Анатомия веб-сервиса
Андрей Смирнов

Я попытаюсь залезть в "потроха" и "кишки" бэкенда веб-сервиса и расскажу, как это внутреннее устройство влияет на эффективность сервиса, а также на продукт, его характеристики, и как бы мы могли этим воспользоваться, чтобы наше приложение выдерживало большую нагрузку или работало бы быстрее.
Какую часть я называю веб-сервисом, бэкендом, application-сервером? В классической архитектуре это то, что стоит за http rеverse proxy или load-балансировщиком, а с другой стороны у него находятся БД, memcashed и др. Вот только об этом бэкенде и будет идти речь.
Чем занят бэкенд?
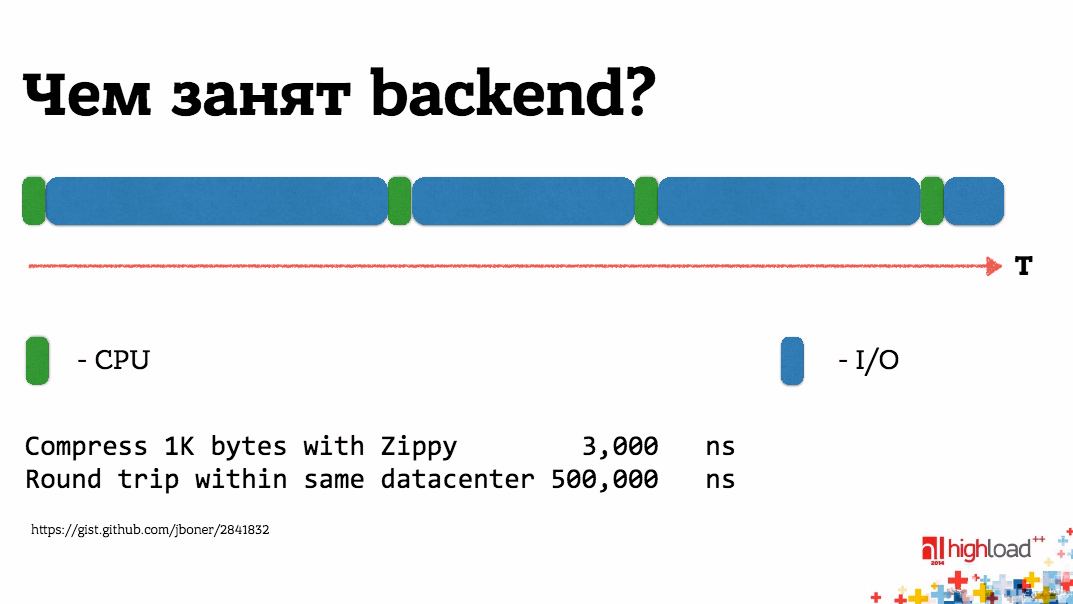
Если посмотреть на соотношение скорости процессора и возможности сетевых соединений, то отличия – на пару порядков. Например, на этом слайде сжатие 1 Кб данных занимает 3 мкс, в то время как round trip в одну сторону даже внутри одного дата-центра – это уже 0,5 мс. Любое сетевое взаимодействие, которое нужно бэкенду (например, отправка запроса в БД), потребует, как минимум 2х round trip-ов и по сравнению с тем процессорным временем, которое он тратит на обработку данных, – это совершенно незначительно. Большую часть времени обработки запроса бэкенд ничего не делает, ждет. Почему он ждет? Существенную часть относительно сложной работы берет на себя rеverse proxy или load-балансировщик, который стоит перед ним. Это и буферизация запросов и ответов, и валидация http, "борьба" с медленными клиентами, шифрование https. До бэкенда доходит чисто http-валидный запрос, уже буферизованный, буквально в паре tcp-пакетов. Ответ также proxy готов буферизовать за бэкенд, ему нет необходимости этим заниматься.
Бэкенд – один из самых больших бездельников в веб-архитектуре. У него есть всего 2 задачи:
- сетевой ввод-вывод – это общение с одной стороны с proxy – прием http-запроса и ответ на него, а с другой стороны общение со всевозможными сервисами, которые хранят данные – это могут быть БД, очереди, memcaсhed и т.п.
- склеивание строк – стерилизовать данные в JSON, сформировать шаблон на основе html, посчитать sh1 или md5? выполнить сжатие данных.
А что такое бизнес-логика в бэкенде? Это проверки наподобие "если значение переменных больше 3-х, делай это", "если пользователь авторизован, покажи одно, если не авторизован – покажи другое". Бывают, конечно, отдельные задачи, например, по изменению размера картинки, переконвертации видео, но чаще всего такие задачи решаются вне бэкенда с использованием очередей, воркеров и т.д.
Параллелизм запросов
Если мы говорим о бэкенде, а его производительность во многом будет определять производительность в целом нашего продукта, то у нас может быть 2 цели по оптимизации:
- заставить его "переваривать" все большее количество запросов в секунду, т.е. увеличить его производительность,
- вторая цель – продуктовая – это уменьшение времени отклика, т.е., чтобы каждый запрос выполнялся намного быстрее, для пользователя результат появлялся быстрее и т.п.
Если мы вспомним, что бэкенд – бездельник и большую часть времени он ждет, то с точки зрения, чтобы бэкенд мог выдержать как можно большую нагрузку, совершенно логично, что мы должны в рамках одного ядра процессора обрабатывать не один запрос, а несколько, т.к. процессорное время тратится совсем небольшое, между ними расположены интервалы ожидания, мы можем обработку нескольких запросов выполнять на одном ядре, переключаясь между ними по мере того, как обработка блокируется на ожидание какого-то сетевого ввода-вывода.
