Асинхронная репликация без цензуры
Олег Царёв (Mail.Ru Group)

Есть мастер, мастер неожиданно упал, но система продолжает работать. Клиенты мигрируют на вторую базу. Нужно делать резервные копии базы. Если делать резервные копии на основной базе, мы можем получить какие-то проблемы производительности, увеличение времени отклика. Это плохо. Поэтому достаточно распространенный пример асинхронной репликации – это снятие резервной копии со слэйва. Другой пример – это миграция тяжелых запросов с мастера на слэйв, с основной базы на вторую. Например, построение отчетов.
Иногда бывает необходимо, чтобы приложение могло получать все обновления из базы и желательно в режиме реального времени. Этим занимается оpen source библиотека, которая называется libslave.
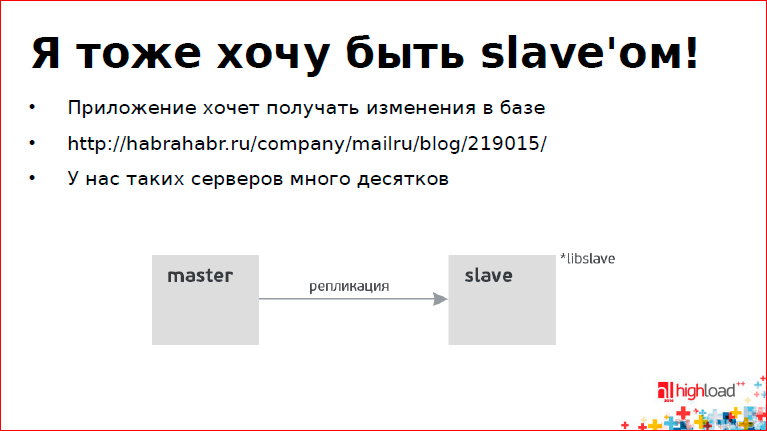
Сходите по ссылке на слайде, почитайте – отличная статья.
Если собрать все вместе, мы получим примерно такую картинку:
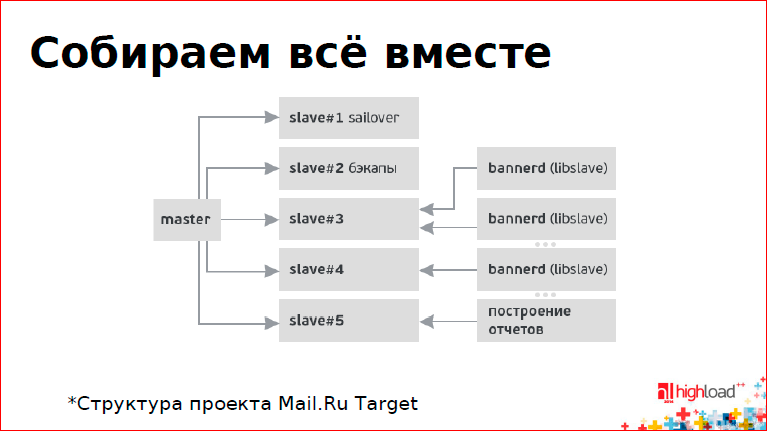
У нас есть один мастер и куча слэйвов – seilover для резервирования, если мастер упал, слэйв для бэкапов, слэйв для построения отчетов, и несколько слэйвов, которые ретранслируют изменения на штуку, которая называется bannerd (это название демона, и он работает через libslave). Их много, поэтому стоят такие вот прокси.
У нас достаточно большой проект с достаточно большой БД, при этом мы всегда работаем, наш сервис не падает. Мы раздаем рекламу, и у нас достаточно серьезная нагрузка, репликация у нас используется повсеместно.
Основное свойство БД – то, что она гарантирует принцип "все или ничего", т.е. изменения происходят либо целиком, либо не происходят, вообще. Как это делается, как база гарантирует целостность данных?
