HighLoad++ для начинающих
Чтобы рассказать, что такое highload, надо для начала определиться с термином. При попытке "разгадать" сам термин, начнем, естественно, с прямого перевода – это высокая нагрузка.
Терминология
53.328*10^9 запросов в секунду – вот такую цифру я выписал из википедии. Хватит ли нам столько – непонятно, но это у нас средний CPU сейчас столько делает.
Если подходить более реалистично, то надо определиться с цифрами. Например, один запрос в секунду – это нагрузка явно не highload, любой сервер, вроде бы, справится. Но, например, если он перекодирует видеоролики, то тут может наступить highload.
Соответственно, я определяю высокую нагрузку как нагрузку, с которой железо не справляется по какой-то причине.

Когда у нас происходит высокая нагрузка, начинают вести речь о highload-е – когда мы достигаем каких-то технических ограничений, т.е. у нас кончается что-нибудь – CPU, память... Я еще вынесу хранилище отдельным пунктом, потому что для веб-серверов хранилище обычно – это какой-то внешний элемент.
Дополнительно мы сталкиваемся еще с такими трудностями – сейчас уже менеджеры перестали, но лет 5-7 назад, когда они покупали новый сервер, а вы через некоторое время говорили "нам этого сервера не хватает, нам надо больше", они удивлялись: "мы вам купили самый крутой компьютер на свете, а вы умудрились его тормознуть?". Сейчас они уже не удивляются, но вопрос недоиспользования "железа" так и остается самым основным. Т.е., если вернуться к тому, что средний процессор сейчас способен обработать 53 млрд. операций в сек., то объяснить людям, почему тормозит, очень сложно. Ну и трудности масштабирования, все эти проблемы, которые происходят с высокой нагрузкой, они сводятся к одному термину – архитектурные проблемы в вашем проекте.
Цикл выполнения одного запроса
Для иллюстрации рассмотрим типичный веб-сервер, написанный неважно на чем – на Perl, Python, Ruby... Берем стандартный framework, делаем веб-сервер, пишем форум, доску объявлений и т.д. Задачи одного цикла этого сервера сводятся к следующим пунктам:
- запросы сети читаются;
- парсятся;
- отправляются запросы в БД;
- формируются ответы;
- отправляются клиентам.
Т.е. если говорить о традиционной реализации (apache, например), то все это сводится к тому, что на одну сессию выделяется один процесс или один тред. Ну, или если вернуться к определению "highload" как к нагрузке, с которой не справляется железо, то что они в этой архитектуре могут сделать?
Они могут увеличить число процессов на один цикл или тредов, которые работают, либо масштабировать уже по серверам, т.е. вводить в строй сервера.
Вот, к примеру, рассмотрели одну страничку одного проблемного сервера в реальных измерениях. У нас получилось следующее: примерно на 100 запросах в секунду возник highload. Первое, что сделали, – это увеличили число процессов в работе, т.е. было 8 процессов, сделали 20, потом 30 и т.д. Временно помогло, но на 150 запросов в секунду опять начались проблемы. Что делать? В этот момент прибегают менеджеры и говорят, что сходили на конференцию "Highload", где им рассказали про всякие мега крутые технологии, которые они сейчас купят и все перепишут... Тут их останавливают люди, которые говорят, что они 3 года над этим работали и переписывать это надо тоже 3 года... Что делать? Добавлять второй сервер тоже не всегда просто...
Лечение любой болезни начинается с постановки диагноза, т.е. для начала измерим хотя бы температуру, а потом будем делать выводы...
