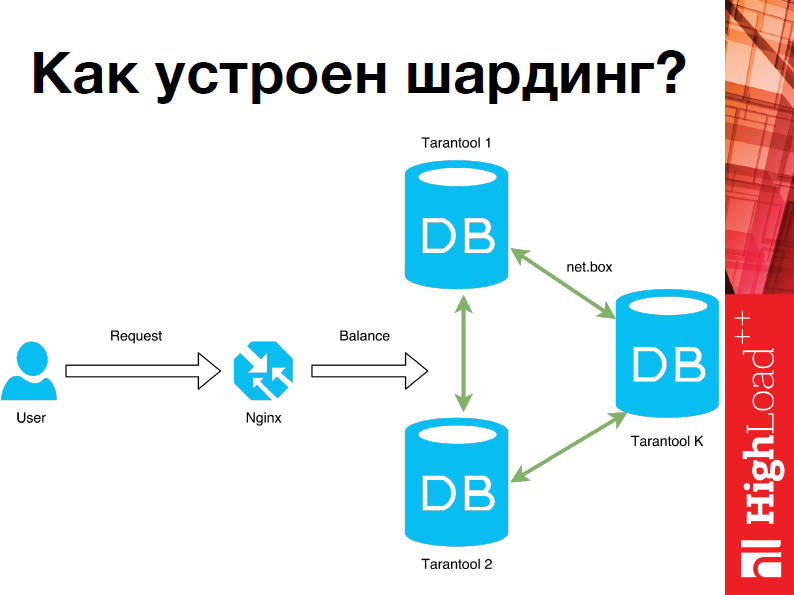
В нашем случае мы еще используем Nginx, хотя это абсолютно не обязательно, т.е. Tarantool может быть абсолютно самостоятельным в этом плане, это удобно.
Первое понятие, с которого я хотел бы начать – это «Зоны и избыточность»:
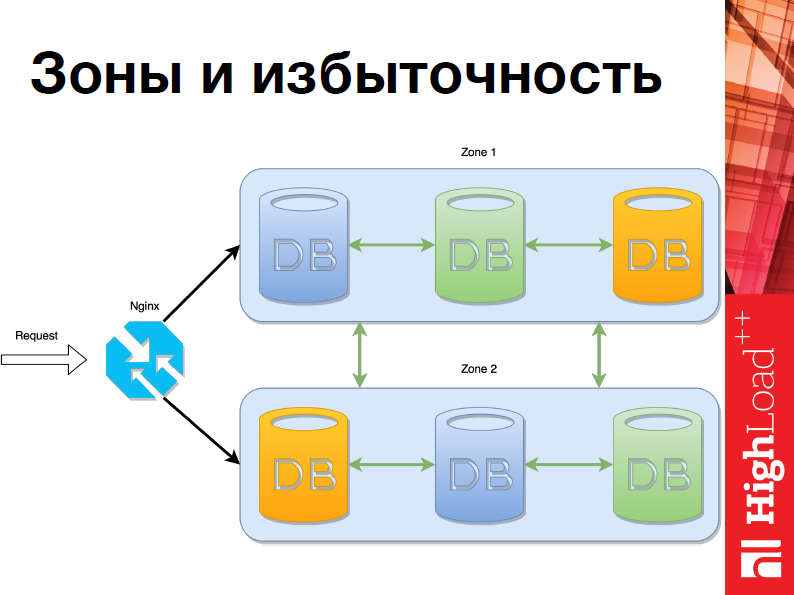
Представим, что у нас есть несколько датацентров. Один, предположим, находится в Москве, другой – в Красноярске. В шардинге в Tarantool реализовано разбиение на зоны, для того чтобы было удобнее использовать, из этого вытекает понятие избыточности. На данном слайде мы видим пример системы, в которой есть две зоны и избыточность равна двум. Т.е. в каждой зоне данные дублируются. Это очень удобно для надежности.
Ключевое понятие, которое нам понадобится, чтобы разработать свою систему шардинга – это шард-функция. Т.е. та функция, которая на основе полученных данных решает, на каком из серверов мы должны выполнять операцию.