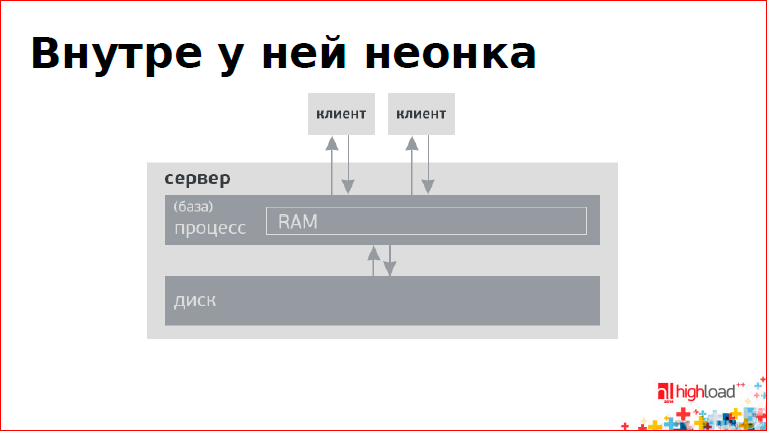
Есть сервер, оперативная память, диск, клиенты, которые ходят к базе. Память организована в виде страничек. Когда приходит какой-то запрос на обновление данных, страница модифицируется сначала в оперативной памяти, потом попадает на диск.
Проблема в том, что принцип "все или ничего" на современном "железе" не представляется возможным. Это физические ограничения мира. Даже с оперативной памятью – транзакционная память появилась лишь недавно у Intel'а. И непонятно, как с этим жить... Решением является журнал:
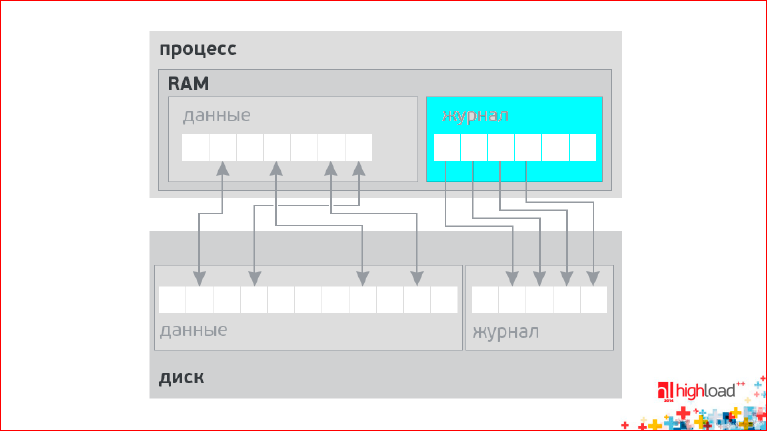
Мы пишем в отдельное место – в журнал – то, что мы хотим сделать. Мы сначала пишем все данные в журнал, а после того, как журнал зафиксирован на диске, мы изменяем сами данные в памяти. Потом, возможно, сильно позже, эти данные окажутся на диске. Т.е. журнал решает много проблем. Консистентность данных – лишь одна из функций.
Этот алгоритм называется Point In Time Recovery или PITR. Предлагаю ознакомиться с информацией по ссылкам:

Это весьма познавательно.
Главные вопросы, которые встают перед разработчиком любой БД:
- как организовывать журнал?
- как его писать?
- как писать его меньше?
- как сделать так, чтобы это работало быстрее?
- при чем тут репликация?
Прямой способ сделать репликацию – это скопировать журнал с мастера на слэйв и применить его на слэйв. Журнал используется для гарантии консистентности данных. Тот же самый механизм можно применить к слэйву. И мы получаем репликацию, по сути, почти ничего не добавляя в нашу систему.
PostgreSQL работает именно так. Журнал у него называется Write-Ahead Log, и в него попадают физические изменения, т.е. обновления страничек. Есть страница в памяти, на ней лежат какие-то данные, мы с ней что-то сделали – вот эту разницу мы записываем в журнал, а он потом уезжает на слэйв.
