Сага о кластере. Все, что вы хотели знать про горизонтальное масштабирование в Postgres‘е
Олег Бартунов, Александр Коротков, Федор Сигаев

Илья Космодемьянский: Сейчас будет самая животрепещущая тема по PostgreSQL. Все годы, что мы занимаемся консалтингом, первое, что спрашивают люди: «Как сделать мультимастер-репликацию, как добиться волшебства?». Много профессиональных волшебников будут рассказывать о том, как это сейчас хорошо и здорово реализовано в PostgreSQL – ребята из Postgres Professional в рамках этого доклада расскажут про кластер все. Название соответствующее – «Сага» – что-то эпическое и монументальное. Сейчас ребята из Postgres Professional начнут свою сагу, и это будет интересно и хорошо.
Итак, Олег Бартунов, Александр Коротков и Федор Сигаев.
Олег Бартунов: Илья сказал, что мы будем рассказывать о том, как у нас Postgres'e все хорошо с кластером, но на самом деле мы расскажем о том, что сейчас происходит в Postgres-сообществе с этой темой. На самом деле тема неоднозначная, и мы постараемся это показать, почему это все не так трудно, и какие перспективы нас ожидают.
Сначала хочу представиться – мы трое являемся ведущими разработчиками от России в Postgres комьюнити.

Все, что мы сделали в Postgres, мы постарались перечислить в этой маленькой табличке (на слайде), наверное, вы знаете эти наши работы.
Мы решили сначала сделать некоторую сценку и показать, насколько это трудно и какая это боль – работать с распределенными вещами. Первый слайд у нас называется «Распределенные несчастия».

Федор Сигаев: Продолжу я.
Когда говорят о кластере, как правило, либо это люди, которые хорошо понимают, о чем это, и тогда сразу углубляемся в детали: «как у вас то и се реализовано, а как единый коммит, а как у вас между нодами взаимодействие, а как восстановление?», либо это люди, которые приходят и говорят, что кластер – это «мы поставим несколько тачек одна под другой, они все будут работать и нам будет счастье».
Я хотел показать в сценке, что это не так просто, и любой кластер требует некоторых решений. Сначала я попрошу выйти Ивана Панченко и Колю Шаплова – мы их назначим серверами. Сервер А и сервер Б. Мы будем действовать в надежде, что они честные сервера, т.е. честные базы данных. Сашу я попрошу быть клиентом. Клиентом не в смысле того, кто пришел в банк и расстался с деньгами, а в том смысле, что это какое-то приложение, которое обслуживает внешних клиентов нашего банка. Непосредственно тех клиентов мы иметь в виду не будем. Собственно, клиент – это наше приложение.
Вот наше приложение начинает транзакцию и раздает по команде begin. После этого товарищ клиент отходит от баз данных, пожимает им руки и говорит, что им нужно делать в какой-то абстрактной манере: «здесь что-то поменяй, здесь вставь, здесь удали, совершенно не принципиально что».
Теперь, как все любят говорить, двухфазный коммит решает наши проблемы. Клиент раздает им по команде prepare (подготовиться). Что на самом деле делает база данных? Она выполняет все триггера, она проверяет constraint и т.д. После этого, если эти команды прошли, то база данных обещает, что коммит пройдет всегда, т.е. что бы ни случилось, даже при потере питания.
Вот, у нас клиент выдает один коммит, идет к одной базе данных. Ваня у нас закоммитил. А вот во время второй Саша идет-идет, и тут выключается свет – все падают втроем. Упали. Свет включили. Они поднимаются, а коммит не пришел. Клиент вообще ни сном ни духом, потому что у него все прошло. База данных имени Вани Панченко прочитала свои WAL-логи, прочитала о том, что закоммитила, она находится в счастливом состоянии – я все сделала. База данных, представляемая Колей, сервер Б, читает свой WAL-лог, находит то, что там написано «prepared to commit», а после чего зависает с вопросом – коммита-то не было. Что ей делать? А ей пойти совершенно некуда. Клиент об этом ничего не знает, Ваня тоже – у него коммит свой есть. Вопрос: что делать, как из такой ситуации выпутываться?