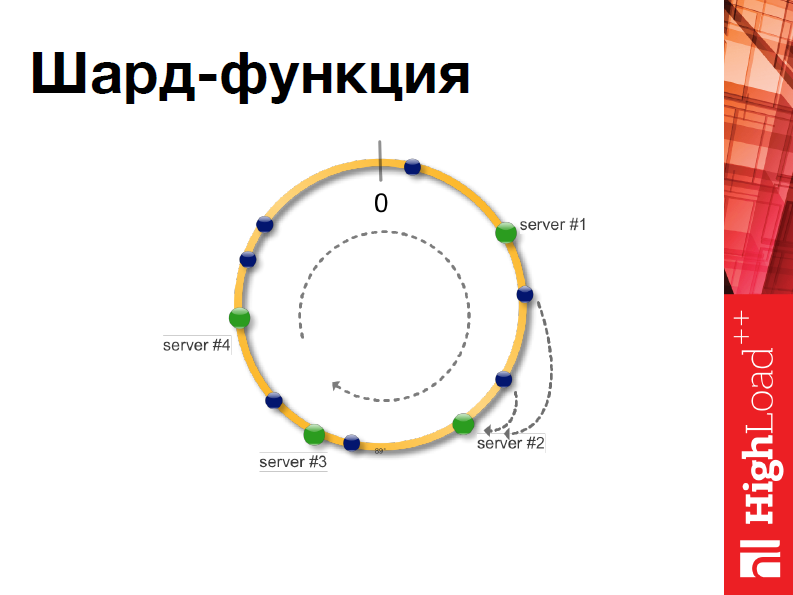
Для этого мы будем использовать консистентное хэширование. Если в двух словах, мы представим себе некую окружность и все наши сервера отобразим на нее. Когда приходят новые данные, мы выбираем некий признак, по которому мы эти данные также отобразим на окружность, и, соответственно, мы попадем на нужный нам сервер.
Это удобно тем, что если вдруг во время работы нашей системы что-то случается, например, сервер выходит из строя, то нам не нужно перехэшировать все.
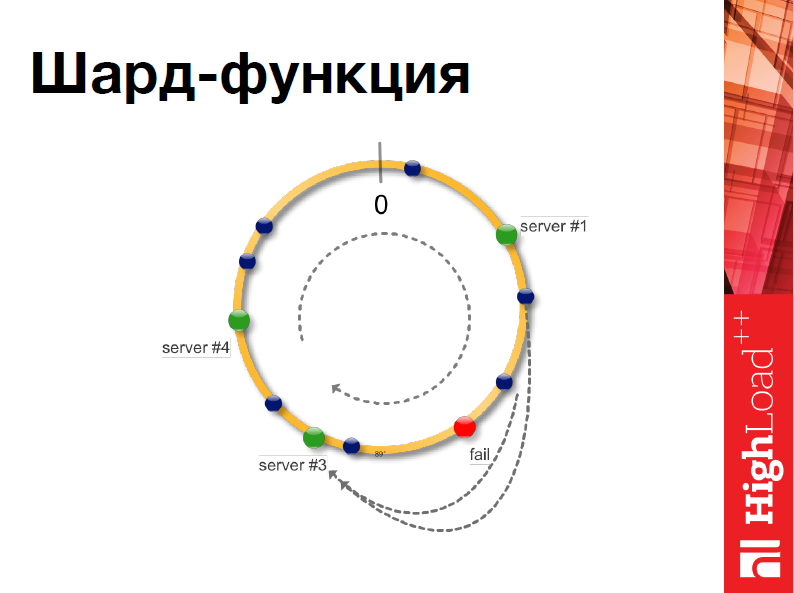
Таким образом, это повышает надежность.
Помимо этого в нашем шардинге реализована система мониторинга, так сказать, госсип лайк мониторинг.