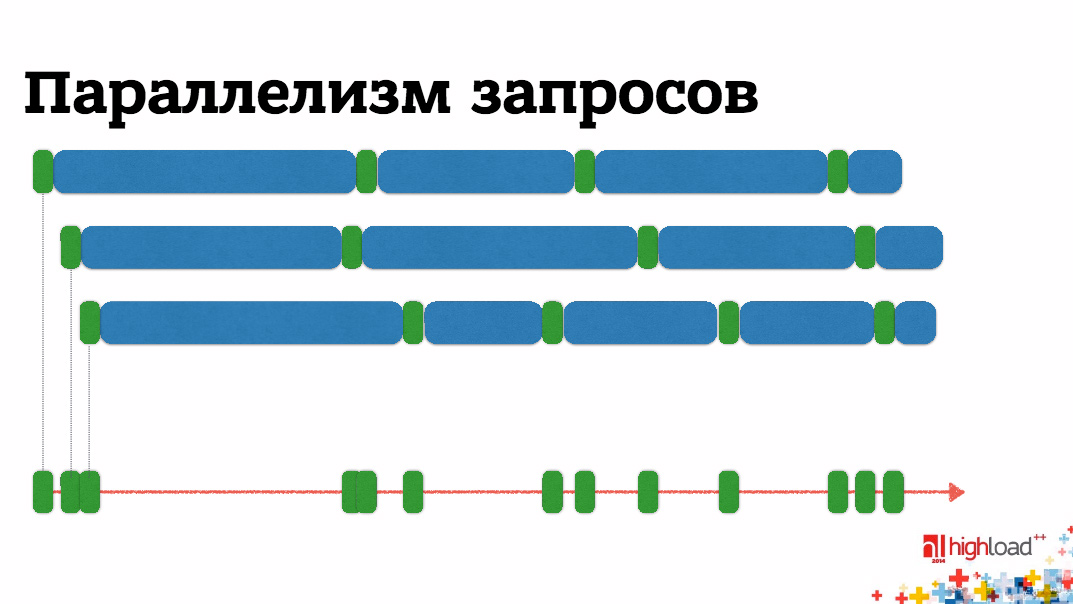
С другой стороны, если мы хотим оптимизировать время отклика, то что влияет на время отклика? Это то, чем занимается бэкенд – склеиванием строк и сетевым вводом-выводом. Сетевой ввод-вывод занимает на порядок больше времени, поэтому нужно оптимизировать его. Для этого можно все время ожидания распараллелить – отправить все запросы одновременно, дождаться всех ответов, сформировать блок для клиента и отправить обратно. Тем самым значительно сокращается время отклика, если, конечно, бизнес-логика нам позволяет какие-то запросы отправлять одновременно.
Сетевой ввод-вывод
Начнем с сетевого ввода-вывода. Существует 3 варианта организации ввода-вывода: блокирующийся, неблокирующийся и асинхронный. Последний с сетевыми не работает, остается 2 варианта – блокирующийся, неблокирующийся.
Рассмотрим их на примере API-сокетов, BSD-сокетов, которые есть в UNIX-e, в Windows все то же самое – будут по-другому называться вызовы, но логика та же самая. Как выглядит API низкоуровневый для работы с tcp-сокетом? Это некий набор вызовов. Если мы говорим о сервере, то он должен создать сокет, должен его забиндить к некоему адресу, на котором он слушает, сделать listen и сообщить об ожидании входящих соединений. Далее есть вызов accept, который отдает нам новый сокет, новое соединение с конкретным клиентом, в рамках этого соединения мы можем писать и читать данные из этого сокета, т.е. получать запрос, отправлять ответ и, в конце концов, мы этот сокет закрываем.
Если у нас ввод-вывод блокирующийся, то большинство важных операций заблокируется до тех пор, пока не появятся данные, новые соединения, или до тех пор, пока не будет свободен для записи системный сетевой буфер. Наш поток исполнения будет ждать окончания выполнения какой-то операции. Из этого следует простейший вывод: в рамках одного потока мы не можем обслуживать более одного соединения.
С другой стороны, этот вариант самый простой с точки зрения разработки.
Но существует второй вариант – неблокирующийся ввод-вывод. На поверхности отличия элементарны – вместо того, чтобы заблокироваться, любая операция завершается немедленно. Если данные не готовы, возвращается специальный код ошибки, по которому понятно, что следует попробовать вызов позднее. При таком варианте мы можем из одного потока выполнять несколько сетевых операций одновременно. Но, т.к. неизвестно, готов ли сокет к вводу-выводу, пришлось бы обращаться к каждому сокету по очереди с соответствующими запросами и, по сути, крутиться в вечном цикле, что неэффективно. Необходим механизм опроса готовности, в который мы могли бы запустить все сокеты, а он бы сообщал нам, которые из них готовы к вводу-выводу. С готовыми мы провели бы все нужные операции, после чего могли бы заблокироваться, ожидая сокетов, снова готовых к вводу-выводу. Таких механизмов опроса готовности несколько, они отличаются производительностью, деталями, но обычно он находится "под капотом" и нам не виден.
Как сделать неблокирующийся ввод-вывод? Мы соединяем опрос готовности и операции ввода-вывода с теми и только теми сокетами, которые сегодня готовы. Опрос готовности у нас блокируется до тех пор, пока не появятся какие-то данные хотя бы в одном сокете.
Второй вопрос по поводу того, что расположено "под капотом" – это вопрос многозадачности. Как мы можем обеспечить одновременную обработку нескольких запросов (мы договорились, что нам это необходимо)?