Одна база данных все успешно закоммитила, вторая висит в вопросе. Выходов не так много. Вызываем DBA или кого-то еще, например, системного администратора. Тот пытается понять по логам, что произошло, что в одной базе закоммичено, а в другой – нет. В это время, если вы не боитесь потерять деньги, то ваш кластер работает с неконсистентными данными, либо вы напрочь останавливаете сервис, говорите, что у нас идут технические работы, мы выясняем, кто кому сколько должен.
Либо же вы вводите в работу арбитра. Клиент будет ходить к арбитру, а не к нашим базам данных, именно арбитр будет раздавать задания, писать себе в лог то, что мы в состоянии «prepared to commit», или «мы выполнили это». После этого раздаст коммиты и запишет себе в лог то, что первая база коммит записала, а вторая – нет. Далее мы проснемся, прочитаем логи и несчастному Коле скажем: «коммить то, что у тебя нашлось».
Беда тут такая, что писать этот арбитр с нуля – тоже очень и очень непростая задача. И все равно у вас есть момент, когда вы базе сказали коммит, а себе в лог записать не успели. Так что, это одна из проблем. Одна из многих проблем, с которыми сталкивается любое кластерное решение, которое хочет быть/казаться надежным.
Для следующей сценки представим себе банк, у которого есть 2 счета, на каждом счету у нас по 1000 кредиток. Один счет у нас у Вани, один – у Коли. Клиент 1 (Саша) опрашивает сумму счетов. Что он видит? Он видит 1000 кредиток, 1000 кредиток, в сумме – 2000 кредиток. Дальше Саша начинает транзакцию – он одной базе отдает «-500 кредиток», второй «+500 кредиток». И после чего спрашивает: «а что у вас есть в сумме?». В сумме есть: у Вани он видит результат 1500, а у Коли 500 кредиток отобрали – у него 500. Все хорошо. Клиент 1 снова видит 2000.
Дальше Саша начинает это дело коммитить. Коммитить он начинает с Коли. В этот момент просыпается клиент №2 (девушка из зала) и идет с вопросом: «а покажите, сколько у вас денег». Транзакция у Вани еще не закоммичена, и что видит первый клиент? Он видит 1000. А у Коли уже коммит наступил – у него уже 500. Что в результате видит несчастный второй клиент? Что деньги куда-то делись. Он видит в сумме 1500!
Это и есть проблемы неконсистентности – вы не можете одновременно закоммитить в две разных базы данных. Т.е. вам всегда нужно с этим как-то бороться. Локи выставлять, причем вне баз данных, либо запрещать доступ к базам данных. Вот, инсценированное несчастье прямо в лицах, с какими проблемами можно столкнуться.
Олег Бартунов: Вывод из этого представления в том, что вы не можете иметь целостный read с двухфазным коммитом, т.е. даже чтение не может быть целостным.
Федор Сигаев: Тут мы даже не очень привлекали двухфазный коммит, т.е. двухфазный коммит усложняет ситуацию с беготней, но на самом деле вы все равно оставляете «дырку», во время которой у вас одна база уже коммит приняла, а вторая – нет. Поэтому у вас всегда будет тот момент, когда у вас состояние двух баз неконсистентно.
Олег Бартунов: После того, как мы показали вам, что не все так просто, мы перейдем к некоторым политическим играм.