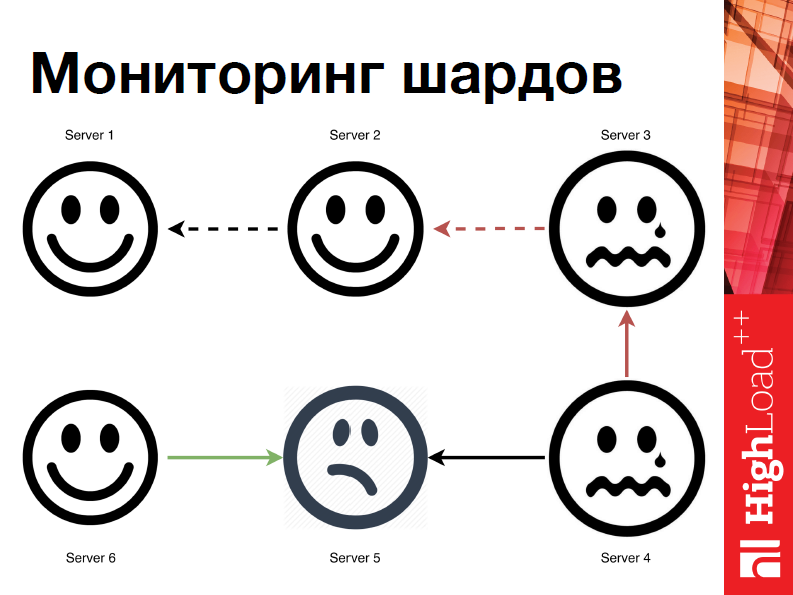
Что это значит? Как только какая-то нода выходит из строя, система может понять, что что-то идет не так. Каждый узел сканирует все остальные узлы и узнает у них их видение мира. Таким образом, если одна нода вышла из строя, другая узнает об этом, и эта информация распространится по всей системе. Как только все узлы будут знать, что какой-либо другой узел вышел из строя, они его исключат, а система продолжит корректную работу.
Поясню на примере. Предположим, что у нас есть 2 сервера Tarantool. Мы объединили их в шардинг и начали работать.

Сейчас мы видим процесс инициализации, т.е. в поле Timestamp у нас начальные значения, и вот началась штатная работа.

Никаких ошибок нет, все работает корректно, все классно. Как вдруг… Представим себе, один датацентр взорвался.

Пошли ошибки, первая нода пытается достучатся до второй, но что-то не так, однако, пока мы еще не уверены. Это, разумеется, задается некоторым порогом, т.е. можно выбрасывать ноду сразу при возникновении ошибки, но, предположим, в нашем случае мы дадим 10 попыток. Предельное число достигнуто, кластер понял, что пора исключить ноду, и система продолжила свою работу.

Теперь, когда у нас есть шард-функция и мониторинг, мы можем попробовать пошардить. Какое решение приходит сразу?
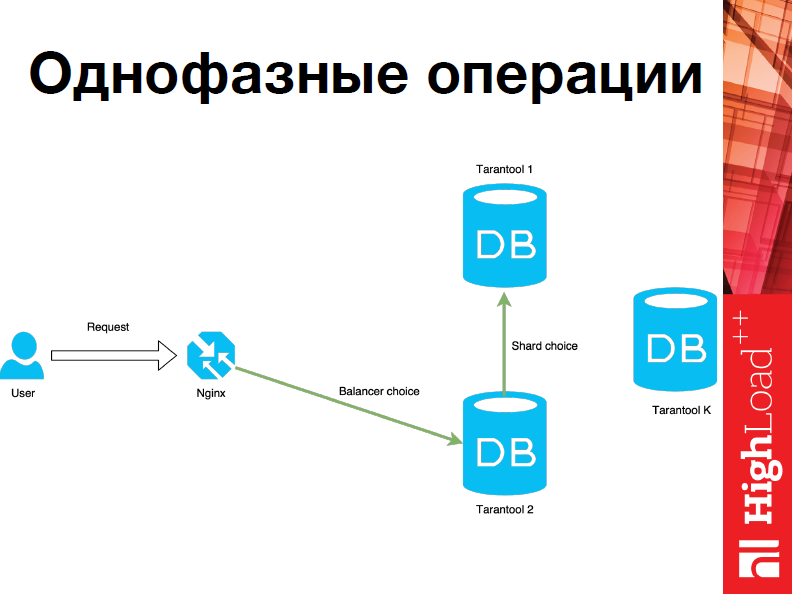
Это однофазные операции, т.е. к нам приходит запрос, мы выбираем узел, на который мы хотим пошардить наши данные, выполнить там операцию, идем на него и выполняем.