Есть 3 базовых варианта:
Отдельные процессы
Самый простой и исторически первый – это на обработку каждого запроса мы запускаем отдельный процесс. Это хорошо, потому что мы можем использовать блокирующийся ввод-вывод. Если процесс вдруг упадет, это повлияет только на тот запрос, который он обрабатывал, но ни на какие другие.
Из минусов – достаточно сложная коммуникация. Между процессами формально почти нет ничего общего, и любой механизм нетривиальной коммуникации, который мы хотим организовать, требует дополнительных усилий по синхронизации доступа и т.д. Как эта схема выглядит – вариантов несколько, но обычно запускается 1й процесс, он делает, например, listen, далее порождает какой-то набор процессов у воркеров, каждый из которых делает accept на том же самом сокете и ожидает входящих соединений.
Как только появляется входящее соединение, один из процессов разблокируется, получает это соединение, обрабатывает его от начала до конца, закрывает сокет и снова готов выполнять следующий запрос. Возможны вариации – процесс может порождаться на каждое входящее соединение или они все запущены заранее и т.п. Это может влиять на характеристики производительности, но это не так принципиально для нас.
Примеры таких систем: FastCGI для тех, кто чаще всего запускает PHP, Phusion Passenger для тех, кто пишет на "рельсах", из БД – это PostgresSQL. На каждое соединение выделяется отдельный процесс.
Нити операционной системы
В рамках одного процесса мы порождаем несколько потоков, также может быть использован блокирующийся ввод-вывод, потому что будет заблокирован только 1 поток. О нитях знает ОС, она умеет разбрасывать их между процессорами. Нити более легковесны, чем процессы. По сути это означает, что мы можем больше нитей породить на той же самой системе. Мы вряд ли сможем запустить 10 тыс. процессов, а вот 10 тыс. нитей может быть. Не факт, что это будет эффективно с 10 тысячами, но, тем не менее, они несколько более легковесны.
С другой стороны, отсутствует изоляция, т.е. если происходит какой-то краш, он закрашит весь процесс целиком, а не отдельную нить. И самая большая сложность – если мы, все-таки, имеем какие-то общие данные в процессе, который обрабатывается в бэкенде, то между нитями отсутствует изоляция. Общая память, а это означает, что к ней нужно будет синхронизировать доступ. И вопрос синхронизации доступа к общей памяти – это в самом простом случае, например, может быть соединение с БД, или пул соединений с БД, который общий для всех потоков внутри бэкенда, который обрабатывает входящие соединения. Синхронизацию доступа сложно провести корректно.
Есть 2 класса сложности:
- если потенциальная проблема – это deadlock-и в процессе синхронизации, когда у нас какая-то часть блокируется намертво и невозможно продолжить исполнение;
-
недостаточная синхронизация, когда у нас происходит конкурентный доступ к общим данным и, грубо говоря, 2 потока эти данные изменяют одновременно и портят их. Такие программы отлаживать сложнее, не все баги проявляются сразу. Например, знаменитый GIL – Global Interpreter Lock – это один из простейших способов сделать многопоточное приложение. Мы говорим, что все структуры данных, вся наша память защищена всего одной блокировкой на весь процесс. Казалось бы, это означает, что многопоточное исполнение невозможно, ведь может выполняться только 1 поток, есть только одна блокировка, и кто-то ее захватил, все остальные не могут сработать. Да, это так, но вспомним, что мы большую часть времени не работаем на процессы, а ожидаем сетевого ввода-вывода, поэтому в момент, когда происходит обращение к какой-то блокирующейся операции ввода-вывода, GIL опускается, поток сбрасывает и по сути происходит переключение на другой поток, который готов к выполнению. Поэтому с точки зрения бэкенда использование GIL может быть не так страшно.
Использование GIL страшно, когда вы пытаетесь в несколько потоков перемножить матрицу – это бессмысленно, потому что будет выполняться только один поток одновременно.
Примеры. Из БД это MySQL, где на обработку запроса выделяется отдельный поток. Еще Varnish HTTP Cache, в котором воркерами являются нити, обрабатывающие отдельные запросы.
Кооперативная многозадачность
Третий вариант самый сложный. Здесь мы говорим о том, что ОС, конечно, классная, у нее есть там sсheduler-ы, она умеет обрабатывать процессы, потоки, организовать между ними приключения, обрабатывать блокировку и т.д., но она все-таки знает хуже о том, как устроено приложение, чем знаем мы. Мы знаем, что у нас есть короткие моменты, когда совершаются какие-то операции на процессоре, а большую часть времени мы ожидаем сетевого ввода-вывода, и мы лучше знаем, когда переключаться между обработкой отдельных запросов.
С точки зрения ОС кооперативная многозадачность – это просто один поток выполнения, но внутри него само приложение переключается между обработкой отдельных запросов. Как только пришли какие-то данные, я их прочитал, разобрал http-запрос, подумал, что мне надо сделать, отправил запрос memcached, а это блокирующаяся операция, я буду ждать, пока придет ответ от memcached, и вместо того, чтобы ждать, я начинаю обрабатывать другой запрос.
Сложность написания таких программ заключается в том, что вот этот процесс переключения, поддержания контекста, как такового, что я сейчас делаю с каждым конкретным запросом, ложится на разработчиков. С другой стороны, мы выигрываем в эффективности, потому что нет лишних переключений, нет проблем переключения, скажем, контекста процессора при переключении между нитями и процессами.
Есть два способа реализовать кооперативную многозадачность.