Почему политические игры? Это условное название. Postgres разрабатывается сообществом, а в сообществе у нас как бы демократия, и для того, чтобы добиться какого-то одного решения приходится применять очень много всяких телодвижений, разговоров и т.д. Все это я называю политическими играми.
До недавних времен мы вообще об этом не думали. А буквально года 2-3 назад возникла такая ситуация в open source, т.к. open source становится доминирующей моделью разработки программного обеспечения. На этом графике можно увидеть мировые тенденции:
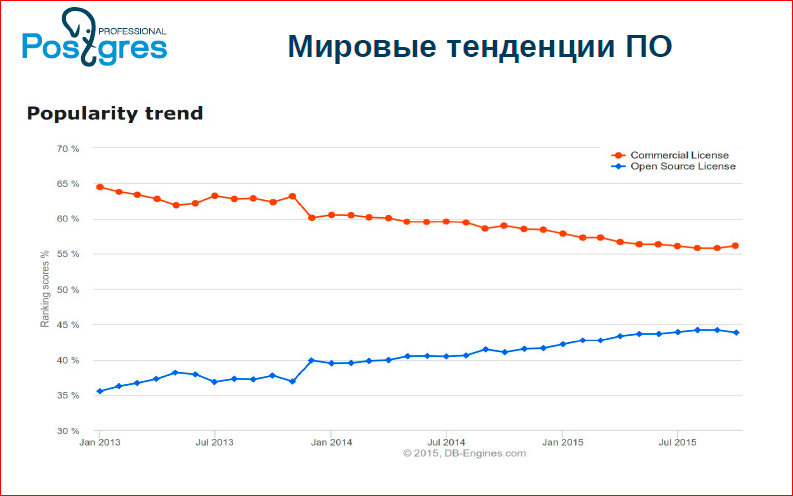
Мы видим, что open source’ные базы данных растут, а проприетарные базы данных – падают.
Просто модели решения. Вот, Gartner's Magic Quadrant показывает: слева – за прошлый год, а справа – это нынешний год.
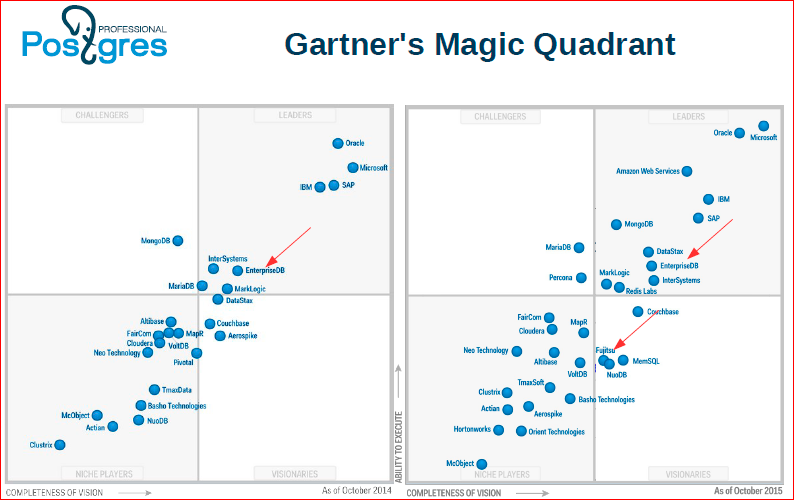
Мы видим, что Postgres в лице EnterpriseDB и Fujitsu уже вышел в лидеры баз данных. Это довольно замечательное событие, что впервые еще в 2014 году open source’ная база данных вошла в список лидеров баз данных. Т.е. рынок накаляется.
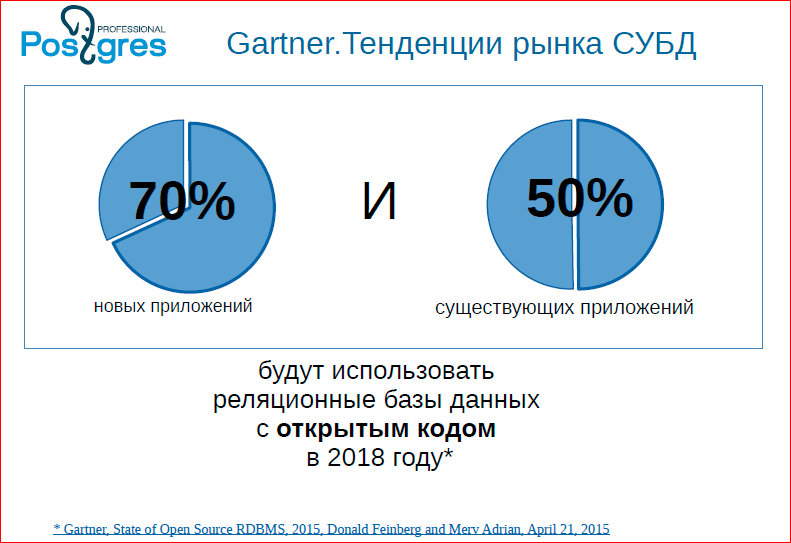
Видно, что 70% баз данных будут уже с открытым кодом в 2018 году. Это предсказание, в это можно верить и не верить, но тенденция существует, что сейчас люди все с большей охотой начинают использовать базы данных. И лидером баз данных с открытым кодом является Postgres. Есть еще MySQL – это тоже очень хорошая база данных, но Postgres является серьезной базой данных, которая находится сейчас на очень хорошем взлете. И это чувствуется у нас в комьюнити, потому что все клиенты, к которым мы приходим, начинают задавать вопросы, начинают требовать каких-то фич от Postgres.
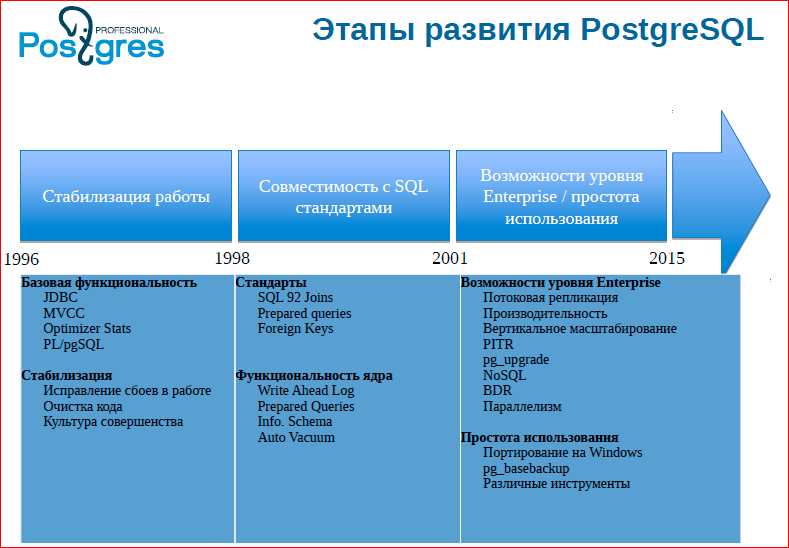
Этот слайд я стырил из презентации EnterpriseDB, на нем видны этапы развития Postgres. Они обозначили: сейчас идет этап Enterprise’а. Обратите внимание на фичи, которые там написаны, что они называют Enterprise’ом. Все бы хорошо, но мы не видим там слово «кластер». Т.е. это на самом деле, действительно так. У нас до сих пор в комьюнити не было мнения, что нужно кластерное решение.
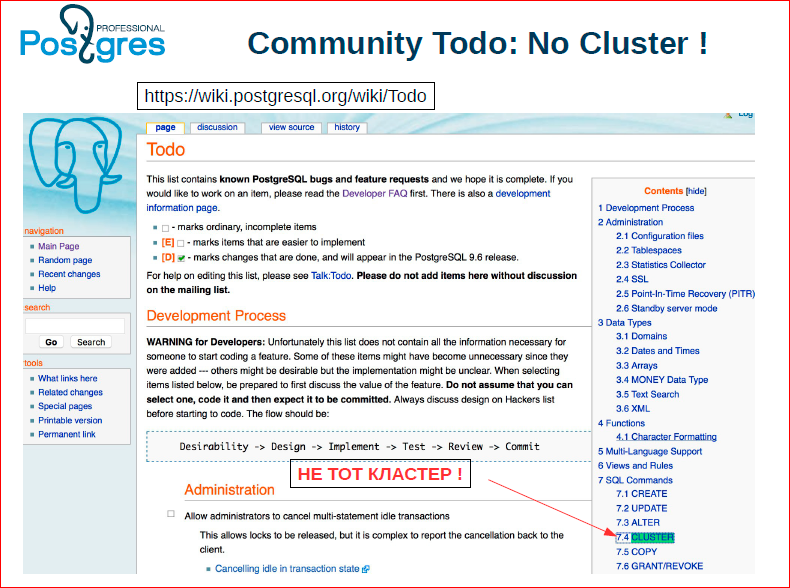
Если вы посмотрите на наш Todo (я специально сделал скриншот) – у нас там есть кластер, но это не тот кластер. Это команда cluster. Т.е. даже в нашем Todo нет ни слова о том, что нужно делать горизонтальный кластер и т.д.
Это все было сделано не случайно. С одной стороны сообщество консервативно, с другой стороны – рынок нас еще не подпер.
Сейчас уже, особенно в России, Postgres рассматривается как кандидат на очень большие проекты, и понятие кластер стало must have.
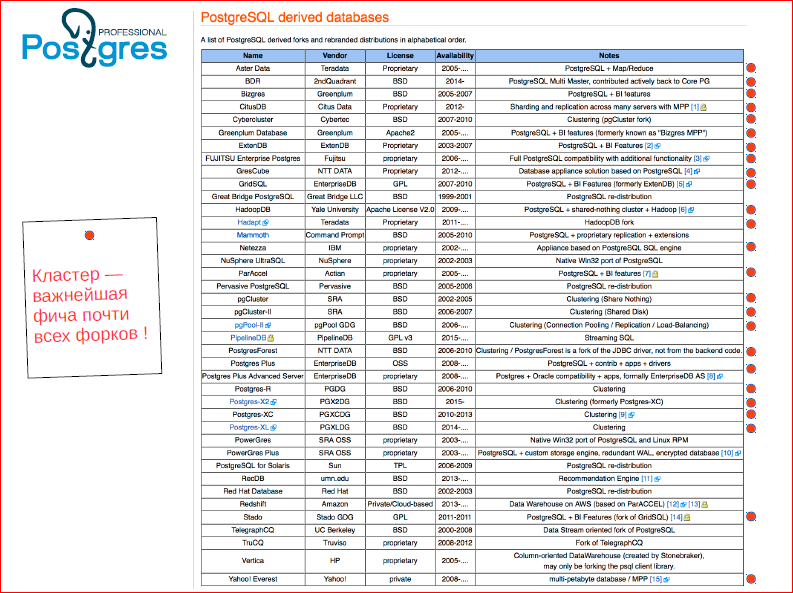
Посмотрите на страничку форков Postgres’а. Видите, сколько форков. И это не все.
Красненькими кружочками я обозначил те форки, в которых кластер является фичей. Мы видим, что практически все форки, которые появились от Postgres’а, появились только потому, что не хватало кластера. И, в конце концов, сообщество начало думать о том, что действительно кластер должен быть в нашем Todo, что мы должны что-то делать.