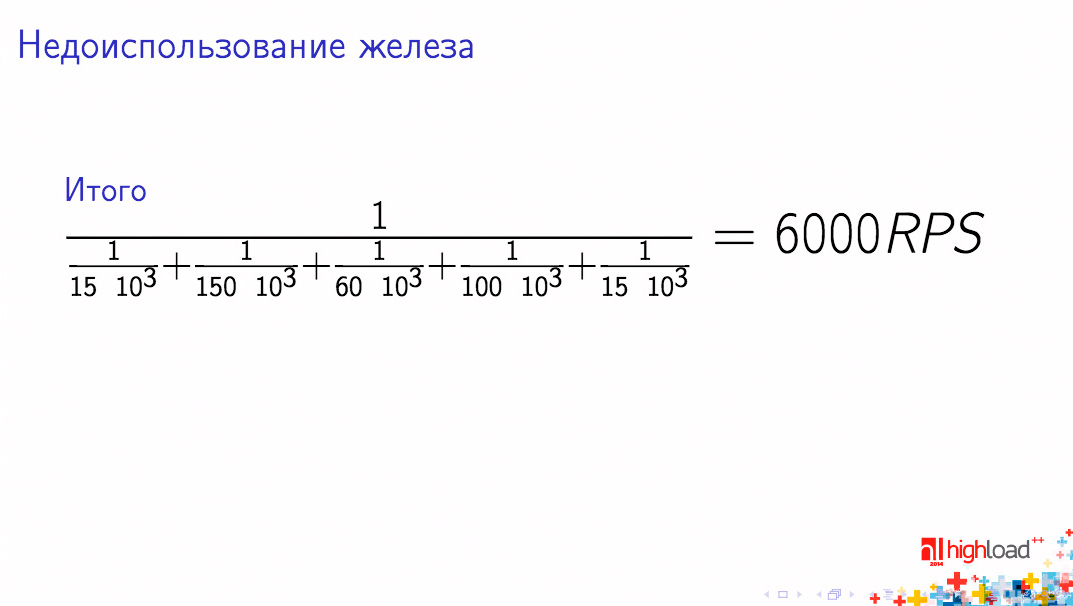
Мы взяли одну страничку веб-сервера, которая тормозит и которая была довольно популярна, провели измерения и получили следующие RPS:
- чтение запроса из сети – 15К RPS
- парсинг запроса, контроллер – 150К RPS/CPU
- запросы к хранилищу – 60К RPS
- формирование ответа – 100К RPS/CPU
- отправка ответа клиенту – 15К RPS
Если мы все эти цифры начинаем друг с другом складывать, то получается расчетная производительность нашего сервера 6000 RPS.
Но менеджеры продолжают бегать – проблемы-то при 150, что делать?
Начинаем смотреть на все бенчмарки, которые мы сделали. И видим – если хранилище придвинуть к серверу максимально близко, а еще клиента посадить прямо за сервер, то, вроде бы, становится хорошо.
Резюме ситуации таково: мы работали над сервером несколько лет вот в этой парадигме, программировали, а ее сейчас менять очень сложно, но мы видим, что все части нашего сервера работают с достаточной производительностью, которой еще на несколько лет вперед должно хватить.
Профайлинг
Стоить начать смотреть уже не на бенчмарки, а на профайл, т.е. на то, сколько времени какой процесс занимает.
В IT-мире все идут по такому пути, на котором открывают какие-то IT-закономерности и этим закономерностям в реальной жизни есть какая-то аналогия. Я предлагаю аналогию с обувным магазином – когда вы приходите в обувной магазин, то на вас сразу набрасывается менеджер, который с вами бегает туда-сюда, вы ходите, смотрите – вот эта обувь мне подходит/не подходит, он вам может сбегать на склад, принести и т.д.
Если сравнить списки слева и справа, то они очень похожи:

Если вернуться к серверу и перейти от бенчмарков к профайлу, выписать время каждого пункта, то у нас получатся следующие цифры:

Это реальные цифры, они просто округлены.
В итоге у нас после просмотра результатов профайлинга получится, что код наш выполнялся 17 мкс, а чего-то ждали – например, ответа от БД, сети и т.п. – 156 мкс. Возникает какой-то дисбаланс – наш код выполняется всего 10% времени, и при этом все тормозит, нагрузка – 30... что делать?
Когда все это проходили, написали вот такую потрясающую программу, которая имитирует высокую нагрузку:

Эта программа ничего не делает, кроме sleep-ов, т.е. на месте каждого действия у нас sleep на такое же количество мкс, как было замерено. Если, кстати, говорить о реализации usleep, то в linux, начиная с ядра 2.6, usleep реализован реальным усыплением процесса, т.е. до этой версии еще можно было предъявить претензии к реализации, то сейчас это реальная модель вашего веб-сервера.