Один – это способ явный, его отличает большое количество callback-ов. Так как у нас все блокирующие операции приводят к тому, что действие произойдет когда-нибудь и когда-нибудь управление должно вернуться, когда будет результат, нам приходится постоянно регистрировать callback – когда запрос выполнится, сделает то, если он будет не успешно, сделает это. Callback-и – это явный вариант, а многие боятся этого, потому что это может быть действительно сложно на практике.
Второй вариант – неявный, когда мы пишем программу так, что, вроде бы, никакой кооперативной многозадачности нет. Мы делаем блокирующуюся операцию, как мы ее и делали, и ожидаем результата прямо здесь. На самом деле, существует где-то "черная магия под капотом" – уже нашел framework языка программирования, runtime, который в этот момент блокирующуюся операцию превращают в неблокирующуюся и передает управление некоему другому потоку исполнения, но не в смысле нити ОС, а логическому потоку исполнения, который есть внутри. Такой вариант называется грин треды (green threads).
Внутри кооперативной многозадачности всегда есть такое центральное звено, которое отвечает за всю обработку ввода-вывода. Оно называется реактор. Это некий паттерн разработки. Интерфейс реактора выглядит следующим образом: он говорит: "Дай мне кучу своих сокетов и свои callback-и, и когда этот сокет будет готов к вводу-выводу, я тебя вызову".
Второй сервис, который предоставляет реактор, это таймер – " Вызови менять через столько-то миллисекунд, вот мой callback, который надо вызвать". Эта штука будет встречаться везде, где будет кооперативная многозадачность в явном виде или в неявном.
Внутри обычно реактор устроен довольно просто. У него есть отсортированный по времени срабатывания список таймеров. Соответственно, он берет список сокетов, который ему дали, отправляет их в механизм опроса готовности. А у механизма опроса готовности всегда есть еще один параметр – он говорит, сколько времени можно заблокироваться, если нет никакой сетевой активности. В качестве времени блокировки он указывает время срабатывания ближайшего таймера. Соответственно, либо будет какая-то сетевая активность, какой-то из сокетов будет готов к вводу-выводу, либо мы дождемся срабатывания ближайшего таймера, разблокируемся и передадим управление в тот или иной callback, по сути в логический поток выполнения.
Вот как выглядит кооперативная многозадачность с явными callback-ами.

Пример на node.js, где мы выполняем какую-то блокирующуюся операцию – на самом деле net.connect. "Под капотом" она неблокирующаяся, все хорошо и регистрируем callback-и. Если все будет успешно, делай то, а если будет неуспешно, делай это.
Проблема callback-ов в том, что в конечном итоге они превращаются в "лапшу", но мы к этому вопросу еще вернемся.
Второй пример.

Здесь тоже кооперативная многозадачность, хотя никаких следов ее в программе не видно.
Здесь мы видим, что запускаются несколько потоков, которые одновременно параллельно? Хотя, на самом деле, кооперативная многозадачность друг за другом выполняет блокирующуюся операцию – они скачивают некоторые url-ы. Это функция urlopen на самом деле блокирующаяся, но gevent делает некую "черную магию" и все эти блокирующиеся сетевые операции становятся неблокирующимися, кооперативная многозадачность, переключение контекстов – этого всего мы не видим, пишем, вроде бы, обычный совершенно последовательный код, но внутри все работает достаточно эффективно.
Примеры систем с кооперативной многозадачностью: Redis, memcached (он не совсем чисто кооперативная многозадачность, хотя многие думают, что это так). В чем их особенность, почему они себе могут это позволить сделать? Это хранилища данных, но все операции, все данные находятся в памяти, поэтому они, как и бэкенд – их процессорное время, которое они тратят на обработку одного запроса крайне маленькое. Т.е. в простейшем случае, чтобы обработать get запрос, надо найти ключ к внутренним хэшам, найти блок данных и вернуть его – просто записать его в сокет в качестве ответа. Поэтому кооперативная многозадачность для них эффективна.
Если бы Redis или memcached использовали диск для ввода-вывода, все было бы, но это не работало бы просто, потому что, если наш единственный поток заблокируется на вводе-выводе, это означает, что мы перестанем обслуживать запросы всех клиентов, т.к. поток выполнения один, нигде заблокироваться мы себе позволить не можем, все операции должны выполняться быстро.
Если кто-то помнит Redis 3-4 года, может, чуть больше лет назад, там была попытка у автора сделать некую виртуальную память, возможность хранить часть данных на диске. Это называлось virtual memory. Он попробовал это сделать, но быстро понял, что это не работает, потому что как только начинается дисковый ввод-вывод, время отклика Redis-а сразу уходит на несколько порядков вниз, и это означает, что смысл в нем теряется.
Но на самом деле ни один из этих трех вариантов не является идеальным. Лучше всего работает комбинированный вариант, потому что выигрывает обычно кооперативная многозадачность, особенно в той ситуации, если ваши соединения долго висят. Например, веб-сокет – соединение долгоживущее, может жить час. Если вы на обработку одного веб-сокета выделяете один процесс или одну нить, вы существенно ограничиваете то, сколько всего соединений вы можете на одном бэкенде держать одновременно. А так как соединение живет долго, держать много одновременных соединений важно, в то время, как работы по каждому соединению будет немного.
Недостаток кооперативной многозадачности в том, что такая программа может использовать только одно ядро процессора. Можно, конечно, запустить несколько экземпляров бэкендов на одной машине, это не всегда удобно и имеет свои недостатки, поэтому хорошо бы сделать так, чтоб мы запустили несколько процессов или несколько нитей и внутри каждого процесса или нити использовали кооперативную многозадачность. Такая комбинация позволяет с одной стороны использовать все доступные ядра процессоров в нашей системе, а с другой стороны мы внутри каждого ядра работаем эффективно, не выделяя больших ресурсов на обработку каждого отдельного соединения.