Это уже не первый раз так происходит. Старожилы Postgres, старые пользователи, помнят разговоры о репликации. Когда-то у Postgres не было репликации, и говорилось о том, что репликация и не нужна в ядре, репликация должна быть сторонним продуктом. И так было до тех пор, пока опять же пользователи, сообщество не осознало вдруг, что оно должно быть в ядре. И оно у нас появилось и теперь репликация является хорошим, нормальным инструментом, которым все пользуются. Также была история с портом на windows – сколько мы хотели, сколько у нас было сил, мы отбрыкивались от порта на windows, но в конце концов его сделали.
Федор Сигаев: Но мы отбрыкались, сделали не мы.
Олег Бартунов: В результате сейчас наступила та самая революционная ситуация, когда низы хотят, верхи не решились. Причем, интересная ситуация – мы организовали компанию, мы разговариваем с нашими кастомерами, и говорим: «мы делаем кластер». The 2ndQuadrant говорит то же: «мы делаем кластер». EnterpriseDB говорит: «мы тоже делаем кластер». Однако, все кастомеры, как один, говорят: «нас не интересует ваш roadmap, нас интересует roadmap сообщества», т.е. нужно чтобы в сообществе был этот кластер, и чтобы сообщество работало.
На слайде я кратко привел решение, Саша расскажет.
Александр Коротков:
- Наверное, многие слышали, есть Postgres XC XL. XL – это был форк от Postgres XC. XC сейчас перешел в X2, это отдельный форк, который реализует шардинг и реплицируемые таблицы, он достигает глобальной консистанси посредством отдельного сервиса, который там называется GTM – Global Transaction Manager. Его сейчас развивают 2ndQuadrant, МТТ и Huawei. Huawei, кроме этого, имеет еще и свой проприетарный форк MPPDB, это форк от XC.
Олег Бартунов: Хочу сказать, что это базы данных, у которых уже имеются живые пользователи, т.е. многие банки в Китае используют эти XC.
Александр Коротков: Несмотря на то, что там были баги с консистанси, Китай настолько смел, что готов на этом запускать банки.
- Есть pg_shard – это open source расширение к Postgres, которое предоставляет базовую функциональность по шардингу. Опять же, там нет никакого менеджера транзакций, нет распределенной консистанси, но для каких-то вебовских задач его можно использовать.
- Есть Citus DB – это пока проприетарная база, которая компания Citus Data обещает вот-вот открыть. Там есть функции побогаче, т.е. более сложные запросы. Там можно какой-то лаб организовать, но опять же для OLTP распределенная консистанси никакая не гарантируется.
- FDW – это пока что такой подход, который EnterpriseDB пытается сделать для Postgres, т.е. в основную мастер-ветку его добавить. Идея в том, чтобы использовать уже существующий механизм Foreign data wrappers, т.е. обращение к какому-то внешнему источнику данных для того, чтобы сделать шардинг. В 9.6. уже закоммитили патч, который позволяет через существующее в Postgres’e наследование сделать партицирование. Точно так же, если делать наследование foreign таблиц, внешних таблиц, то можно сделать некий достаточно простой шардинг. Но, опять же, возникает много вопросов к тому, насколько оптимизатор может оптимизировать такие распределенные запросы.
Сейчас EnterpriseDB работает над патчами, чтобы можно было делать Aggregate Pushdown, т.е. чтобы не все вытягивать с шардов, а потом агрегаты считать, а чтобы можно было агрегаты посчитать на самих шардах. Точно так же Join pushdown... И такой достаточно длинный roadmap, который не до конца, может быть, полный и не понятно, когда мы получим полноценный распределенный оптимайзер. Тем не менее, плюс этого подхода в том, что мы улучшаем FDW, и это само по себе хорошо.
- Greenplum – это коммерческий форк от компании Pivotal, который совсем недавно был зарелизен в open source, 3 дня назад.
Олег Бартунов: Вы можете на GitHub скачать Greenplum, скомпилировать, поставить, и вас уже будет та самая массивная параллельная база данных, на которой долгое время работал eBay, которая работает сейчас в Тинькофф Банке и т.д. Т.е. модель open source развития здесь открыта ипоказывает свои преимущества.
Федор Сигаев: Только имейте ввиду – это OLAP базы данных, а не OLTP, т.е. если вам что-нибудь массово проанализировать в Postgres, то это можно пощупать Greenplum или pg_shard, но заводить туда деньги в надежде, что будут надежно перечисляться, лучше не надо.
Александр Коротков: И вот наш проект, который мы начали – это Distributed Transaction Manager для Postgres мастера. Про него мы расскажем чуть подробней отдельно.
Олег Бартунов: Это такие живые активные проекты, которые есть, у которых есть свои кастомеры, они развиваются. И мы видим, что есть ресурсы, а решения комьюнити нет.
На прошлом PGCon’е мы подняли этот вопрос и договорились о том, что все-таки устроим большую встречу, так называемый кластер саммит, где будем решать эту проблему, что будем делать с этим, как жить?

2 дня назад мы прилетели с этого совещания. Встретились мы в Вене и обсудили животрепещущие проблемы кластера, т.е. подняли вопрос, будет у комьюнити кластерное решение в Todo или не будет.