Однако мы можем работать не только так, но об этом чуть позже.
Сначала, я расскажу о том, как это будет выглядеть, если вы будущий пользователь Tarantool’а или, может быть, нынешний.

Вы сконфигурировали шардинг, и вы не общаетесь с каждым сервером отдельно, т.е. вы работаете с шардом, со всем кластером так, будто вы работаете с одним Tarantool’ом. Это в некотором смысле очень удобно. Т.е. вы просто выполняете операции и не задумываетесь. Однако если же все-таки мы хотим использовать нашу систему более сложным образом, например, нам понадобятся транзакции, то однофазные операции нам уже не подойдут. Поэтому был реализован двухфазный протокол.
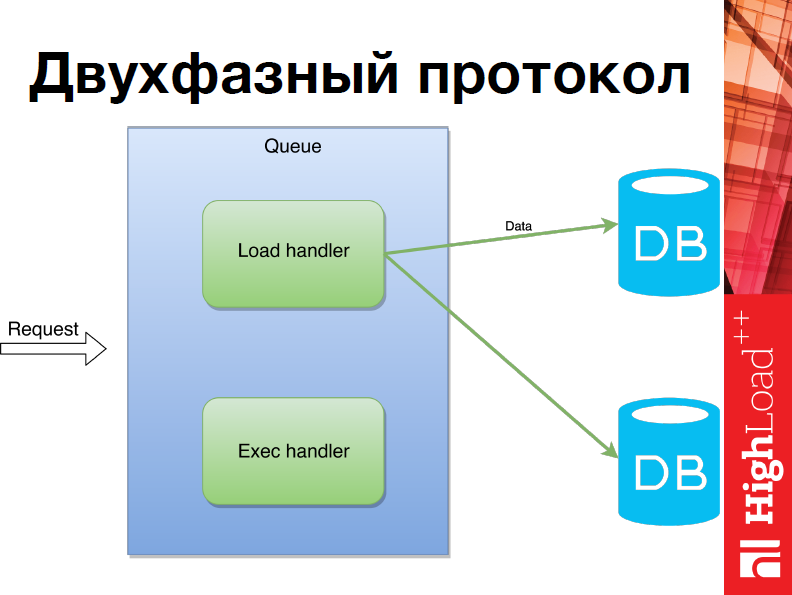
Что это значит? Когда приходит запрос, для начала мы находим все шарды, на которых операция должна быть исполнена, после чего мы рассылаем все данные и только когда мы удостоверились, что все операции были разосланы по нужным шардам, мы начинаем их исполнять.