2 классических примера – это nginx, в котором вы настраиваете количество воркеров, имеет смысл увеличивать количество воркеров до числа ядер в вашей системе, это отдельные процессы. Внутри воркера каждый воркер использует неблокирующийся ввод-вывод и кооперативную многозадачность, чтобы обслужить большое количество одновременных соединений. Воркеры нужны только для того, чтобы распараллелиться между отдельными процессорами.
Второй пример – это memcached, который я уже приводил. У него есть опция запуститься на несколько потоков, несколько нитей ОС. Тогда у нас запускается несколько нитей, внутри каждой из них крутится реактор, обеспечивающий неблокирующийся ввод-вывод и кооперативную многозадачность, а несколько потоков позволяют использовать эффективно несколько ядер процессора. Ну, а общей памятью memcached является ведь кэш, который собственно он и обслуживает. Все эти потоки читают и пишут из того же самого кэша.
Еще один вопрос. Мы все время сейчас говорили о том, как бэкенд обрабатывает, ну большую часть времени, по крайней мере, входящие http-соединения на те запросы, которые поступают на вход. Но бэкенд делает и исходящие запросы, и таких запросов может быть множество – в сервис-ориентированной архитектуре к другим сервисам по http, к БД, к Redis-у, к memcached, очередям... И это тот самый сетевой ввод-вывод, который будет сильно влиять на характеристики бэкенда, как мы об этом договорились изначально.
Посмотрим, как может быть устроен этот драйвер (условно!) базы данных, и как его сделать эффективнее. Во-первых, такая картинка для начала архитектурная:
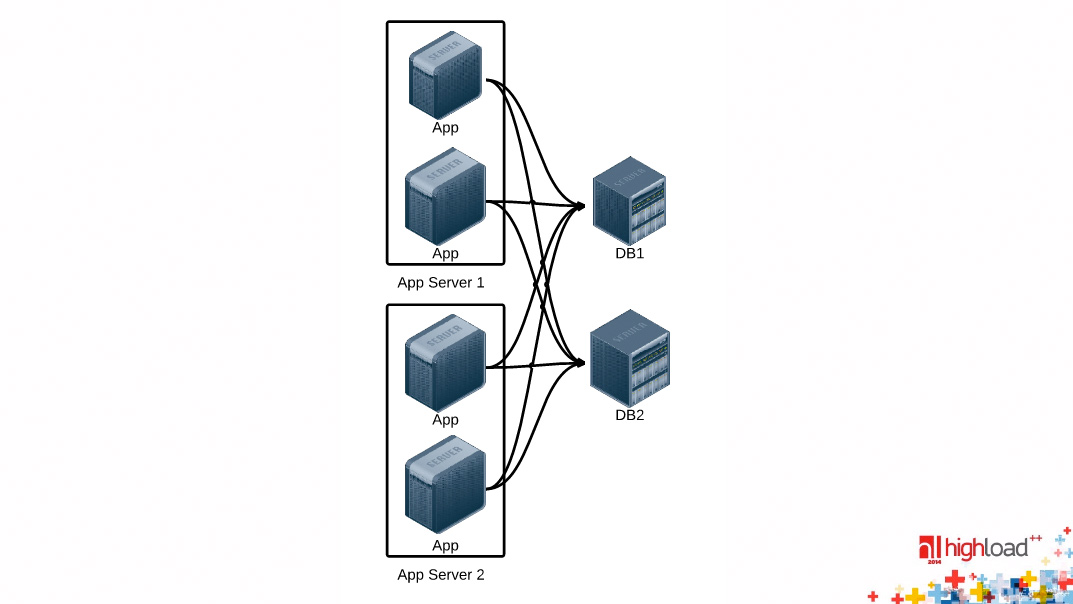
Предполагаем, что у нас есть несколько серверов, на каждом из них запущен один или несколько экземпляров нашего бэкенда, и существуют какие-то хранилища данных, которые здесь условно обозначены DB, к которым идут соединения от наших application-серверов. Первый вопрос, если вы используете соединения на один запрос, т.е. на 1 входящий http-запрос вы открываете соединения с вашей БД с чем угодно и т.д., вы теряете огромное количество времени.
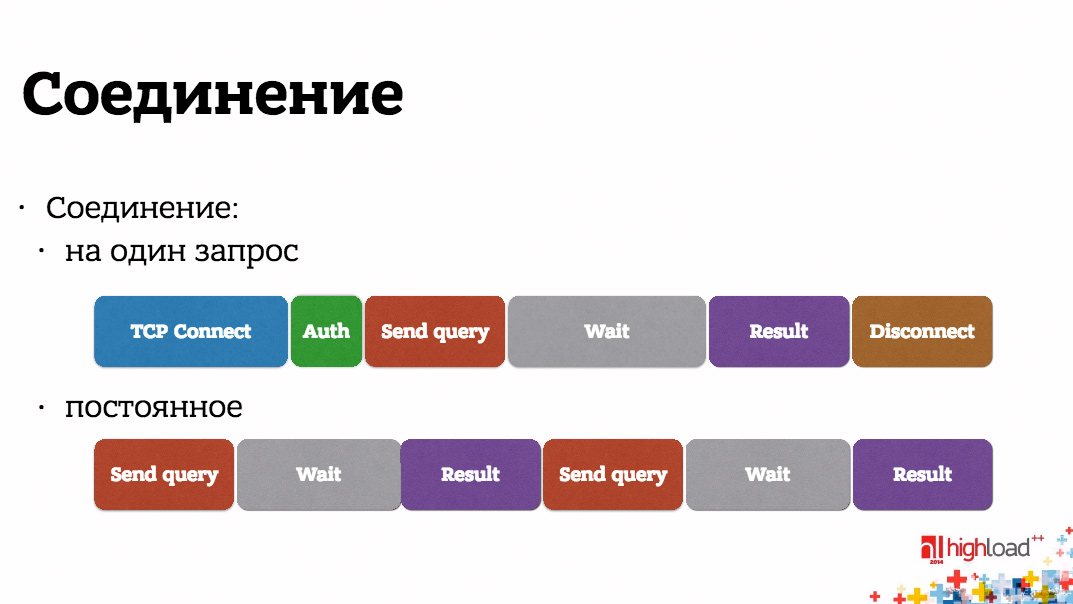
Здесь нарисованы квадратики, соответствующим каким-то отдельным фазам. Они нарисованы совершенно не в масштабе, любая сетевая деятельность занимает больше времени, чем любая деятельность на процессоре. Т.е. если мы делаем соединения на один запрос, мы теряем огромное количество времени вначале на установление соединения, в конце на его закрытие, если необходима еще какая-то авторизация доступа, в БД, к примеру, потеряем еще больше времени. Мы за то же самое время астрономическое, если бы у нас соединение было постоянным, могли бы отправить и получить ответ на два запроса, чем то, что мы сделали с соединением, которое устанавливается каждый раз. Держать постоянное соединение эффективнее на порядок.