Что же получилось? Эта замечательная программа спокойно очень грузит процессор где-то на 15%, при этом ничего не делает. Когда же мы запускаем таких "воркеров" примерно столько же, сколько в apache, то получаем ту же самую нагрузку на хосте, те же 20-30 единиц "out average".
Если вернуться к нашему серверу, то каждая отдельная часть имеет хорошую производительность, но что же нам делать? Раз каждый "кирпичик" удовлетворяет нас по скорости, то нам просто надо взять и пересобрать эти "кирпичики" в каком-то другом порядке, т.е. просто взять и реорганизовать код.
Событийно-ориентированное программирование
Переходим к событийно-ориентированному программированию, т.е. начинаем читать, что у нас происходит в мире, что люди думали по этому поводу и натыкаемся вот на такие вещи:

Очень хорошее высказывание, рекомендую над ним подумать. Компьютер – это конечный автомат, соответственно, когда компьютер реализует парадигму тредов, он сводит все к конечному автомату. И, если люди говорят, что нужно избавляться от тредов, надо от них избавляться. Ну, еще заодно и от процессов.
Если мы вернемся к аналогии с магазином, то очевидно, что если в магазин обуви придет сразу 100 покупателей, то никаких менеджеров не хватит, и надо будет что-то реорганизовывать. И в реальной жизни люди давно справились с задачей высокой нагрузки в магазинах, например, продуктовый магазин устроен совсем по-другому, чем обувной. Т.е., всех клиентов ставим в очереди, и продавец обслуживает всех без простоя. Надеюсь, эта аналогия всем понятна.
В IT-мире этот "продуктовый магазин" представляет собой так называемую машину событий – исполнитель заявляет о готовности выполнить задачу (как в McDonald's – "Свободная касса!"), как только "покупатель" подходит, его сразу обслуживают, а если ему нужно подождать, его ставят в другую очередь ожидающих чего-нибудь, например, со склада. В IT-мире реализация продуктового магазина сводится к тому, что исполнитель подписывается на то, что он выполнит задачу, т.е. регистрирует callback, а выполнение задачи – это, собственно, вызов callback-а и ожидание – это возврат машине событий управления путем возврата из callback-а.
Если мы возьмем не весь сервер, а просто для эксперимента перестроим проблемный веб-сервер на эту парадигму, то получится, что нам придется заменить следующие вещи: интерфейс веб-сервера, интерфейс БД и интерфейс с сетевыми вещами, если они есть.Мы увидим, что производительность нашего сервера выросла, как минимум, в 10 раз после такой реорганизации. Среднее время ответа тоже возросло. При этом одного процессора стало хватать на то, чтобы обслуживать нагрузку в 10 раз большую, чем раньше.
Проблемы, которые приходится решать, поскольку мы меняем парадигму программирования:
- сохранение контекста между callback
- ветвление
- обработка исключительных ситуаций
Самое критичное – это то, что во всех проектах обычно бизнес-логику строят около БД, т.е. выбрали данные, что-то посчитали или внутри БД или рядом с выборками и поэтому все эти условия типа "если клиент предпочитает зеленый цвет, то его направить туда, а если красный, то сюда" – они все около БД находятся и поэтому переписывать все запросы в БД на callback-е это практически приводит к тому, что 90% проекта будет переписано.
Но нам это не подходит и поэтому нужно попытаться объединить плюсы обувного магазина с плюсами продуктового. А в продуктовом магазине менеджер не простаивает. В нашем случае менеджер – это процессор.
Green threads
Если вы смотрели на ту потрясающую программу со sleep-ами, то я не коснулся того, почему она тормозила, но сейчас расскажу. Планировщик процессов в ОС – это вещь очень тяжелая. Во-первых, при каждом переключении процессора происходит переключение контекста очень тяжелого – процессы изолируются друг от друга, во-вторых, планировщик пытается синхронизировать эти переключения с частотой 1000Гц. И здесь проблемы есть по скорости. Соответственно, если мы возьмем плюсы планировщика и объединим их с плюсами event-машины, то мы как бы объединим обувной магазин с продуктовым. И для этого пишем свой планировщик. Эти планировщики люди часто называют fiber-ами или green tred-ами – во многих языках есть, я коснусь этого позже.