Сколько журналов в MySQL? Давайте разбираться. Изначально в MySQL не было никаких журналов, вообще. Был движок MyISAM, а в нем журнала нет.
На рисунке вы можете видеть штуку, которая называется Storage Engines:
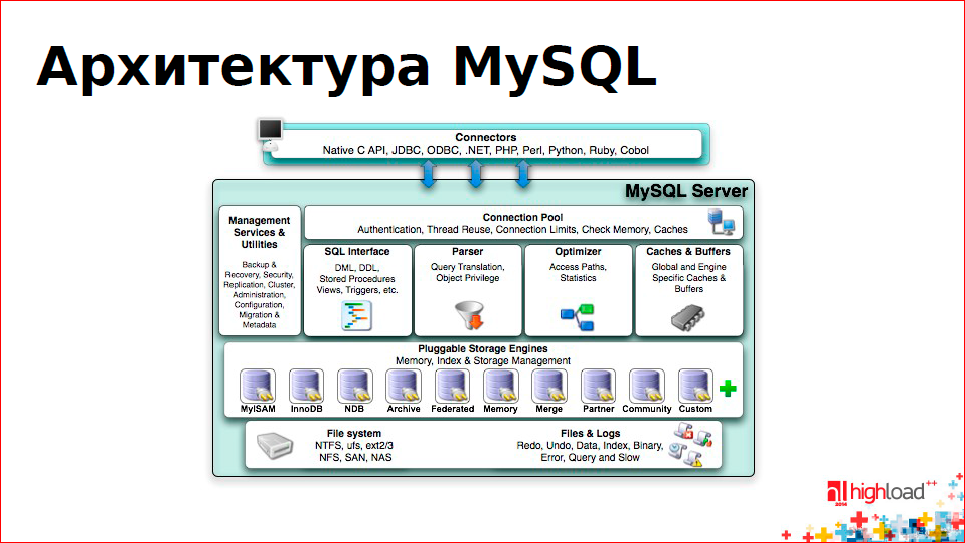
Storage Engine – это такая сущность, которая занимается вопросами, как писать данные на диск и как нам их оттуда читать, как по ним искать и пр.
Потом прикрутили репликацию. Репликация – это одна строчка в самом левом верхнем квадратике – Management Services&Utilites.
Для репликации потребовался журнал. Его начали писать. Он называется Binary Log. Никто не думал про то, чтобы его использовать как-то иначе, просто сделали.
Примерно в это же время MySQL подарили новый Storage Engine, который называется InnoDB. Это широко используемая штука, и в InnoDB свой журнал. Получилось два журнала – InnoDB и Binary Log. Этот момент стал точкой невозврата, после чего появились проблемы, которые решить очень тяжело.
Binary Log не используется для Point In Time Recovery, а InnoDB Undo/Redo Log не используется в репликации. Получилось, что у PostgreSQL журнал один, а у MySQL их, как бы, два, но у Binary Log, который нужен для репликации, есть два или три формата (типа).
Самый первый тип, который появился, который было проще всего сделать, это Statement-based Binary Log. Что это такое? Это просто файл, в который последовательно пишутся транзакция за транзакцией. Это выглядит примерно так:

В транзакции указывается БД, на которой совершаются эти обновления, указывается timestamp времени начала транзакции, и дальше идет сама транзакция.