Второй вопрос – а почему надо ждать ответа на запрос, прежде чем отправить следующий? Если между запросами нет логической связи и, по сути, поток запросов состоит из отдельных, никак не связанных между собой запросов, почему бы нам не отправлять их сразу, не дожидаясь ответа, а потом ждать всех ответов?
Мы, конечно, можем. Это называется pipelining.
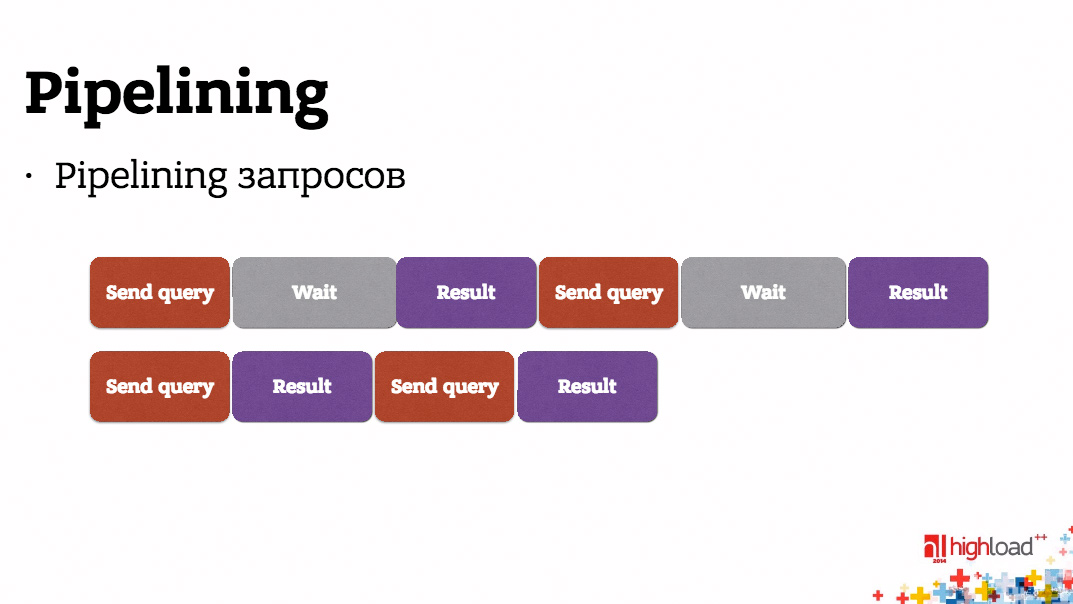
Так, например, PostgreSQL умеет делать pipelining.
Вы можете существенно сократить время отклика от БД, а значит уменьшить время отклика бэкенда в целом.
Еще одна вещь. Можно между вашим бэкендом и БД поставить proxy.
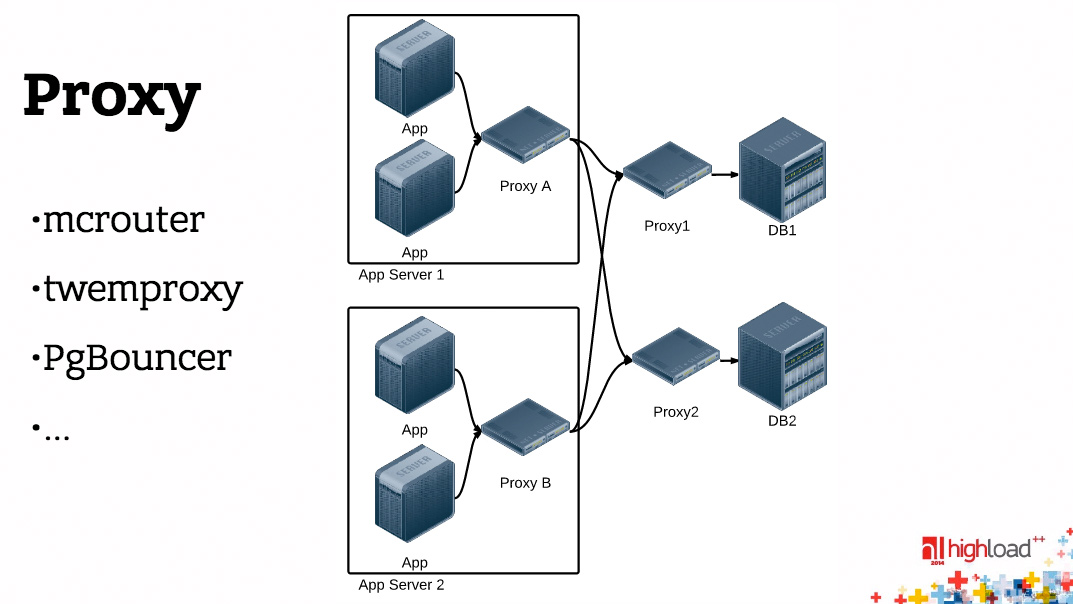
Здесь нарисована такая немножко утрированная ситуация, здесь две штуки proxy на пути – одна расположена на хосте с application-сервером, другая – перед БД. Это не обязательно так, я просто попытался на одной картинке нарисовать два случая.