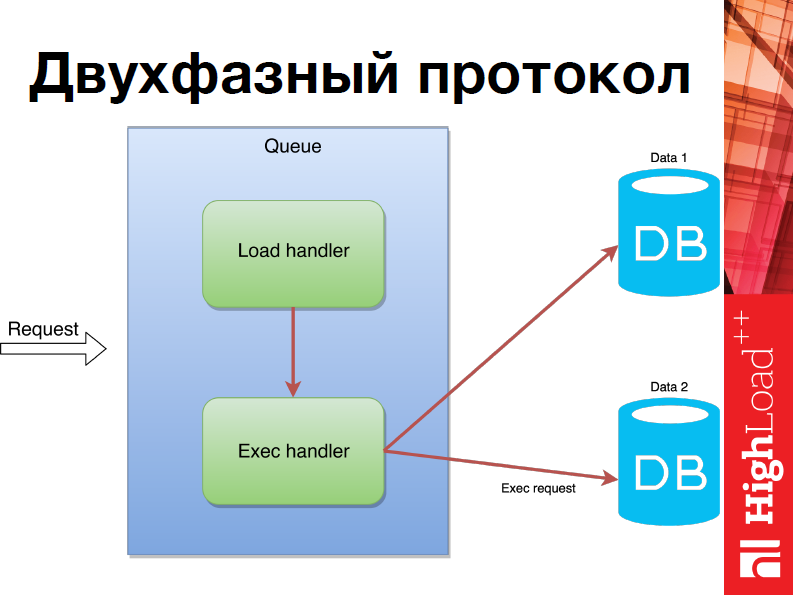
Кроме того, в нашем шардинге реализован Батчинг:
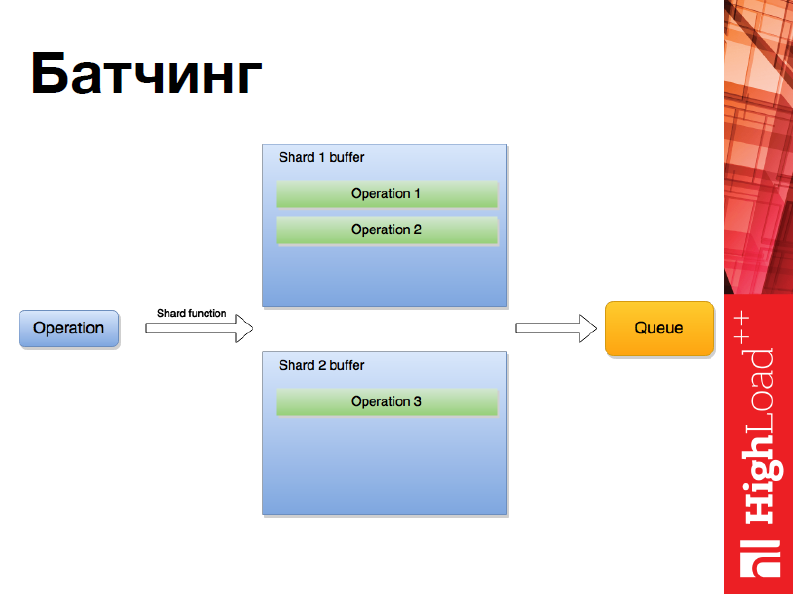
Т.е. мы можем исполнять несколько инструкций сразу, но реализовано это через несколько буферов, которые создаются, – мы их заполняем операциями, и все также через очередь отправляется по шардам.
Вот так выглядит двухфазный протокол в коде:

Если вы будете использовать, то достаточно сказать q_begin, q_end, точно так же, как с транзакциями, и выполнять соответствующие операции.
Обращу внимание, что помимо того, что мы передаем тапл с данными, которые нам нужны для операции, нужно еще передавать уникальные id операции – это нужно для некой консистентности относительно всего кластера. Это может быть какой-нибудь номер транзакции в реальных системах. Такой идентификатор можно найти.
Так выглядит конфигурация:

Если вы не знакомы с Tarantool, вы можете установить из репозиториев сам Tarantool, модуль с шардингом, модуль Nginx и сконфигурировать его следующим образом – вы просто указываете сервера, логин, пароль, избыточность и порт. Все это представляет собой просто Lua’шную таблицу. После чего вы это передаете модулю шардинга, он запускается и все работает.
Представим, что мы написали такой модуль шардинга, разумеется, он полностью написан на Lua. Хорошо бы его проверить. Нам понадобилось придумать тест, который бы достаточно строго на реальных данных оценивал, как работает наша система, потому что так бывает, что придумаешь бенчмарк, но он совершенно не отражает реальной жизни. Хотелось хотя бы как-то к этому приблизиться.
Реальные условия: у нас есть восемь 4-х ядерных серверов с 64-мя Gb оперативной памяти, и мы планируем гонять по ним 100 Gb данных с избыточностью, т.е. на самом деле 200ь Gb, и размер одного запроса будет 2 Кбайта, т.е. такой большой Json.