Решили, что ситуация созрела настолько, что это надо обозначить в нашем Todo. При этом надо продолжать развивать кластерные решения, потому что, как мы уже показывали, кластерные решения – это очень сложные вещи, и мы не можем заранее сказать, что завтра или через 2 года это решение победит, поэтому решения должны развиваться. При этом они должны так развиваться, чтобы, скажем, коммит нашей компании не заблокировал дорогу другим решениям – это очень важно. Решили – peace and love.
Появилась идея сделать инфраструктуру Postgres так, чтобы кластерные решения могли развиваться как расширения, что сильно облегчит развитие. Мы рассказали про наш менеджер распределенных транзакций, людям эта идея показалась интересной, и мы будем пропихивать это дело в 9.6, т.е. в 9.6 мы постараемся, чтобы распределенные транзакции уже были в Postgres’e, и любой желающий уже мог делать кластер, по крайней мере? на уровне приложения.

Я добавил в слайд, который я взял у EnterpriseDB, 31-е октября 2015 года. Я назвал этот период как горизонтальное масштабирование (шардинг), и мы написали список задач, которые нам нужно будет решать. Т.е. это то, что мы сейчас продвигаем в комьюнити, чтобы комьюнити озаботилось этим.
Александр Коротков: Цели понятны, и мы хотим scalability как на чтение, так и на запись, кроме этого, чтобы была high valability. Достичь этого можно, например, с помощью redundancy, т.е. один и тот же шард держится не в одной копии, а в двух копиях.
И по задачам тут разбили, здесь самые крупные. Понятно, что их на самом деле еще больше. Задача, которой мы занялись – это управление распределенными транзакциями. То, где сейчас пересекается много разных интересов – это планировщик и исполнитель распределенных запросов, т.е. FDW – это один подход к распределенным запросам, pg_shard – другой подход, Postgres XC XL – уже третий подход. И может быть еще 4-ый, 5-ый и т.д. Но мы надеемся, рано или поздно в этом направлении мы тоже к какому-то единому знаменателю придем.
Олег Бартунов: Тут на конференции есть Брюс Момжан, он является ответственным человеком, который должен в Todo вписать пункт о кластерности, и тогда у нас все пойдет, потому что надо как-то объединять усилия.

Это картинка обозначает, что ингредиентов много, из них можно много чего приготовить, но не факт, что получится.
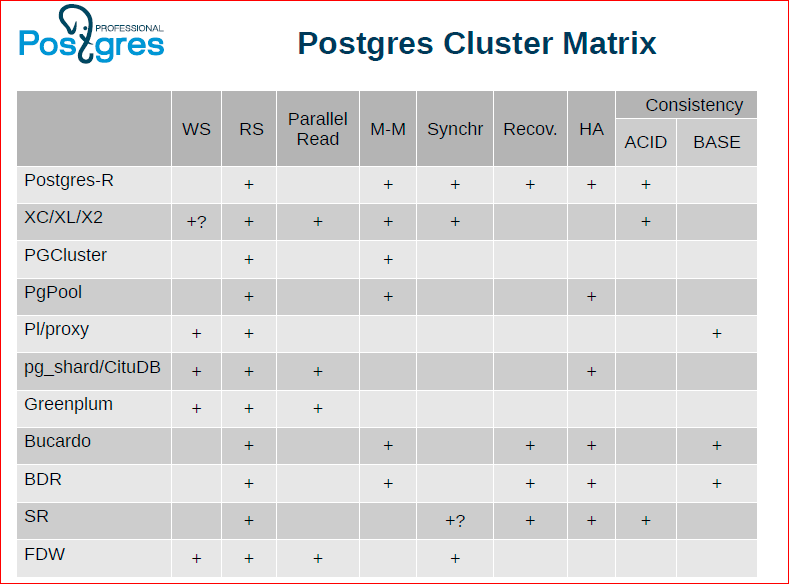
Александр Коротков: В таблице мы попробовали сделать такую матрицу, вписали сюда кластерные решения, причем как те, которые сейчас существуют и развиваются, так и те, которые когда-то в истории были и уже не поддерживаются.
Федор Сигаев: Мы взяли самые популярные. Олег вначале показывал, что эта матрица еще больше, мы могли бы сделать попиксельную графику, но из нее будет совсем ничего не понятно.
Олег Бартунов: Можно долго рассматривать эту таблица, по ней можно спорить, она показывает то, что идеального решения нет. Например, XC/XL/X2 выглядит наиболее привлекательно, у нее больше всего плюсиков. У FDW и pg_shard тоже достаточно много плюсиков, но чего-то не хватает, в частности им не хватает целостности данных.
Когда началась вся эта драка, каждая компания заявила о том, что «мы делаем решения, наши решения хорошие» и т.д. Мы ведь тоже взяли XL и начали с ним играться, решили делать свой кластер, но потом мы поняли, что XL не очень готов для того, чтобы использовать его в продакшене, и мы решили не ввязываться в общую драку, а сконцентрироваться на том общем технологическом элементе, который нужен всем. Т.е. всем кластерным решениям нужен менеджер распределенных транзакций.
Поэтому мы и выбрали это направление и реализовали его. Сейчас, мы расскажем, что это такое и почему это важно, и что оно дает кластерным решениям.
Александр Коротков: Что мы, вообще, хотим от менеджера распределенных транзакций? Понятно, что мы хотим, чтобы коммит по нашей распределенной системе был атомарным. Атомарный означает, что, во-первых, он либо атомарно везде прошел, либо везде откатился. Во-вторых, мы хотим его атомарной видимости, т.е. это значит, что если вы делаете запрос на чтение к нескольким базам (то, что мы во 2-ой сценке показывали), то каждый отдельный коммит мы должны либо видеть везде, либо везде не видеть. Не должно быть такого, что мы на одном сервере увидели, что деньги уже перевелись, а на другом сервере увидели, что они не перевелись, и в итоге у нас сумма не сходится.
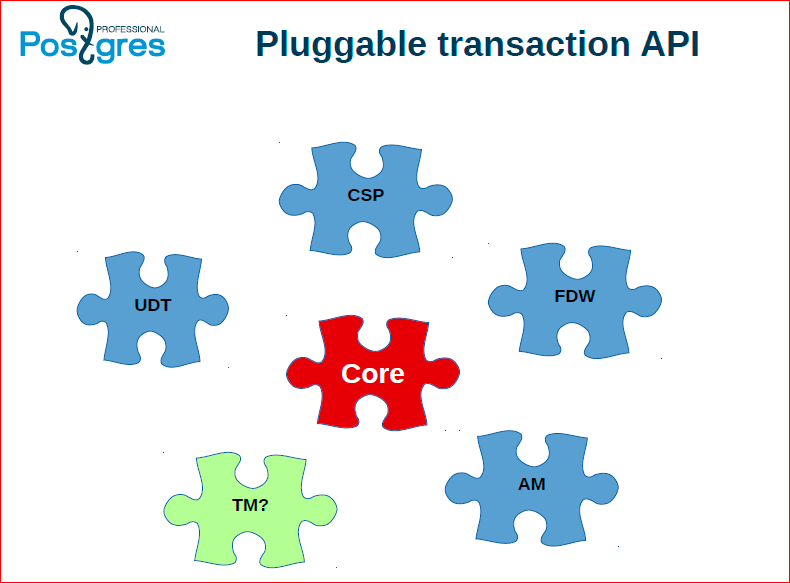
Для такой проблемы есть разные решения, по своим свойствам ни одно из них не является идеальным. Подробней об этом расскажу в следующих слайдах, но появилась идея, что мы хотим некоторой pluggable API для менеджера транзакций. Т.е. у нас есть в Postgres’е менеджер, который позволяет выполнять локальные транзакции – это одна реализация, потом к ней еще добавим несколько реализаций менеджеров распределенных транзакций. Пока что мы можем три штуки выделить, возможно, потом, у нас появятся еще какие-то идеи, может быть даже лучше, чем те, которые мы сейчас видим.

Мы взяли и выделили API, который нужен, чтобы реализовать такой менеджер распределенных транзакций. Это просто некоторый набор функций, которые в Postgres до этого были зашиты, и мы их выделяем в отдельную so’шку, в отдельную библиотеку, которую можно подменить.
Олег Бартунов: В целом, мы просто идем по пути pluggable. У нас есть планер pluggable, executer pluggable, мы можем делать типы данных, индексы, а теперь сделали так, чтобы Transaction Manager тоже был pluggable.
Федор Сигаев: Для тех, кто не знает, executer в Postgres целиком pluggable, т.е. можно использовать абсолютно свой executer, точно так же как планер.