Второй тип называется Row-based репликация. Это журнал, в который пишутся не сами запросы, а те строчки, которые они меняют. Он состоит из двух частей – BEFORE image и AFTER image:
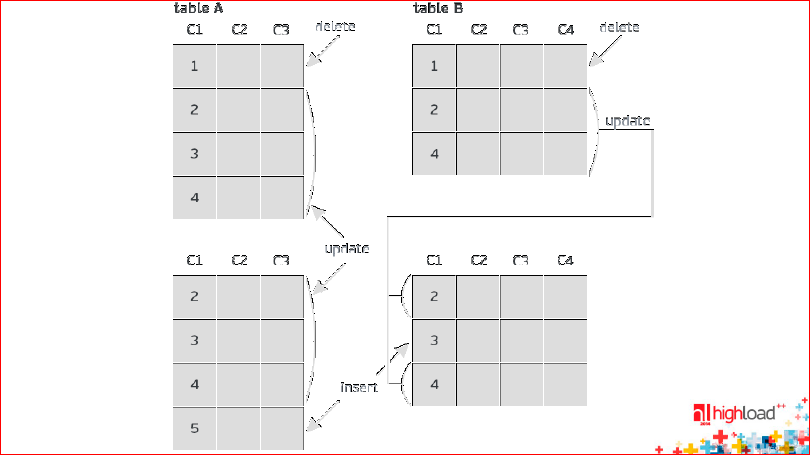
На картинке BEFORE image сверху, а AFTER image – внизу.
В BEFORE image помещаются те строчки, которые были до выполнения транзакции. Красным цветом помечены строчки, которые удаляются:
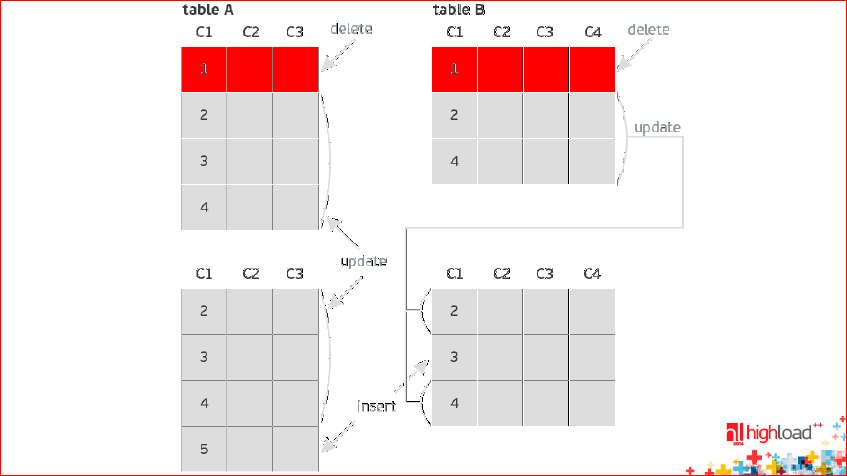
Они из BEFORE image наверху, но их нет внизу – в AFTER image, значит, они удаляются.
На следующей картинке зеленым помечены строчки, которые добавились:
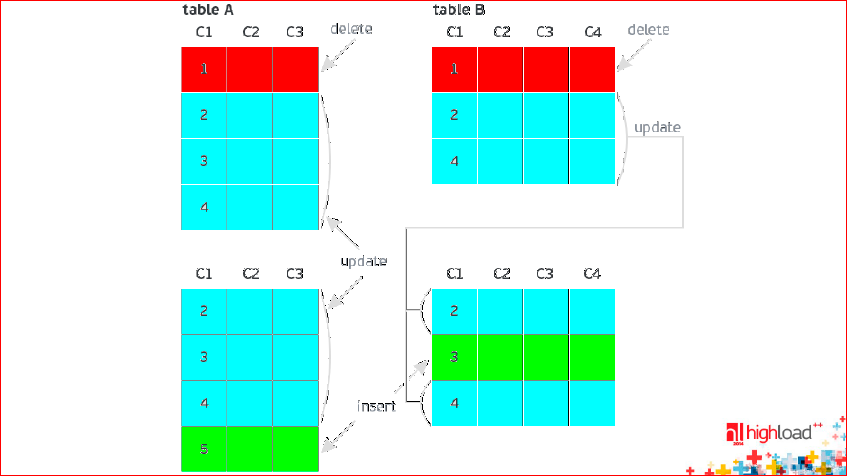
Синие UPDATE'ы есть и в BEFORE image, и в AFTER image. Это обновления.