Зачем нужен, вообще говоря, proxy? Если у вас хороший драйвер базы данных, то есть вы делаете все эффективно, у вас постоянное соединение, pipelining и т.д., то proxy, вообще говоря, для производительности не нужен, более того, с точки зрения производительности он вреден, потому что он ухудшает время отклика.
С другой стороны, если у вас плохой драйвер базы данных, то proxy, который умнее, и, например, делает pipelining и постоянное соединение, может уменьшить время отклика.
С третьей стороны, proxy может использоваться еще для кучи других вещей, например, с помощью proxy можно сделать единую точку входа в БД, в memcached, можно сделать шардинг, переконфигурацию, переключение без участия приложений. Приложение работает с proxy-сервером, оно не знает, что там за ним, а proxy можно перенастраивать произвольным образом.
Но существуют proxy-сервера, которые нужны. Вот, например, если вы используете PostgreSQL, вы везде прочитаете, что необходимо перед ним запустить PgBouncer, и жизнь будет ваша гораздо лучше. Почему? Причина простая – как мы уже говорили, PostgreSQL на обслуживание каждого соединения запускает отдельный процесс, форкается, это достаточно дорогостоящая операция. Много процессов, много инстансов на каждое соединение держать тоже невыгодно и неудобно, и proxy, расположенный перед PostgreSQL, позволяет это дело оптимизировать. Он на себя принимает сколько угодно соединений, сколько бы ни было application-серверов, и их отображает на меньшее количество соединений к PostgreSQL, примерно на 100.
Если у вас сервис-ориентированная архитектура, то все проблемы, о которых мы говорили, они умножаются на некий коэффициент К, у вас становится больше сетевых хопов, вы должны сделать больше запросов, для того чтобы ответить на один и тот же запрос клиента, и чем эффективнее вы сможете это дело реализовать, тем эффективнее будет ваш бэкенд в конечном итоге.
Реальный мир
Мы подбираемся к той части доклада, которой я боюсь, поэтому я одеваю каску, чтобы в меня не полетели гнилые помидоры или какие-то еще нехорошие фрукты.

Я буду говорить о ваших любимых языках программирования, и как в них устроена многозадачность, сетевой ввод-вывод, и что вы можете от них добиться.
Итак, если вы пишете на JavaScript. JavaScript однопоточный, кроме веб-воркеров, но они являются изолированной сущностью. Он однопоточный с точки зрения модели вычислений, в нем асинхронный ввод-вывод, не блокирующийся, в нем есть некий реактор, в котором вы регистрируете таймеры с callback-ами и т.д. Что бы вы ни делали, если вы просто будете писать код на JavaScript, в конечном итоге у вас получится "лапша" из callback-ов. К счастью, в последнее время JavaScript-мир узнал о такой штуке как Deferred или Promise, узнал, что это круто, и она активно внедряется. Это некая абстракциия, она может быть полезна в любом языке программирования, где у вас кооперативная многозадачность в явном виде с callback-ами, которая позволяет развязать эту "лапшу" и сделать ее более стройной. Deferred или Promise – это концепция отложенного результата, т.е. это обещание вернуть результат в пустой блок, когда результат придет. Я могу на этом пустом блоке регистрировать обработчики ошибочных или успешных ситуаций, выстраивать их в цепочки, связывать одни Promise-ы с другими и, по сути, моделировать те самые паттерны программирования обычного синхронного и существенно упрощать себе жизнь.
PHP . Он формально поддерживает многопоточный режим выполнения, но на практике это не работает в силу тех или иных причин исторических. В большинстве случаев, если вы запускаете PHP, его существенным недостатком является то, что на каждый входящий запрос мы очищаем все и начинаем все сначала. Поэтому есть всякие PHP-акселераторы, кэширование и т.п. и т.д. Чаще всего, соответственно, это многопроцессное выполнение запросов, внутри блокирующийся ввод-вывод, постоянное соединение, скажем, с БД в виде какой-то отдельной "нашлепки", как некоего состояния, которое может сохраняться между обработкой отдельных запросов и т.д. и.т.д.
Ruby on Rails – некая вещь, больше имеющая воздействие на мир. До Ruby 1.9, если я не ошибаюсь, потоки внутри Ruby были грин тредами, т.е. на самом деле были кооперативной многозадачностью. это честные потоки ОС. Есть различные варианты. Самый базовый – это многопроцессный и блокирующийся ввод-вывод. Есть framework EventMachine, который был списан с Python-овского framework-а Twisted, позволяющий сделать кооперативную многозадачность. У него есть свои плюсы и минусы, есть реализации, использующие EventMachine.
Есть Python. Python счастлив тем, что на нем можно написать любой вариант. Можно написать многопроцессный сервер, можно многопоточный, можно с кооперативной многозадачностью, с callback-ами или с грин тредами. Все доступно в различных вариантах и комбинациях, но в принципе все опять довольно скучно, все то же самое.