У нас спрашивают: почему именно эти семь функций, а не другие семь функций на предыдущем слайде? Ответ такой: потому что мы попробовали три разных по природе менеджера и выяснили, что этих семи функций достаточно для того, чтобы вынести Transaction Manager из Postgres в отдельный процесс.
Александр Коротков: Семь потому что мы хотели бы шесть, но шесть не получилось, а восемь не нужно.
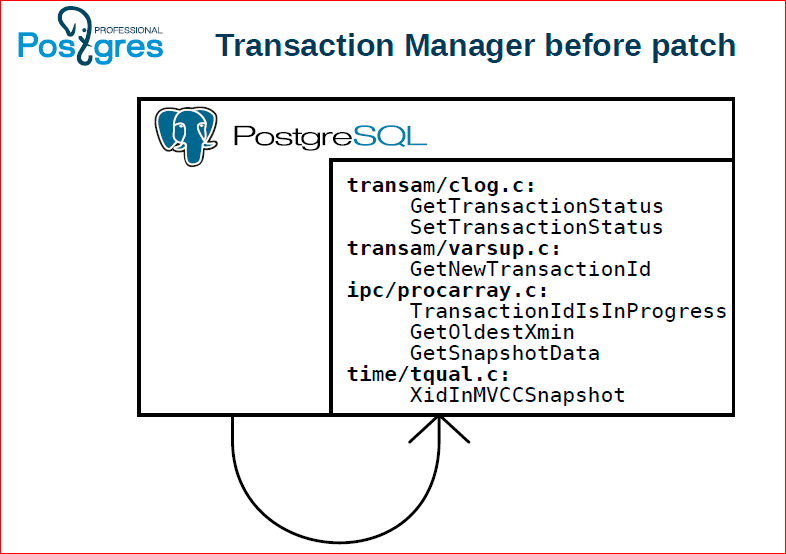
Это как было до патча, т.е. если все эти вызовы шли непосредственно, были зашиты в сам Postgres.
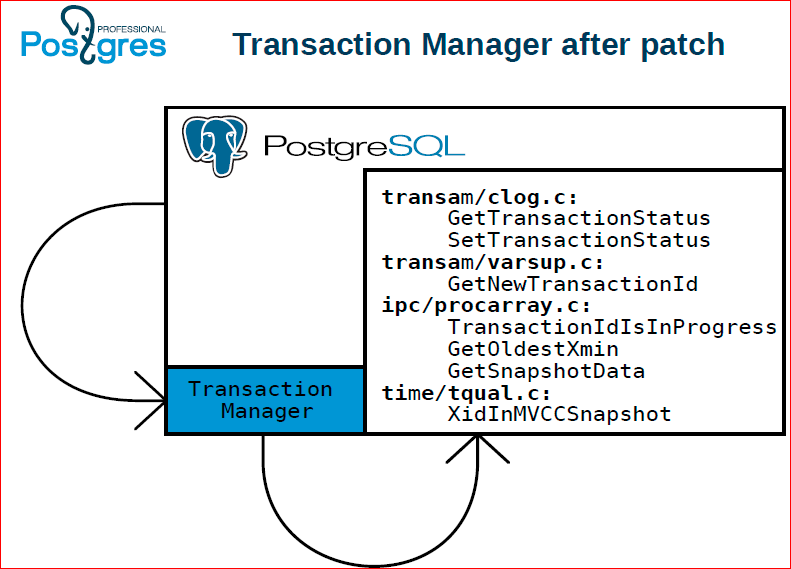
А дальше мы это выделили в отдельный компонент, который называется Transaction Manager.
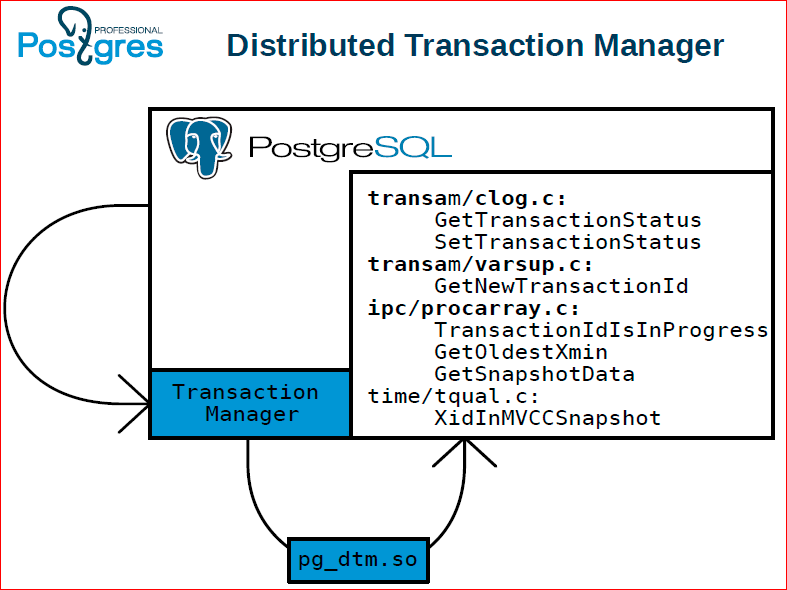
Далее.
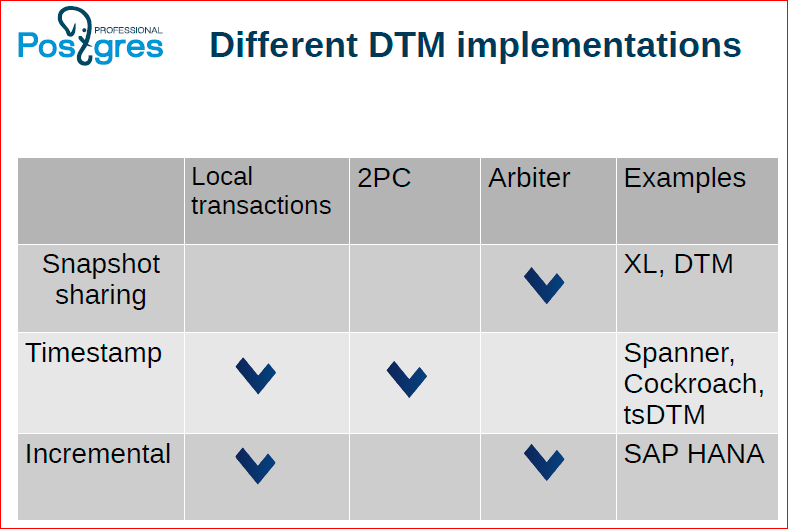
Это про то, какие у нас бывают разновидности способов управления распределенными транзакциями, какие у них есть преимущества и недостатки.
-
Первый подход – Snapshot sharing – это подход, который сейчас используется в Postgres XC, XL. Идея в том, что у нас есть некоторый центральный арбитр, через который проходят все коммиты, и он же раздает всем снепшоты. Благодаря этому обеспечивается то, что каждый снепшот получен от этого центрального арбитра, и значит, что какой-то коммит мы покажем как видимый, только когда он пройдет на всех узлах.
Какие у него есть преимущества? То, что для использования такого подхода нам не нужно использовать двух фазный коммит.
Но минусом является то, что мы не можем использовать при этом локальные транзакции, соответственно, каждая транзакция должна центрально координироваться – это является недостатком, оверхед у нас есть, все время надо ходить в сеть и т.д.
-
Следующий подход он на основе Timestamp. Здесь идея в том, что для того, чтобы обозначить сшепшот, использовать Timestamp. Это может быть не совсем реальный Timestamp, это может быть некое синтетическое время, для которого выполнены определенные гарантии, в частности, нам, например, нужно обеспечить, чтобы время никогда не шло назад. В классическом MTP это не возможно, оно иногда прыгает назад. Да, он взял, связался с сервером, понял, что он перегнал, и назад себя. С нашей точки зрения время всегда должно идти вперед.
У этого подхода основное преимущество в том, что он может работать без центрального арбитра, в нем возможны локальные транзакции, и для того, чтобы выполнить какие-то транзакции, достаточно задействовать только те узлы, которые она непосредственно трогает, никакие больше узлы не надо задействовать.
Минусом является то, что для него нужно использовать two-phase commit, который дает приличный оверхед, но над уменьшением оверхеда, над неким облегченным двухфазным коммитом для этого подхода мы тоже работаем.
-
Есть еще один подход – это инкрементальные снепшоты. Идея в том, что у нас есть отдельно локальные транзакции и глобальные транзакции. И глобальные транзакции должны координироваться через некий центральный арбитр, а локальные транзакции могут проходить локально. Здесь, как бы, все здорово, но на самом деле в этом подходе есть еще много трейдофф’ов внутри него, потому что может получиться так, что вы не всегда можете локальную транзакцию преобразовать в глобальную, т.к. там получится так называемый кросс феномен, или же вам придется пожертвовать производительностью глобальных транзакций. Сейчас углубляться в это не будем, есть отдельная хорошая научная статья, где рассмотрены все различные варианты приготовления инкрементальных снепшотов.
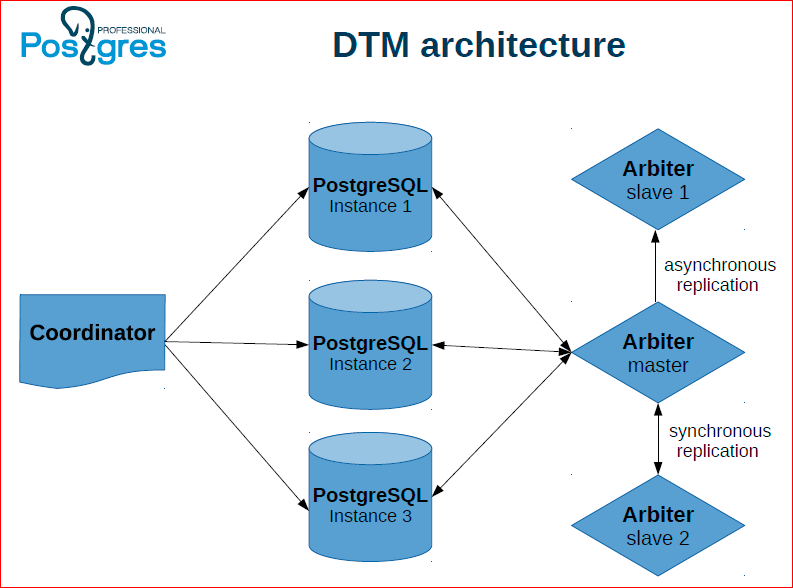
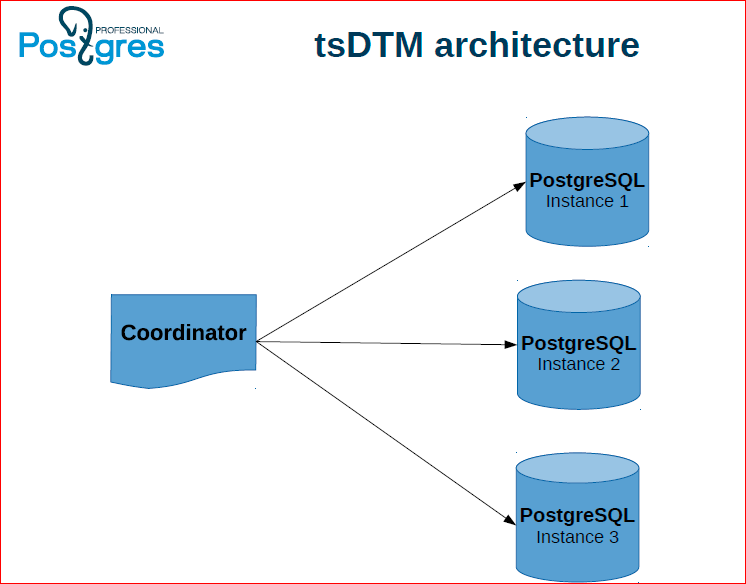
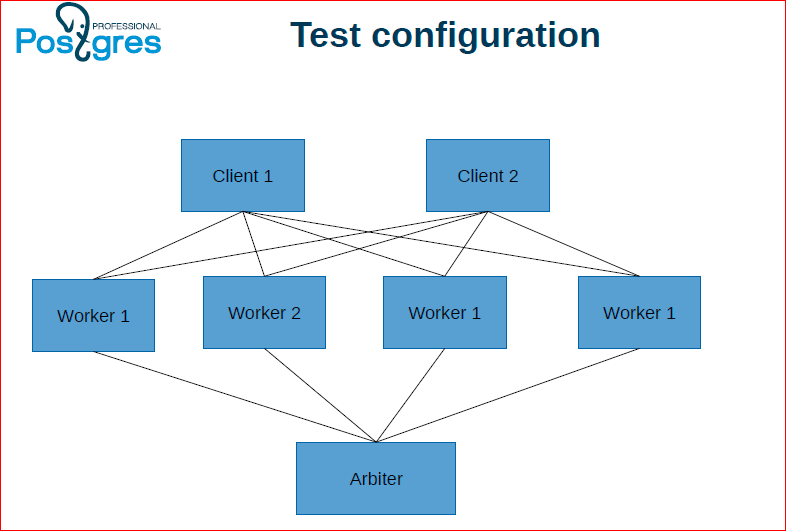
Такая архитектура – это первый подход, который мы называем DTM. У нас есть несколько инстансов Postgres, на которых непосредственно хранятся данные, координатор, который выполняет транзакции и арбитр, который хранит статусы транзакций, выдает снепшоты. При этом для того, чтобы этот арбитр не был единой точкой отказа, мы его тоже дублируем, делаем слейвы и в случае сбоя, мы переключаем арбитр на слейв.