И мы захотели узнать, сколько из системы с такой архитектурой можно будет выжать производительности и RPS.
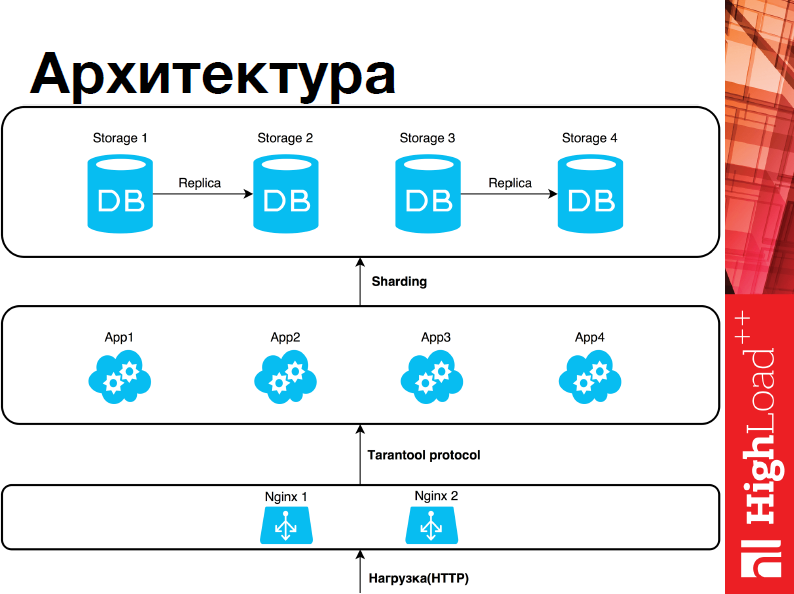
Архитектура у нас выглядит следующим образом:
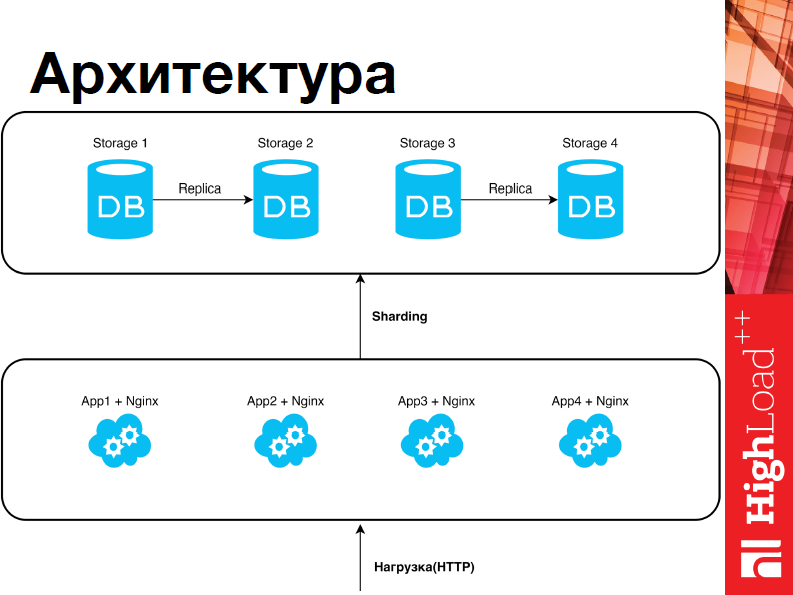
У нас есть два слоя, один из них – слой данных, где стораджи, а второй – слой бизнес-логики, т.е. upserver’а. И те, и другие являются Tarantool’ами, плюс в up-слое находится Nginx, который непосредственно взаимодействует с Tarantool’ом. В слой приложения приходит нагрузка. Upserver’a выбирают, куда именно мы хотим шардить, отправляет операции, и они исполняются. Все достаточно тривиально. Помимо этого, у нас есть две зоны – это первый и второй сторадж, третий и четвертый, между ними настроена репликация.