Есть Java со своей виртуальной машиной и все, соответственно, языки которые работают на JVM, потоки ОС уже давно, когда-то тоже в самом начале были грин треды. Есть возможность делать блокирующий и неблокирующий ввод-вывод, и как в любом мире enterprise есть какой-нибудь framework, который я могу воткнуть в середину, и он для меня вообще все это дело абстрагирует. Мне все равно, я ему просто сказал, что делать, а моя задача – только писать что то сверху.
Есть .NET, который все то же самое – потоки ОС и т.д., некое отступление, есть конструкция языка async/await, которая напоминает чем-то Deferred или Promise – такое движение к чему-то более светлому. Почему более светлому? Потому что до этого все очень одинаковое и грустное.
Есть Go, который появился относительно недавно, поэтому смог уже на старте оторваться от преследователей и сделать сразу что-то интересное. В Go есть горутины, которые являются по сути своей грин тредами, т.е. не являются потоками ОС, но с другой стороны внутренний механизм выполнения основан на том, что может быть запущено несколько потоков ОС, на которые будут шедулиться горутины, т.е. это комбинация кооперативной многозадачности и многопоточности. Внутри "под капотом" всегда неблокирующийся ввод-вывод. Из моей горутины я делаю операции, как будто бы они блокирующиеся, но на самом деле происходит переключение между горутинами, как только я заблокировался, будет выполняться другая горутина. В Go много всего еще интересного, там есть каналы, своя концепция конкурентного программирования, но у нас разговор не об этом.
Есть Erlang, который старше чем Go, и он тоже интересен тем, что у него своя модель конкурентного программирования, соответственно, в Erlang-е процессы, а в отличие от горутинов ы Go,l они больше похожи на реальный процесс с точки зрения логики, т.е. они полностью изолированы друг от друга, а горутины работают в общем адресном пространстве и видят всю память. С точки зрения реализации это те же самые неблокирующийся ввод-вывод, кооперативная многозадачность и использование потоков ОС для того, чтобы использовать все доступные ядра процессора.
Почему Go и Erlang я разместил в конце и почему они интереснее? Потому что уже в язык встроен по сути весь framework, чтобы делать эффективный сетевой ввод-вывод и эффективную многозадачность. И он уже есть в языке, и вы не замечаете, что это происходит, вы можете сразу начинать писать свои приложения. Например, если вы пишете http-сервер на Go, используя стандартную библиотеку Go, обработка каждого входящего запроса будет выполняться в отдельный горутине. Поэтому в этой горутине можете делать все, что угодно, это никоим образом не повлияет на другие, параллельно обрабатывающиеся запросы.
Все что угодно – это можете делать любые сетевые обращения, на чем-то блокироваться, будут выполняться другие потоки.
Вопрос из зала : Хочется узнать Ваше мнение про libevent. В каких случаях стоит использовать, не стоит? Может, что-то поподробнее, более практическое применение?
Ответ : Идет речь о С-шной библиотеке. Есть несколько библиотек, вся их задача – это реализовать паттерн реактора на С. Основная идея в том, что они абстрагируют механизм опроса готовности, который в каждой операционной системе немножко свой, и сверху предоставляют некий унифицированный интерфейс. Есть libevent и libev, есть еще несколько. Проще всего посмотреть на те или иные С-шные большие проекты – что они используют. Я помню, что в libevent-е были какие-то свои баги, в libev-e – свои, и в конечном итоге каждый большой проект выбирал себе "под капотом" что-то свое в зависимости от ситуации. Надо использовать что-то такое, если вы пишете на С.
Вопрос из зала : Я пишу на PHP и интересует такой момент: при формировании страницы мне нужно, например, сделать 2 сокет-запроса. Что Вы посоветовали бы, чтобы не дожидаясь ответа от этих сокет-запросов, можно было бы продолжить выполнение кода, но, получив ответ, "выплюнуть" все сразу в браузер – контент, сформированный по логике после вызова сокетов, и с тем контентом, который отдают сокеты?
Ответ : Я, к стыду своему, не знаю, как это сделать на PHP? и не знаю, есть ли что-то доступное. С точки зрения чисто теоретической можно написать С-шное расширение, которое бы это делало. Никакой проблемы принципиальной нет, надо использовать неблокирующийся ввод-вывод и т.д.
Вопрос из зала : Такой практически вопрос: у Вас в докладе была одна часть про то, что гораздо оптимальнее было бы отправлять запросы в базу, например, или еще каким-то сервисом с бэкенда все вместе сразу, если это позволительно. Есть ли какие-то советы, как это сделать в реальном мире? Потому что приложение уже есть и оно не рассчитывало на это. Переписывать бэкенд? Тоже надо полностью логику... или можно будет proxy какой-нибудь поставить, который будет принимать в себя запросы и сам отправлять их пачками?
Ответ : Proxy вам не нужен. Если у вас есть бэкенд, есть две части ответа на этот вопрос. Первая – техническая, которая перекликается с предыдущим вопросом. Можете ли вы это в принципе сделать из того framework языка программирования, на котором вы пишете. В большинстве случаев это возможно, потому что это можно сделать на С. А вторая часть этого вопроса – как вашу логику бэкенда изменить. И самое страшное – это, мне кажется, изменение логики бэкенда. Когда вам нужно отбросить последовательную модель программирования, которая есть в голове. Наверное, надо что-то переписывать, без этого никуда, но если вы хотите добиться уменьшения времени отклика, придется. Надо усложнять логику ради улучшения характеристик.