Вот как это может работать: у нас координатор держит два коннекта к двум серверам. С одного из них он начинает распределенную транзакцию, а другому говорит присоединиться к этой распределенной транзакции. Далее выполняет какие-то действия, а потом выполняет на обоих узлах коммит.
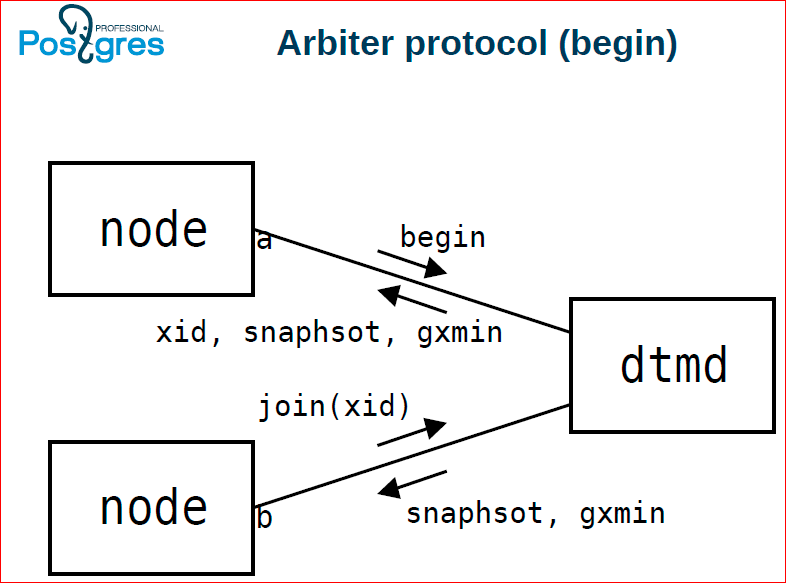
При этом эти оба узла работают с dtmd – с демоном для поддержки распределенных транзакций. Та нода, с которой началась распределенная транзакция получает begin, в ответ ей назначается id’шник этой транзакции, снепшот. Потом следующая нода присоединяется к этой транзакции, дает команду join, тоже получает снепшот. Global xmin нужно поддерживать для того, чтобы вакуум мог распределено только нужные вещи чистить.
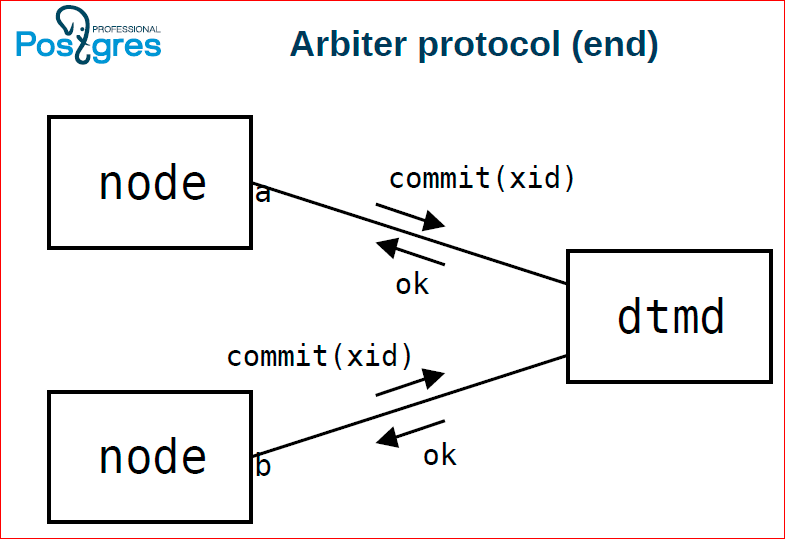
В конце обеим этим нодам посылаем команду, клиент говорит коммит, они в свою очередь на dtmd посылают тоже коммит. Если dtmd видит, что от каждой из нод, которые участвовали в этой транзакции, пришел коммит, тогда он им обеим возвращает ОК. Если хотя бы одна из них сказала ему roadback, то он возвращает всем из них ошибку.
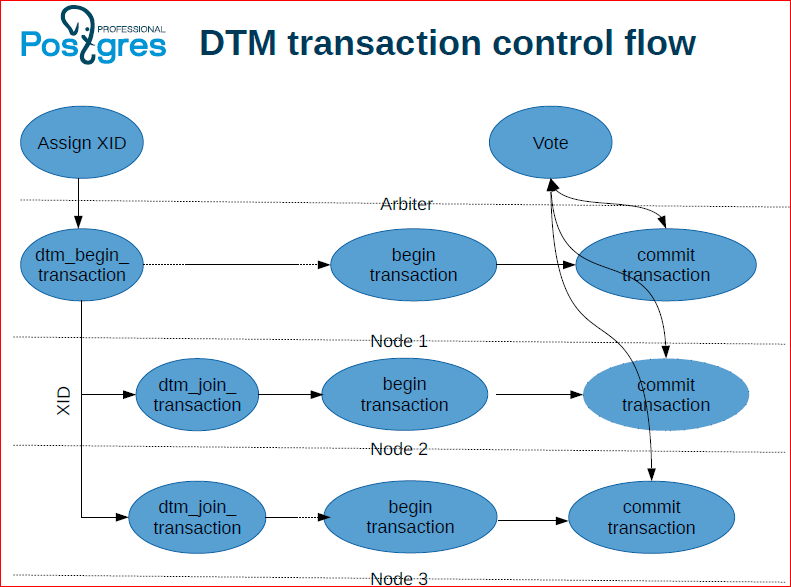
flow – это то, что я объяснил, только в виде схемы.
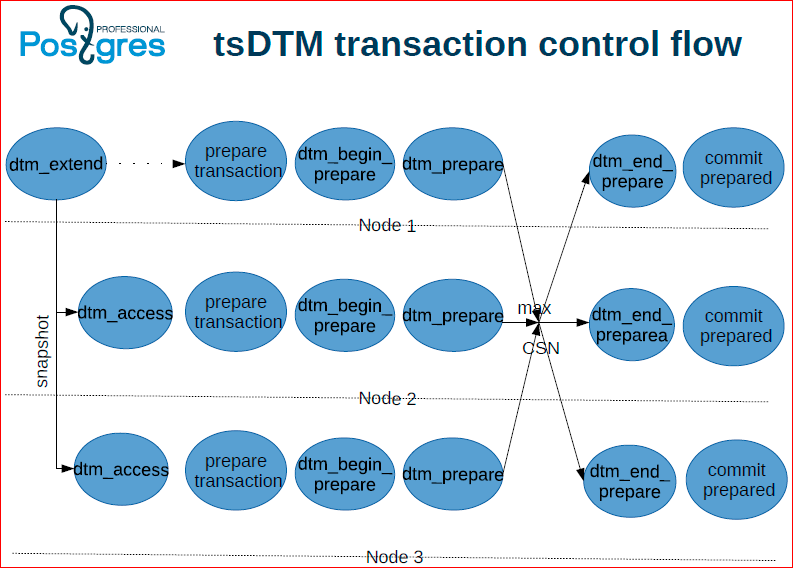
Другой вариант – это, когда на Timestamp, тут никакого центрального арбитра нет, здесь все возлагается на инстансы Postgres’а и на координатор.
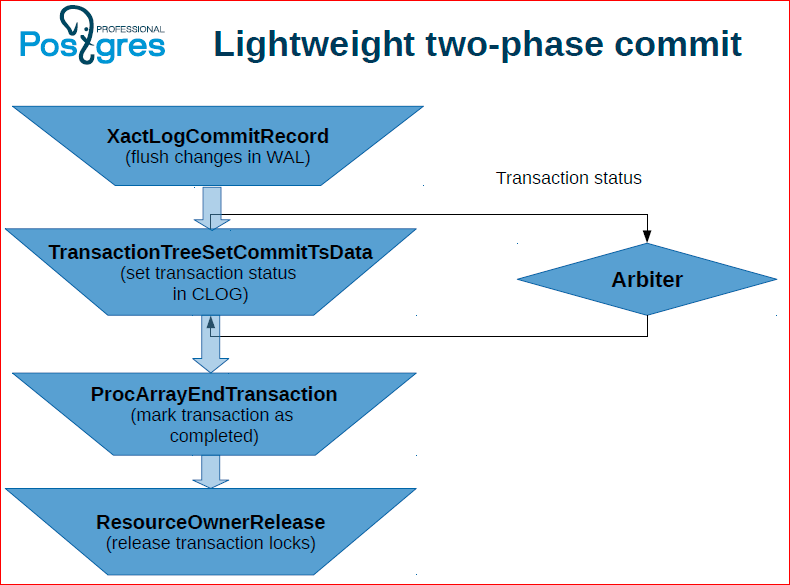
Здесь приблизительно то же самое, но особенность в том, что приходится делать фактически двухфазный коммит. Мы надеемся, что мы сможем сделать его потом облегченным.
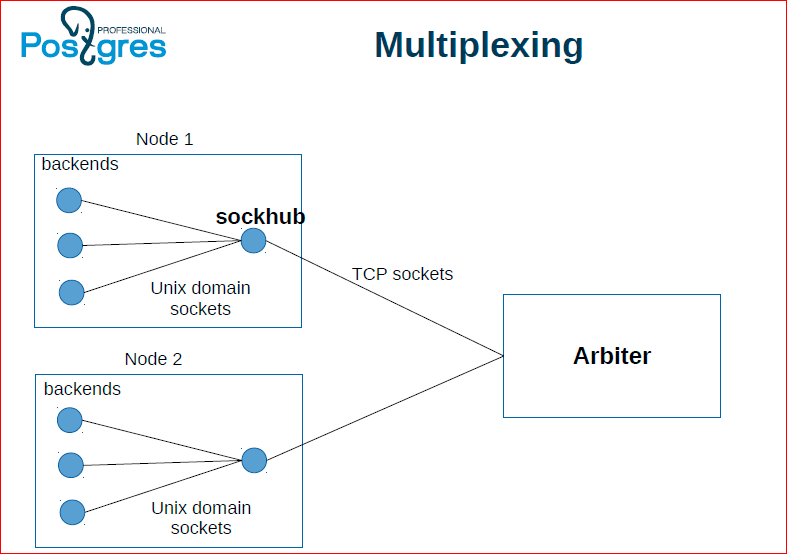
Это по поводу связи с арбитром. Если на каждый чих, т.е. на каждое получение снепшота нам отдельный TCP-пакет посылать к арбитру – это получается очень долго, поэтому есть специальный демон, делаем sockhub, который соответственно группирует обращения к арбитру и пачками их пересылает и получает ответы.