Проблема такого решения связана с тем, что до недавнего времени в Row-based репликации писались в log все колонки, даже если мы обновили одну. В MySQL 5.6 это починили, и с этим должно стать полегче.
Есть еще один тип Binary Log'а – Mixed-based. Он работает либо как Statement-based, либо как Row-based, но он широко не распространен.
Какой из этих журналов лучше?
Вначале поговорим о реляционных таблицах. Часто думают, что реляционная таблица — это массив. Некоторые даже думают, что это двумерный массив. На самом деле, это гораздо более сложная штука. Это мультимножество – набор определенного сорта кортежей, над которым не задано порядка. В SQL-таблице нет порядка. Это важно. И, как результат, когда вы делаете SELECT* из БД (просканировать все записи), результат выполнения запроса может меняться – строчки могут быть в одном порядке, а могут и в другом. Про это нужно помнить.
Вот пример запроса, который в Statement-based репликации будет работать некорректно:

Мы из таблицы удалили primary_key и добавили новый – авто-инкрементный. На мастере и слэйве разный порядок строчек. Так мы получили неконсистентные данные. Это особенность Statement-based репликации, и с этим сделать можно не так уж много.
Это цитата из официальной MySQL-документации:

Нужно создавать еще одну таблицу, в нее переливать данные, а потом ее переименовывать. Эта особенность может "выстрелить" в самых неожиданных местах.
Наверное, следующий слайд – один из самых важных в докладе, о том, как репликацию можно классифицировать:

Работа на уровне хранилища, как делает PostgreSQL, называется физической репликацией – мы работаем напрямую со страницами. А Row-based репликация, где мы храним набор кортежей до и после транзакции, – это логическая.
А Statement-based репликация, вообще, на уровне запросов. Так не делают, но так сделано... Отсюда следует важное интересное свойство: когда у нас работает Row-based репликация, т.е. логическая репликация, она не знает, как именно данные хранятся на диске. Получается, для того чтобы репликация работала, нужно совершать какие-то операции в памяти.
Также выходит, что физическая репликация (PostgreSQL, InnoDB) упирается, в основном, в диск, а MySQL-репликация упирается, в основном, в слэйв, причем обе – и Row-based и Statement-based. Row-based нужно просто найти строчки и сделать обновление, а со Statement-based все гораздо хуже – для нее нужно выполнить запрос. Если запрос на мастере выполнялся, например, полчаса, то он и на слэйве будет выполняться полчаса. Это репликация, но достаточно неудачная.
Кроме того, PostgreSQL пишет на диск в два места – в хранилище данных и в журнал. У MySQL таких мест три – хранилище (tablespace), журнал (undo/redo log), и Binary Log, который используется в репликации, т.е. писать на диск нужно в 1,5 раза больше. MySQL – отличная архитектура, но с ней часто бывают проблемы.
Многие видели отстающие реплики MySQL. Как найти причину торможения реплики? Диагностировать тяжело. Есть средство диагностики в MySQL, называется log медленных запросов. Вы можете его открыть, найти топ самых тяжелых запросов и исправить их. С репликацией это не работает. Нужно проводить статистический анализ – считать статистику – какие таблицы стали чаще использоваться. Вручную это сделать очень тяжело.
В MySQL 5.6 / 5.7 появилась SLAVE PERFORMANCE SCHEMA, на базе которой такую диагностику провести проще. Мы обычно открываем лог коммитов в puppet и смотрим, что же мы выкатили в то время, когда репликация начала отставать. Иногда даже это не помогает, приходится ходить по всем разработчикам и спрашивать, что они сделали, они ли сломали репликацию. Это грустно, но с этим приходится жить.