Теперь, когда мы придумали наш тест, хорошо бы решить, что есть хорошо, и что есть плохо. Для этого у нас есть четыре метрики, и, помимо этого, тест с отключением всех мастеров. Т.е. мы просто берем в какой-то момент под нагрузкой и отключаем все мастера. После этого проверяем, чтобы на сетевом уровне не было ни одной ошибки, чтобы на уровне http-протоколов были только 200, никаких 500, что сам Tarantool не выдал никаких эксепшенов в Lua.
Еще у нас есть тест на апдейты – нам нужно, чтобы количество запросов, которые мы послали, соответствовало количеству апдейтов в Nginx, которые там произошли, что вполне логично.
Первый тест, тест на чтение:
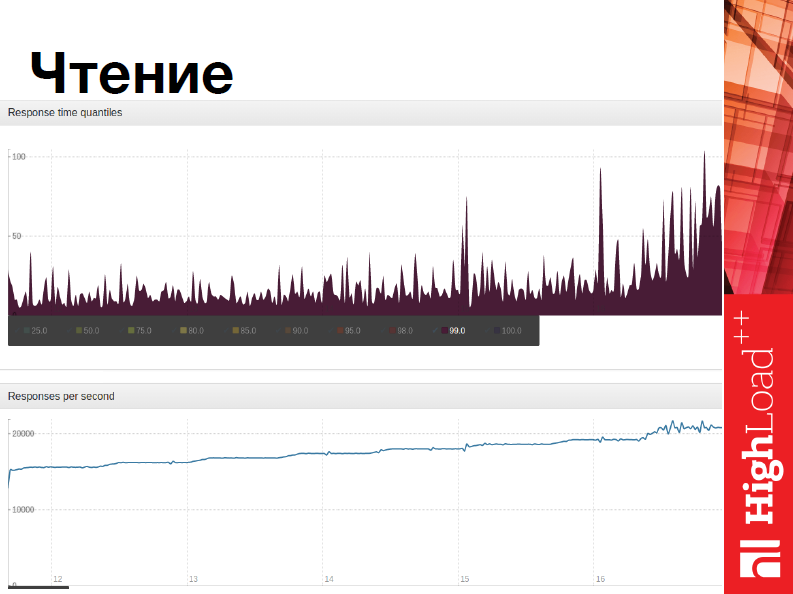
Мы использовали утилиту для нагрузочных тестов. Заключался тест в очень простых условиях, т.е. мы просто создавали некую нагрузку и пытались считать из множества данных порядка 100 млн. записей, предположим, от пользователя. На графиках видно, что нагрузка на один upserver (измерения проводились именно на нем) достигает чуть больше, чем 20 тыс. запросов в секунду. Всего в нашей системе было таких четыре, соответственно, общая производительность системы была порядка 80-ти. На верхнем графике изображена задержка, т.е. лейтенси, и мы видим, что средняя не превышает 50 мс, а максимальная не превышает 120 мс.
Второй тест был тестом на запись.
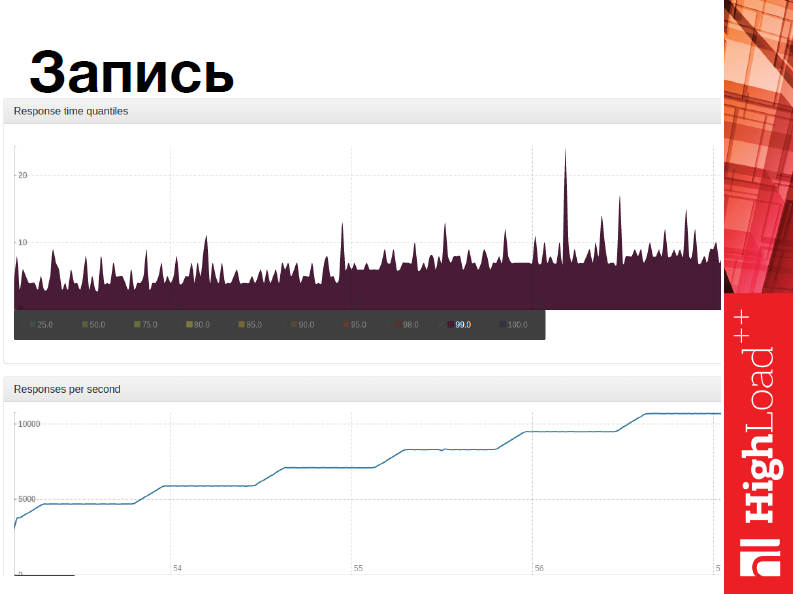
Мы тоже плавно повышали нагрузку и пытались инкрементить некоторые записи в тех же данных, которые мы считывали в предыдущем тесте. Т.е. мы указываем некий id’шник и там происходит «+1». В этом тесте производительность достигала 45 тыс. запросов в секунду, поскольку у нас четыре upserver’a и лейтенси была меньше 30 мс.