Основной API сводится к тому, что процесс можно создать и из процесса можно передать управление планировщику, а прервать процесс нельзя, потому что невытесняющая многозадачность. Т.е. мы отказываемся от всех "плюшек" процессов ОС в угоду быстродействию.
Теперь, если мы интегрируем планировщик с машиной событий, то получим примерно такую структуру кода на каждое событие:

т.е. мы подписываемся на событие и "усыпляем" текущий процесс, а событие будет – и процесс продолжается, т.о. программа становится такого же линейного вида, как она и была, т.е. запросили БД, сравнили результаты с каким-то эталоном и пошли по веткам влево или вправо – вернулись к почти традиционному виду программы.
Что у нас получается в веб-сервере? В него нам пришлось добавить машину событий, библиотеку fiber-ов, переписать все интерфейсы, на которых возникало ожидание чего-то – это, как правило, интерфейсы с веб-сервером, с БД и с сетью, если она есть.
Ну, и получается, что переписывание в такой парадигме сводится к тому, что мы пишем враппер над БД, враппер над веб-сервером и над сетевыми обращениями. В общем проекте получается, что переписывается всего около 5% кода.
Языки и технологии
Если говорить о библиотеках на языках, то на Perl просто прекрасная библиотека Coro – она реализует концепцию fiber-ов – легкого планировщика – плюс машина AnyEvent. На Python – fibers и twisted, а на PHP5.5 появился, наконец, оператор yield, fiber. Т.е. все эти парадигмы становятся доступны и php-программистам, но я пока в opensource-проектов, реализующих fiber-ы, не нашел.
Как только мы открыли для себя эту технологию, то сразу бросились все, что у нас тормозило, переписывать в такой парадигме. Доходило до смешного – люди простые циклы for i от 1 до 10 стали переписывать в асинхронной форме, т.е. в каждом цикле передавать управление планировщику – т.е. ничего, что мы 1 запрос от пользователя обрабатываем 5 секунд, но зато мы можем 10000 пользователей в секунду обработать!
Существуют framework-и, которые под эту парадигму программирования написаны. Например, Node JS – изначально асинхронный веб-framework, т.е. разработчики изначально думали об утилизации одного процессора по максимуму, но они отказались от парадигмы fiber-ов. Хотя, возможно, скоро они к ним придут.
Ну и, наш Tarantool. Он представляет собой сейчас полноценный application-сервер, который полностью реализует и предоставляет пользователю эту парадигму программирования, т.е. fiber-ы и event-машину. + "на борту" имеет неплохую БД в 2х ипостасях – БД в памяти и на диске. Кроме этого, серия библиотек, которая реализует неблокирующие сокеты, http-серверы, очереди и можно самим писать все, что хочется.
Общие недостатки этого подхода выясняются при попытке его повсеместного внедрения – на традиционных языках программирования этот подход позволяет утилизировать только один процессор, а нагрузка растет, и рано или поздно приходим к масштабированию – и по CPU и по хостам...
Уже давно существует язык Erlang, который позволяет все эти проблемы решить, однако имеет очень высокий порог вхождения, т.е. очень трудно объяснить программистам, что в языке программирования нет понятия "переменная", например.
Недавно появился Go – у него более низкий порог вхождения, потому что у него более традиционная парадигма программирования.
В свое время мы на этой парадигме программирования написали в свое время крупнейший бэкенд для Яндекс.Такси. У него сейчас примерно такая нагрузка – более 20000 водителей постоянно шлют свои координаты, более 1 млн. заявок в месяц, т.е. общее количество информации и трафика – большое. Проект реализован просто на Perl-овых скриптах (Coro+AnyEvent) и множество очередей (клиентов перед менеджерами) стоят на Tarantool-е, т.е. с помощью Tarantool-а реализуем очереди. И большое дисковое хранилище на PostgreSQL. Этот проект реализует у нас мобильное приложение клиента, водителя, диспетчера и т.д. и все это размещается всего на 2х серверах Hetzner-а, при этом один из них резервный.
Когда мы эту технологию освоили, все поняли, что мы очень крутые программисты.