В асинхронной репликации есть мастер, куда мы пишем, и есть слэйв, с которого только читаем. Слэйв не должен влиять на мастера. И в PostgreSQL он не влияет. В MySQL это, к сожалению, не так. Для того чтобы Statement-based репликация, которая реплицирует запросы, работала корректно, есть специальный флажок. В InnoDB, заметьте, т.е. у нас архитектура разделяет репликацию выше, а storage engine ниже. Но storage engine, для того, чтобы репликация работала, должен, грубо говоря, замедлять insert'ы в таблицу.
Другая проблема состоит в том, что мастер выполняет запросы параллельно, т.е. одновременно, а слэйв их может применять последовательно. Возникает вопрос – а почему слэйв не может применять их параллельно? На самом деле, с этим все непросто. Есть теорема о сериализации транзакций, которая рассказывает, когда мы можем выполнять запросы параллельно, а когда последовательно. Это отдельная сложная тема, разберитесь в ней, если вам интересно и нужно, например, почитав по ссылке – http://plumqqz.livejournal.com/387380.html.
В PostgreSQL репликация упирается, в основном, в диск. Диск не параллелится, и нас как-то не волнует один поток, все равно, мы сидим, в основном, в диске. CPU мы почти не потребляем.
В MySQL репликация упирается в процессор. Это прекрасная картинка – большой, мощный сервер, 12 ядер. Работает одно ядро, заодно занято репликацией. Из-за этого реплика задыхается. Это очень грустно.
Для того чтобы выполнять запросы параллельно существует группировка запросов. В InnoDB есть специальная опция, которая управляет тем, как именно мы группируем транзакции, как именно мы их пишем на диск. Проблема в том, что мы можем их сгруппировать на уровне InnoDB, а уровнем выше – на уровне репликации – этой функциональности не было. В 2010 г. Кристиан Нельсен из MariaDB реализовал такую фичу, которая называется Group Binary Log Commit – мы поговорим о ней чуть позже. Получается, мы журнал (а это достаточно сложная структура данных) повторяем на двух уровнях – Storage Engine и репликация, и нам нужно таскать фичи из одного уровня на другой. Это сложный механизм. Более того, нам нужно одновременно консистентно писать сразу в два журнала – two-phase-commit. Это еще хуже.
На следующей картинке мы видим два графика:

Синий график демонстрирует то, как масштабируется InnoDB, когда мы ему добавляем треды. Накидываем треды – число транзакций, которые он обрабатывает, возрастает.
Красная линия показывает ситуацию, когда включена репликация. Мы включаем репликацию и теряем масштабируемость. Потому что лог в Binary Log пишется синхронно, и Group Binary Log Commit это решает.
Грустно, что приходится так делать из-за разделения – Storage Engine внизу, репликация наверху. С этим все плохо. В MySQL 5.6 и 5.7 эта проблема решена – есть Group Binary Log Commit, и мастер теперь не отстает. Теперь это пытаются использовать для параллелизма репликации, чтобы на слэйве запросы из одной группы запустить параллельно. Тут я написал, что из этого нужно крутить:

С октября 2013 г., поскольку у нас данных много, репликация постоянно отстает, все расстраиваются, я пытался этот параллелизм увидеть. Возможно, я что-то еще не понял, что-то не то настроил, было много попыток, и результаты выглядят примерно так:
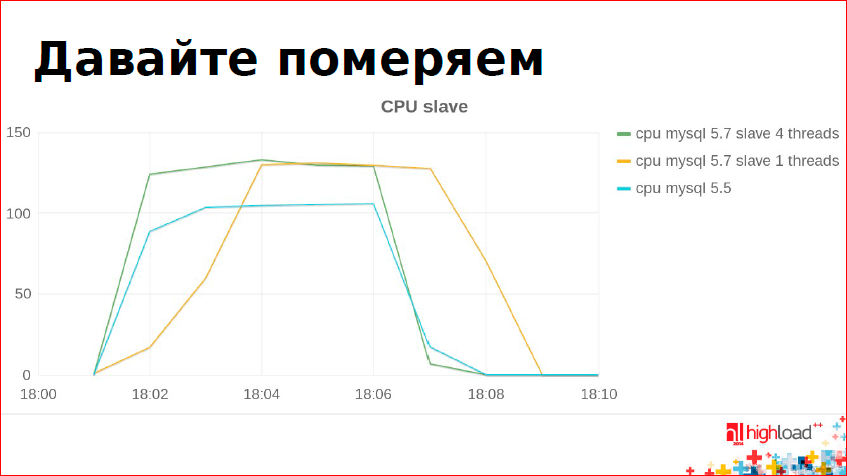
Голубой график – это MySQL 5.5.