Последний тест – самый интересный – это отключение узла.
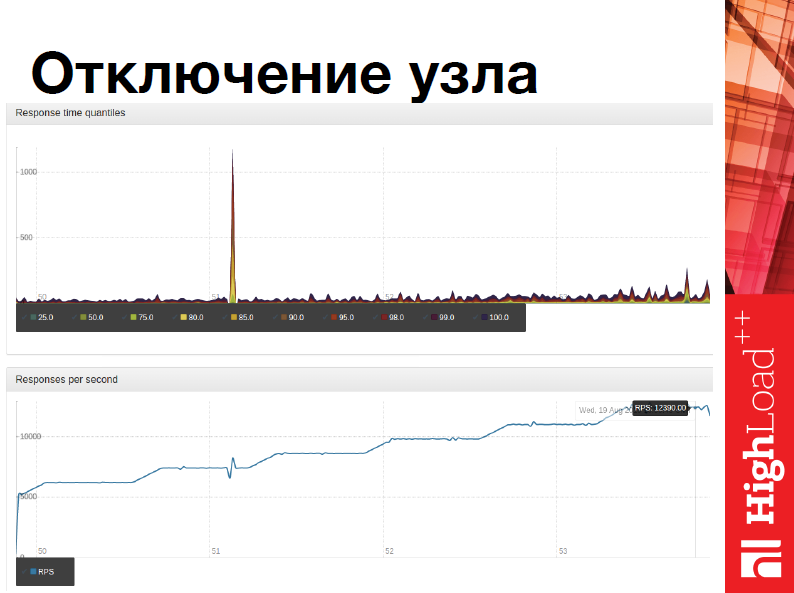
Он полностью повторяет тест на запись с той лишь разницей, что в какой-то момент мы берем и вырубаем все мастера. Что происходит? Выключаются мастера, система upserver’a понимает, что что-то пошло не так, все запросы переключаются на реплики, и система восстанавливается, продолжает работу.
На графике очень явно виден пик – это момент переключения и, соответственно, время переключения меньше 5 секунд. Я не знаю, хороший это или плохой показатель, но, тем не менее, наверно, хороший.
После этого мы получили цифры в 80 тыс. запросов в секунду на чтение и порядка 40тыс. – на запись. Потом мы решили, что надо выжать максимум и унесли Nginx с up-слоя, и посмотрели, что получилось.

Итоговая производительность составила 100 тыс. запросов в секунду на чтение, 47 тыс. запросов – на запись. И тест на отключение мастеров показал такую же производительность, т.е. не было потери в производительности, несмотря на то, что мы отключили какую-то часть серверов. И время восстановления лейтенси было меньше 5-ти секунд.
На этом все.
То, что было разработано, разумеется можно попробовать использовать.
Есть пример на Гитхабе этой маленькой системы с википедией, ее скорее удобно использовать как демку для того, чтобы попробовать что-то свое разработать с Nginx и шардингом. И ссылки на шард и Nginx модулю тоже здесь представлены.
Василий Сошников: Я хотел Андрея дополнить: клиенты – это был Яндекс.Танк; и второе – было 1000 параллельных коннектов, которые были не постоянны во время всего тестирования, которые могли еще при этом прерываться, что очень важно. Собственно, все.