Здесь некоторые примеры, которые мы использовали для бенчмарков.

Классический банковский пример, когда мы с одного счета снимаем, на другой переводим – собственно наша вторая сценка. Аналогично у нас был второй поток, который в нашей сценке выполняла девушка, из которого мы считали сумму и проверяли сходится она или нет.
Олег Бартунов: Здесь в примере мы использовали pg_shard. pg_shard вы можете скачать, скачать даже патч, и у вас будет транзакционность.
Александр Коротков: Мы брали и применяли свой подход к распределенным транзакциям к уже имеющимся решениям, у которых поддержки распределенных транзакций нет, – это pg_shard и FDW.
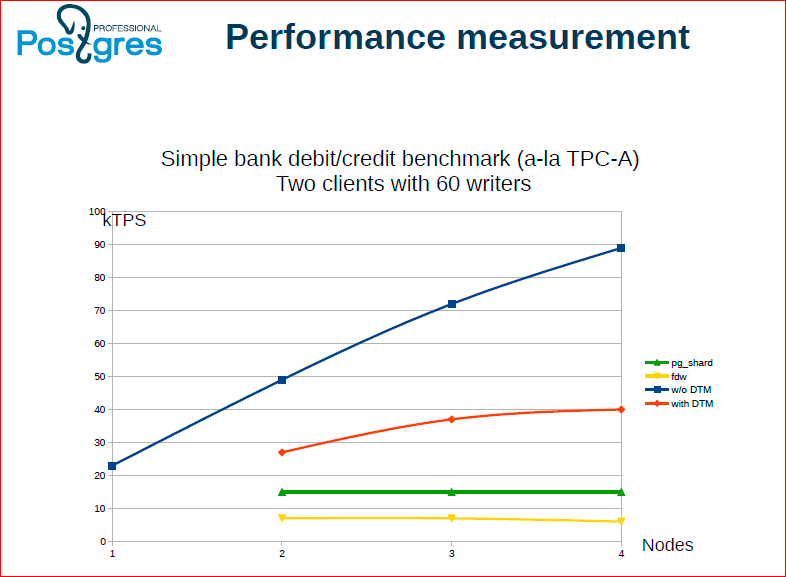
Вот результаты.
- Синенькая – это то, как мы сделали без менеджера распределенных транзакций. Т.е. тут скорость за счет отсутствия консистентности между нодами.
- Красная – это, когда все делает клиентское приложение.
- Зеленая – это pg_shard.
- Желтая – FDW.
Соответственно, мы нашли, что упираемся в скорость взаимодействия с арбитром. Определенная оптимизация уже сделана, потом дальше продолжаем делать. Ко всему этому у нас есть подход с Timestamp, который в плане масштабируемости очень многообещающий, потому что в нем нет единой точки, куда все ходят за снепшотами.
Олег Бартунов: Вы тут не расстраивайтесь, что ниже, чем синенькая – вы никогда не можете быть быстрее, чем синенькая, нужно платить. Здесь важно, что она масштабируется, что три ноды быстрее, чем одна, и при этом у вас соблюдаются и consistency и high valability. Я сам сначала расстраивался.
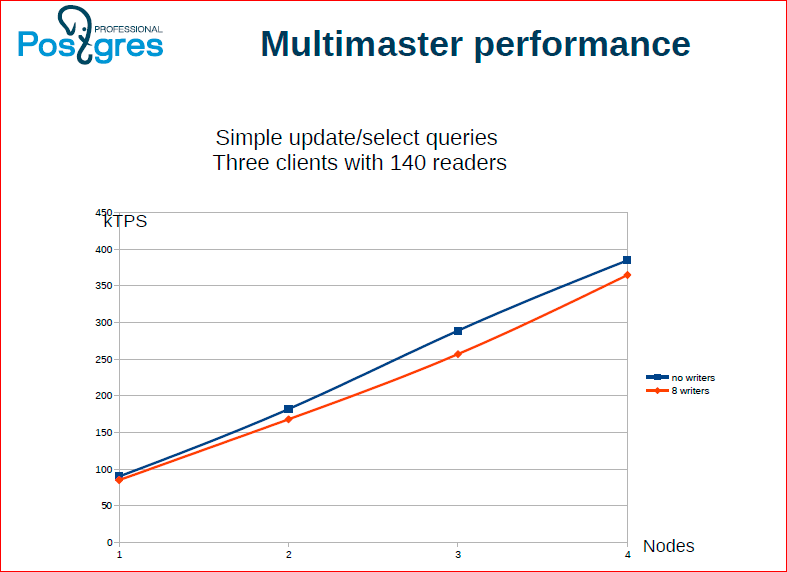
Мы сделали мультимастер.
Александр Коротков: У нас есть некоторое ограниченное число пишущих потоков, которые реплицируют свои операции записи между всеми серверами, и есть читающие потоки. Можно видеть, что чтение масштабируется линейно, как и ожидалось. В случае, когда у нас мультимастер, мы можем читать с любого сервера.

Roadmap у нас следующий – сделать патч, который называется XTM – расширяемый менеджер транзакций для 9.6., потом поэкспериментировать с разными другими подходами к реализации распределенного менеджера транзакций, в том числе, и подход на Timestamp довести до ума, продолжить нашу работу по интеграции с разными решениями.
Мы показали, кто сейчас уже может выиграть от нашей работы по менеджеру распределенных транзакций:
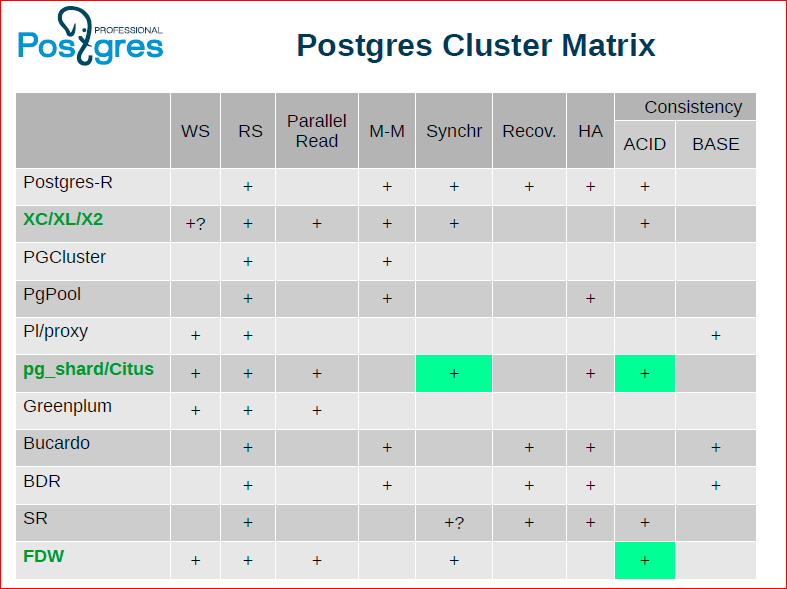
Во-первых, это pg_shard и FDW – они фактически могут получить себе свойства ACID благодаря нашему менеджеру распределенных транзакций. А форки XC/XL/X2 они могут просто получить себе меньший труд для синхронизаций с мастером, потому что менеджер распределенных транзакций уже будет в мастер-ветке и, соответственно, они могут меньше труда прикладывать, не синхронизировать свой GTM.
Олег Бартунов: Заканчивая, мы благодарим вас за внимание и говорим, что ждем будущего. Мы надеемся, что комьюнити вставит это все в Todo... Опыт показывает, что Postgres, конечно, раскачивается, но потом все делает очень качественно.