По оси Y – потребление процессора на слэйве. По оси Х – время.
На данном графике мы можем видеть, когда репликация начала догоняться с мастера и когда она закончила. Получается интересная картинка – что 5.5 в один поток работает примерно так же, как параллельная репликация в 5.7 в четыре потока. Т.е. процессора потребляется больше (зеленая линия), а работает по времени так же. Там трудится четыре треда, четыре потока. Если же сделать один поток в 5.7, он будет работать хуже. Это какая-то регрессия, в 5.7.5 ее хотели починить, но я проверил – проблема пока актуальна. На моих бенчмарках это так, это так на тестах с продакшенами, это данность. Я надеюсь, что это исправят.
В чем еще проблема – для того, чтобы мигрировать, не останавливая сервис, у нас в один момент времени на мастере будет запущен MySQL 5.5, а на слэйве – 5.7. В 5.5 нет Group Binary Log Commit, значит 5.7 сможет работать только в один поток. Это означает, что наша реплика на 5.7 начнет отставать и не догонится никогда. Пока есть регрессия с однопоточной 5.7 репликацией, мы смигрировать не сможем, мы сидим на 5.5, у нас нет выбора.
Теперь самая интересная часть – я просуммирую все, что рассказал, и что осталось за рамками доклада из-за ограничения во времени (у меня материала часа на три).
Во-первых, архитектурно есть три типа журналов, есть репликация на физическом уровне и на логическом уровне. Физический уровень – это страницы. PostgreSQL силен тем, что через его журнал идет, вообще, все – обновление таблиц, создание триггеров, создание хранимых процедур, – и поэтому с ним проблем возникает меньше. У MySQL, в зависимости от того, какой тип репликации у нас включен, мы получаем либо логическую репликацию, либо репликацию на уровне запросов.
В принципе, у любого из этих журналов есть свои плюсы и минусы, потому выбирать нужно осмотрительно.
Чем они сильны/слабы:

Стоит * в первой строке. Объясню – слэйву, все равно, нужно скопировать журнал с мастера, плюс слэйв может попросить мастера по каким-то причинам не удалять журнал.
В MySQL есть два серьезных пенальти, треда, как на мастера влияет репликация:
- опция в InnoDB для того, чтобы работала Statement-based репликация;
- без Group Binary Log Commit мы не получаем масштабирования.
Row-based репликация в MySQL работает лучше, но и тут есть свои проблемы.
Далее, слэйв. PostgreSQL упирается в диск, MySQL – в процессор.
С точки зрения потребления дисков тут интереснее. Например, в Row-based репликации в MySQL (в PostgreSQL будет примерно так же) получаются десятки терабайт логов в день, у нас просто нет такого количества дисков, чтобы это все хранить, поэтому мы сидим на Statement-based. Это тоже бывает важно – если реплика отстала, нам нужно где-то хранить журнал. В этом смысле PostgreSQL, по сравнению с Statement-based репликацией выглядит хуже.
С процессором слэйва нам важно построить хорошие индексы на слэйве для того, чтобы строчки легко находились, чтобы запросы работали хорошо. Это достаточно странная метрика. Мы оптимизируем слэйв с точки зрения эффективности работы репликации, т.е. мы хотим слэйв для того, чтобы строить отчеты, а нам приходится еще настраивать, чтобы слэйв не только отчеты строил, но и догоняться успевал. MySQL parallel slave 5.6/5.7 – мы очень ждем, когда он станет работать хорошо, пока он не оправдывает надежд.
Другая важная тема – консистентность данных.
PostgreSQL реплика – это бинарная копия мастера. Т.е. буквально – если вы остановите запись на мастер, дадите репликации доехать до конца на слэйве, остановите процесс на мастере и слэйве и сделаете бинарное сравнение PostgreSQL-мастера и PostgreSQL-слэйва, вы увидите, что они одинаковы. В MySQL это не так. Row-based репликация, которая работает с логическим представлением, с кортежами – в ней все update'ы, insert'ы и delete'ы работают корректно, с ними все хорошо.
В Statement-based репликации это уже не так. Если вы неправильно настроите мастера и запустите определенные хитрые запросы, вы можете получить разные результаты. С запросами, которые работают со схемой базы – создание таблиц, построение индексов и пр., – все еще грустнее, они всегда идут как сырые запросы... Нужно постоянно помнить об особенностях работы Statement-based репликации.
С mixed-based история еще интереснее – она либо такая, либо другая, все надо смотреть.
Гибкость. MySQL на данный момент действительно лучше тем, что репликация в нем более гибкая. Вы можете построить разные индексы на мастере и слэйве, можете поменять даже схему данных – иногда это бывает нужно, а в PostgreSQL сейчас такой возможности нет. Кроме того, в MySQL есть libslave – это очень мощная штука, мы ее очень любим. Наши демоны прикидываются MySQL-слэйвами и они постоянно в режиме реального времени получают обновления. У нас задержка составляет примерно 5 сек. – пользователь увидел баннер или кликнул по нему, демон это все заагрегировал, записал в базу, спустя 5 сек. демон, который раздает баннеры, про это узнал. В PostgreSQL такого средства нет.
Однако PostgreSQL планирует следующее. Во-первых, есть такая штука как Logical Log Streaming Replication – это способ трансформировать Write-Ahead Log. Например, мы не хотим реплицировать все таблицы из данной базы, а хотим реплицировать только часть. Logical Log Streaming Replication позволяет мастеру объяснить, что из таблиц будет уезжать на слэйв.
Также есть еще Logical Decoding – способ визуализировать то, что находится в PostgreSQL Write-Ahead Log. На самом деле, если мы можем напечатать в каком-то виде то, что у нас происходит на слэйве, точнее, что нам пришло через Write-Ahead Log, это значит, что мы можем программно реализовать все то, что делает libslave. Получили insert, update, delete, у нас “дернулся” нужный callback, мы узнали про изменения. Это и есть Logical Decoding.
Вывод из этого достаточно интересный – лучше всего сделать нормальный журнал. У PostgreSQL журнал нормальный, туда попадают все обновления данных, все изменения схемы, вообще все. Это дает кучу плюшек, например, корректно работающую репликацию, репликацию, которая упирается только в диск, а не в процессор. Имея такой журнал, уже можно дописать некоторый набор патчей в сам движок, для мастера, для слэйва, который позволяет повысить гибкость, т.е. фильтровать таблицы, иметь другие индексы.
А у MySQL в силу исторических причин получился журнал плохой, т.е. MySQL – заложник своего исторического развития. Чтобы решить возникшие в MySQL проблемы с производительностью, корректностью, нужно переписать всю архитектуру, которая связана со Storage Engine, а это нереально.
Пройдет совсем немного времени, я думаю, и PostgreSQL по фичам догонит MySQL.
И, напоследок. Даже если вы много чего не поняли из всего доклада или вам нужно разбираться, но в любом случае запомните два самых главных вывода:
- Репликация не является резервной копией (бэкапом).
- Таблица – это не двумерный массив, а гомогенное мультимножество кортежей. Так корректно с точки зрения computer science.
Этот доклад мне помогали делать много людей:
